This project is an implementation of a popular paper BitNet from Microsoft BitNet 1.58 bits.
The paper introduces a novel technique called BitLinear, which utilizes binary weights in the linear layer.
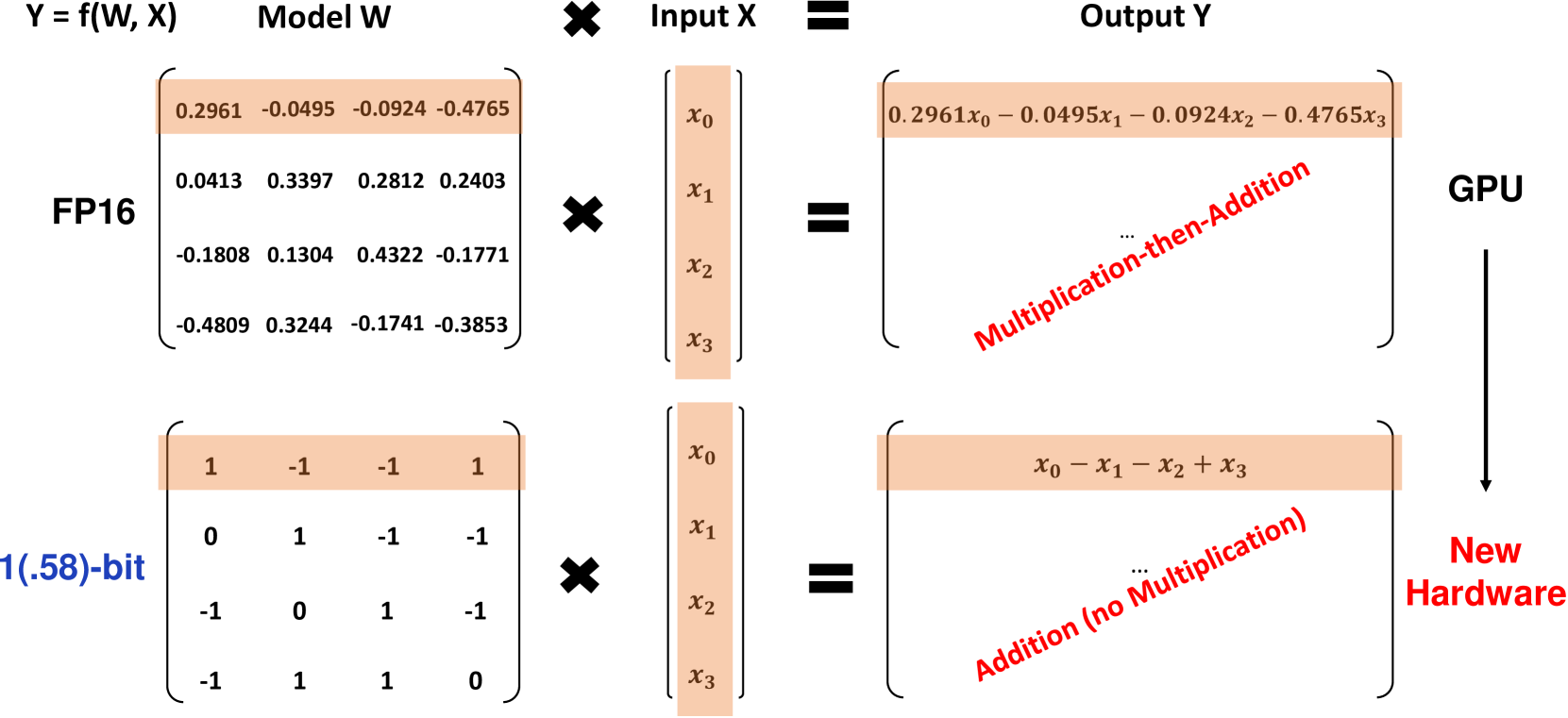

The implemention the BitLinear layer should then be compared to a regular implementation.
This implementation also uses the paper's logic where multiplication should be replaced by (signed) summation, to speed up inference.
The repository is organized as follows:
src/: Contains the source code for the BitNet implementation.test/: Includes notebooks or scripts for running experiments and comparing results.
The implementation starts with the BitLinear layer, which replaces the traditional linear layer in the neural network architecture. Detailed explanations and code snippets are provided in the src/ directory and testing in src/
This repo's aim is to implement a whole Transformer using BitLinear's logic and comparing it side by side to a regular floating point Transformer.
To evaluate the performance of BitNet, it's compared it to a regular implementation of the Transformer architecture. Experiments are conducted on various datasets and measure metrics such as accuracy, training time, and memory usage. The results and analysis can be found in the experiments/ directory.
Excerpt from test.ipynb
This is a test to see the binary optimization in comparison with floating point
from torch import optim
#now let's optimize the binary layer
bitlayer = BitLinear(100, 10)
#train the model to output the same input
train_loss = []
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(bitlayer.parameters(), lr=0.001)
for i in range(1000):
input = torch.randn(100)
output = bitlayer(input)
loss = criterion(output, input)
loss.backward()
optimizer.step()
optimizer.zero_grad()
train_loss.append(loss.item())
