video (1m) | video (10m) | website | paper
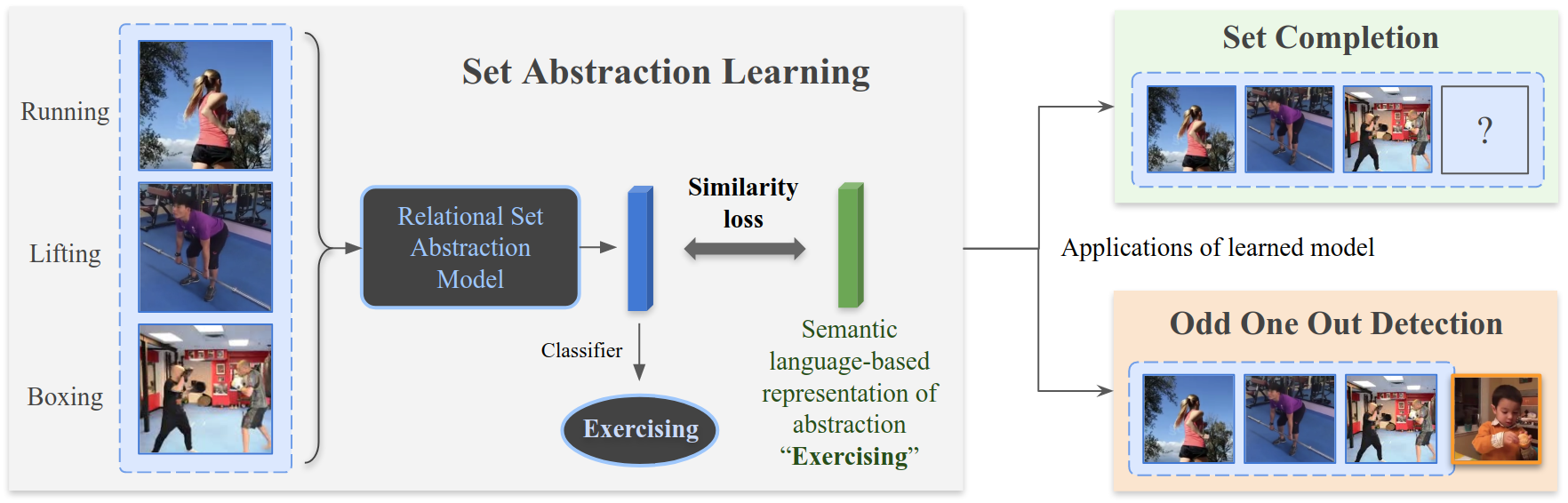
We provide a PyTorch implementation of our semantic relational set abstraction model presented in:
We Have So Much In Common: Modeling Semantic Relational Set Abstractions in Videos Alex Andonian*, Camilo Fosco*, Mathew Monfort, Allen Lee, Rogerio Feris, Carl Vondrick, Aude Oliva ECCV 2020
- Linux or macOS
- Python 3.6+
- CPU or NVIDIA GPU + CUDA CuDNN
Table of Contents:
- Clone this repo:
git clone https://github.com/alexandonian/relational-set-abstraction.git
cd relational-set-abstraction-
Create python virtual environment
-
Install a recent version of PyTorch and other dependencies specified below.
We highly recommend that you install additional dependencies in an isolated python virtual environment (of your choosing). For Conda+pip users, you can create a new conda environment and then pip install dependencies with the following snippet:
ENV_NAME=set-abstraction
conda create --name $ENV_NAME python=3.7
conda activate $ENV_NAME
pip install -r requirements.txtAlternatively, you can create a new Conda environment in one command using conda env create -f environment.yml, followed by conda activate set-abstraction to activate the environment.
Raw videos: If you would like to train set abstraction models from scratch, you will need to download and prepare large scale video datasets such as those investigated in the paper:
- Kinetics400 contains ~240k training videos and ~19k validation videos.
- Multi-Moments in Time contains ~1M+ training videos and 10k validation videos.
Please visit their respective websites in order to gain access to the raw videos and preprocessing instructions.
Using cached features: Due to the size and scale of these datasets, some researchers may find that finetuning just the set abstraction module on cached features extracted from a pretained visual backbone lowers the barrier to entry by reducing the computational demands of the pipeline. In order to accomodate these people, we release cached 3D ResNet50 features for both datasets (see below for more details). Since we have found that these features can be used without degredation to accuracy in downstream tasks, this is the primary mode of operation supported in the current release.
The semantic relational set abstraction pipeline requires additional metadata for training and evaluation. This metadata includes:
abstraction_sets: json files specifying sets of video filenames and the corresponding powerset of their abstraction labels.embeddings: PyTorch.pthfiles containing a 300 dimensional semantic embedding for each video, which are generated via the procedure described in section 3 of the paper.category_embeddings: PyTorch.pthfiles containing a 300 dimensional semantic embedding for each category/node in the semantic relational graph.features: Cached visual features for each video from a pretrained 3D ResNet50 backbone CNN.graph: json files specifying the semantic relational graph in a format compatible with the NetworkX python package.listfile: text files specifying the number of frames and the original class label for each video.pretrained_model: pretrained set abstraction module weights to be used for immediate evaluation.
We provide a simple python utility script for downloading the metadata described above. Note: The script assumes that the popular wget program is installed on your machine and available via system calls. Detailed usage information is shown below:
python scripts/download_data.py --help
usage: download_data.py [-h]
[--datasets {moments,kinetics} [{moments,kinetics} ...]]
[--datatypes {abstraction_sets,embeddings,category_embeddings,features,graph,listfile,pretrained_model}]
[--splits {train,val,test} [{train,val,test} ...]]
[--data_dir DATA_DIR] [--overwrite]
Set Abstraction Metadata Download Utility.
optional arguments:
-h, --help show this help message and exit
--datasets {moments,kinetics} [{moments,kinetics} ...]
list of datasets for which to download metadata.
(default: ['moments', 'kinetics'])
--datatypes {abstraction_sets,embeddings,category_embeddings,features,graph,listfile,pretrained_model}
list of metadata types to download.
(default: ['abstraction_sets', 'embeddings', 'category_embeddings', 'features', 'graph', 'listfile', 'pretrained_model'])
--splits {train,val,test} [{train,val,test} ...]
list of splits for which to download metadata
(default: ['train', 'val', 'test'])
--data_dir DATA_DIR directory to save downloaded data (default: metadata)
--overwrite overwrite current data if it exists
By default, python scripts/download_data.py will attempt to download all of the released metadata for both datasets. Using the provided flags, it is possible to download only the subsets of data needed to run a particular part of the pipeline. For example, specifying --datasets moments will download only metadata for training and evaluation on the Moments dataset. Including --splits val test would further restrict the download to evaluation related metadata only.
Evaluation of trained set abstraction models can be carried out via test.py with the following command:
DATASET="moments"
CHECKPOINT="metadata/AbstractionEmbedding_${DATASET}_SAM_1-2-3-4_best.pth.tar"
python test.py \
--experiment AbstractionEmbedding --dataset $DATASET \
--model AbstractionEmbeddingModule --resume $CHECKPOINTwhere $DATASET is either kinetics or moments, and $CHECKPOINT is a path pointing to a corresponding pretrained checkpoint, which has the format shown above by default. In addition to being logged to the terminal, the evaluation results will be stored in
logs/AbstractionEmbedding/AbstractionEmbeddingModule/AbstractionEmbedding_<DATASET>_SAM_1-2-3-4_summary.txt
Training set abstraction models can be accomplished in a similar fashion via train.py. A host of configuration options and hyperparameters can be inspected and modified in cfg.py. As above, in addition to specifying the dataset, it is important to also specify the experiment class name as well as the model class name.
DATASET="kinetics"
python train.py \
--exp_id RUN1 --experiment AbstractionEmbedding --dataset $DATASET \
--model AbstractionEmbeddingModuleA checkpoint name is automatically generated based on the particular configuration. You may also specify a specific experiment id exp_id to help uniquely identify several runs under the same configuration.
Logs are automatically stored in:
logs/<experiment>/<model>/<checkpoint_name>.txt # Full training log
logs/<experiment>/<model>/<checkpoint_name>_val.txt # Validation only log
logs/<experiment>/<model>/<checkpoint_name>_eval.txt # Eval log generated by test.py
logs/<experiment>/<model>/<checkpoint_name>_summary.txt # Summary metrics generated during evaluation
Checkpoints are stored in a similar manner:
checkpoints/<experiment>/<model>/<checkpoint_name>_checkpoint.pth.tar # Current checkpoint (overwritten ever epoch)
checkpoints/<experiment>/<model>/<checkpoint_name>_best.pth.tar # Best checkpoint according to some metric
checkpoints/<experiment>/<model>/<checkpoint_name>_epoch_<N>.pth.tar # N-th checkpoint saved at given frequency
If you use this code for your research, please cite our paper.
@article{andonian2020we,
title={We Have So Much In Common: Modeling Semantic Relational Set Abstractions in Videos},
author={Andonian, Alex and Fosco, Camilo and Monfort, Mathew and Lee, Allen and Feris, Rogerio and Vondrick, Carl and Oliva, Aude},
journal={arXiv preprint arXiv:2008.05596},
year={2020}
}We thank Bolei Zhou for immensely helpful discussion and feedback. Our code is based on TRN-pytorch.