The material in this repo contains workshop materials related to running deep learning applications in HPC system.
It is important to optimize your script for the single-GPU case before moving to multi-GPU training. This is because as you request more resources, your queue time increases. We also want to avoid wasting resources by running code that is not optimized.
Here we train a CNN on the MNIST dataset using a single GPU as an example. We profile the code and make performance improvements.
First login to CARC OnDemand: https://ondemand.carc.usc.edu/ and request a 'Discovery Cluster Shell Access' within OpenOnDemand.
We will use Conda to build software packages. If it is the first time you are using Conda, make sure you follow the guide of how to use Conda with this link: https://www.carc.usc.edu/user-guides/data-science/building-conda-environment
salloc --partition=gpu --gres=gpu:1 --cpus-per-task=8 --mem=32GB --time=1:00:00 #Request an interative session to install packages within Conda environment.module purge
module load conda
mamba init bash
source ~/.bashrc
module purge
mamba create --name torch-env
mamba activate torch-env
mamba install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
mamba install line_profiler --channel conda-forge
When you finish the installtion, type 'exit' to exit from the interactive session.
module load gcc/11.3.0
module load git
git clone https://github.com/uschpc/Running-DL-Applications.git
cd Running-DL-ApplicationsFirst, inspect the script (see script) by running these commands:
$ cat mnist_classify.pyNote: nn.Conv2d(1, 32, 3, 1): This is creating a 2D convolutional layer. Here’s a breakdown of the arguments:
(a) 1: The number of input channels. This could be 1 for a grayscale image, 3 for a color image (RGB), etc.
(b) 32: The number of output channels (i.e., the number of filters or kernels). This means that the output of this convolutional layer will have 32 feature maps.
(c) 3: The size of the convolutional kernel (or filter). This means a 3x3 filter is used for the convolution.
(d) 1: The stride of the convolution, which controls how the filter moves across the input. A stride of 1 means the filter moves one pixel at a time.
We will profile the train function using line_profiler (see line 39) by adding the following decorator:
$ module load nano
@profile
def train(args, model, device, train_loader, optimizer, epoch):Below is the Slurm script:
#!/bin/bash
#SBATCH --job-name=mnist # create a short name for your job
#SBATCH --partition=gpu # gpu partition
#SBATCH --nodes=1 # node count
#SBATCH --ntasks=1 # total number of tasks across all nodes
#SBATCH --cpus-per-task=1 # cpu-cores per task (>1 if multi-threaded tasks)
#SBATCH --mem=8G # total memory per node (4 GB per cpu-core is default)
#SBATCH --gres=gpu:1 # number of gpus per node
#SBATCH --time=00:05:00 # total run time limit (HH:MM:SS)
# which gpu node was used
echo "Running on host" $(hostname)
# print the slurm environment variables sorted by name
printenv | grep -i slurm | sort
module purge
eval "$(conda shell.bash hook)"
conda activate torch-env
kernprof -o ${SLURM_JOBID}.lprof -l mnist_classify.py --epochs=3kernprof is a profiler that wraps Python.
Finally, submit the job while specifying the reservation:
$ sbatch job.slurmYou should find that the code runs in about 20-80 seconds with 1 CPU-core depending on which GPU node was used:
$ seff 24752610
Job ID: 24752610
Cluster: discovery
User/Group: haoji/haoji
State: COMPLETED (exit code 0)
Cores: 1
CPU Utilized: 00:00:53
CPU Efficiency: 94.64% of 00:00:56 core-walltime
Job Wall-clock time: 00:00:56
Memory Utilized: 1.31 GB
Memory Efficiency: 16.43% of 8.00 GB
You can also check slurm-#######.out file.
We installed line_profiler into the Conda environment and profiled the code. To analyze the profiling data:
$ python -m line_profiler -rmt *.lprof
Timer unit: 1e-06 s
Total time: 30.8937 s
File: mnist_classify.py
Function: train at line 39
Line # Hits Time Per Hit % Time Line Contents
==============================================================
39 @profile
40 def train(args, model, device, train_loader, optimizer, epoch):
41 3 213.1 71.0 0.0 model.train()
42 2817 26106124.7 9267.3 84.5 for batch_idx, (data, target) in enumerate(train_loader):
43 2814 286242.0 101.7 0.9 data, target = data.to(device), target.to(device)
44 2814 296440.2 105.3 1.0 optimizer.zero_grad()
45 2814 1189206.1 422.6 3.8 output = model(data)
46 2814 81578.6 29.0 0.3 loss = F.nll_loss(output, target)
47 2814 1979990.2 703.6 6.4 loss.backward()
48 2814 841861.9 299.2 2.7 optimizer.step()
49 2814 2095.3 0.7 0.0 if batch_idx % args.log_interval == 0:
50 564 1852.9 3.3 0.0 print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
51 282 2218.6 7.9 0.0 epoch, batch_idx * len(data), len(train_loader.dataset),
52 282 105753.3 375.0 0.3 100. * batch_idx / len(train_loader), loss.item()))
53 282 119.2 0.4 0.0 if args.dry_run:
54 break
30.89 seconds - mnist_classify.py:39 - train
The slowest line is number 42 which consumes 84.5% of the time in the training function. That line involves train_loader which is the data loader for the training set. Are you surprised that the data loader is the slowest step and not the forward pass or calculation of the gradients? Can we improve on this?
You can check gpu utilization using "watch -n 1 nvidia-smi" command. To exit watch session, use Ctrl + C.
Make sure you optimize the single GPU case before going to multiple GPUs by working through the Performance Tuning Guide.
One technique that was discussed in the Performance Tuning Guide was using multiple CPU-cores to speed-up ETL. Let's put this into practice.
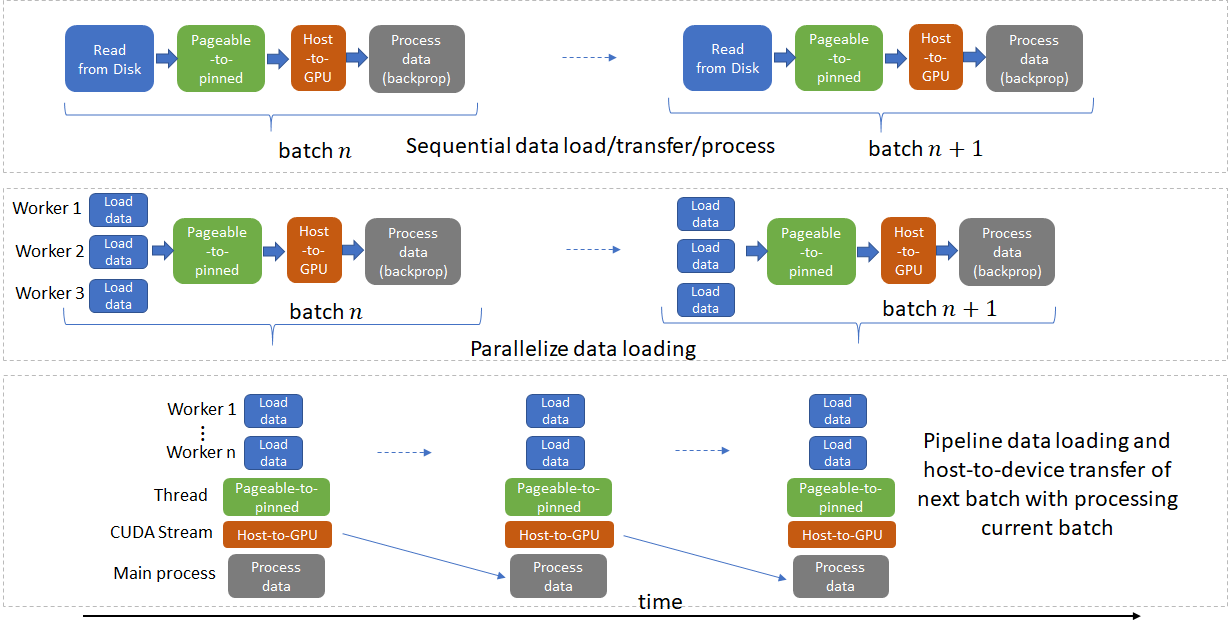
Credit for image above is here.
In mnist_classify.py, change num_workers from 1 to 8. And then in job.slurm change --cpus-per-task from 1 to 8. Then run the script again and note the speed-up:
(torch-env) $ sbatch job.slurm
It is essential to optimize your code before going to multi-GPU training since the inefficiencies will only be magnified otherwise. The more GPUs you request in a Slurm job, the longer you will wait for the job to run. If you can get your work done using an optimized script running on a single GPU then proceed that way. Do not use multiple GPUs if your GPU efficiency is low.