Understanding The Sample Tables: An Example
This discussion applies to the case where the mp4 file is self-contained, and has an 'mdat' box containing the media data and a 'moov' box containing the metadata that references the media data.
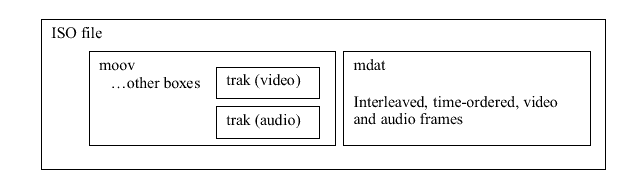
(diagram from ISO/IEC 14496-12 – MPEG-4 Part 12)
Annex A. of ISO/IEC 14496-12 – MPEG-4 Part 12 contains a description of how the media data is laid out within the file as an interleaved set of samples and how the sample table box container (stbl) contains a set of tables that are used to identify the position of individual samples within the file.
The text of the standard document is perfectly well written, but it greatly helps to understand the relationship between the different tables (stco, stsz, stsc etc.) through a worked example with real numerical data. Hence why I've written this page.
First of all some definitions from the standard:
- chunk: contiguous set of samples for one track
- sample: all the data associated with a single timestamp
It is quite possible (and reasonably common) that a chunk only contains one sample, but it seems to be usual for a chunk to contain n-samples where n is a single or double-digit number.
The data for the example comes from a real file that has two tracks (track 1 is a audio track, track 2 is video track) and an mdat section located at 121915 bytes from the start of the file. The file I used was a actually a test file hevcds_1080p60_Main10_8M.mp4 from GPAC.
Each track has an stbl container and hence it's own set of sample tables.
Gives a byte offset for each chunk from the start of the file.
for track 1 the start of the table looks like this:
Has header:
{"size": 1312, "type": "stco"}
Has values:
{
"version": 0,
"flags": "0x000000",
"entry_count": 324,
"entry_list": [
{ "chunk_offset": 121923 } ,
{ "chunk_offset": 897412 } ,
{ "chunk_offset": 1170432 } ,
{ "chunk_offset": 1426814 } ,
and for track 2 the start of the table looks like this:
Has header:
{"size": 1224, "type": "stco"}
Has values:
{
"version": 0,
"flags": "0x000000",
"entry_count": 302,
"entry_list": [
{ "chunk_offset": 130635 },
{ "chunk_offset": 904603 },
{ "chunk_offset": 1177851 },
{ "chunk_offset": 1434346 },
So the first chunk of track 1 (byte offset 121923) starts immediately after the 8 bytes of the mdat header and is followed by the first chunk of track 2 which in turn is followed by the second chunk of track 1 and so on.
Track 1 comprises 324 chunks and track 2 302 chunks so the chunks are not completely interleaved between tracks and some track 1 chunks are adjacent to other track 1 chunks
This table is used to work out how many samples a a given chunk contains.
for track 1 the table looks like this:
Has header:
{"size": 52, "type": "stsc"}
Has values:
{ "version": 0,
"flags": "0x000000",
"entry_count": 3,
"entry_list": [
{ "first_chunk": 1,
"samples_per_chunk": 12,
"samples_description_index": 1 } ,
{ "first_chunk": 2,
"samples_per_chunk": 11,
"samples_description_index": 1 } ,
{ "first_chunk": 324,
"samples_per_chunk": 5,
"samples_description_index": 1 }
]
}
and for track 2 the start of the table looks like this:
Has header:
{"size": 1180, "type": "stsc"}
Has values:
{
"version": 0,
"flags": "0x000000",
"entry_count": 97,
"entry_list": [
{ "first_chunk": 1,
"samples_per_chunk": 31,
"samples_description_index": 1 },
{ "first_chunk": 2,
"samples_per_chunk": 30,
"samples_description_index": 1 },
{ "first_chunk": 17,
"samples_per_chunk": 29,
"samples_description_index": 1 },
{ "first_chunk": 18,
"samples_per_chunk": 28,
"samples_description_index": 1 },
From this we ascertain that track 1/chunk 1 contains 12 contiguous samples, track 1/chunk 2 contains 11 samples and all other track 1 chunks will contain 5 samples each.
For track 2, track 2/chunk 1 will contain 31 contiguous samples, track 2/chunk 2 will contain 30 samples (as will chunks 3 through to 16), track 2/chunk 17 will contain 29 samples, track 2/chunk 18 will contain 28 samples and so on.
This table states (in bytes) how large each individual sample within a given track is.
for track 1 the start of the table looks like this:
Has header:
{"size": 14256, "type": "stsz"}
Has values:
{
"version": 0,
"flags": "0x000000",
"sample_size": 0,
"sample_count": 3559,
"entry_list": [
{ "entry_size": 682 } ,
{ "entry_size": 683 } ,
{ "entry_size": 682 } ,
{ "entry_size": 683 } ,
{ "entry_size": 683 } ,
{ "entry_size": 682 } ,
{ "entry_size": 683 } ,
{ "entry_size": 886 } ,
{ "entry_size": 862 } ,
{ "entry_size": 786 } ,
{ "entry_size": 702 } ,
{ "entry_size": 698 } ,
{ "entry_size": 684 } ,
{ "entry_size": 713 } ,
{ "entry_size": 661 } ,
{ "entry_size": 638 } ,
{ "entry_size": 653 } ,
{ "entry_size": 640 } ,
{ "entry_size": 687 } ,
{ "entry_size": 633 } ,
{ "entry_size": 614 } ,
{ "entry_size": 619 } ,
{ "entry_size": 649 } ,
{ "entry_size": 663 } ,
{ "entry_size": 696 } ,
{ "entry_size": 675 } ,
{ "entry_size": 664 } ,
{ "entry_size": 654 } ,
{ "entry_size": 647 } ,
{ "entry_size": 651 } ,
{ "entry_size": 690 } ,
{ "entry_size": 739 } ,
{ "entry_size": 686 } ,
{ "entry_size": 654 } ,
{ "entry_size": 664 } ,
{ "entry_size": 677 } ,
{ "entry_size": 684 } ,
{ "entry_size": 686 } ,
{ "entry_size": 730 } ,
{ "entry_size": 665 } ,
{ "entry_size": 665 } ,
{ "entry_size": 655 } ,
{ "entry_size": 694 } ,
{ "entry_size": 697 } ,
{ "entry_size": 715 } ,
{ "entry_size": 669 } ,
{ "entry_size": 667 } ,
and for track 2 the start of the table looks like this:
Has header:
{"size": 34160, "type": "stsz"}
Has values:
{ "version": 0,
"flags": "0x000000",
"sample_size": 0,
"sample_count": 8535,
"entry_list": [
{ "entry_size": 532641 },
{ "entry_size": 53341 },
{ "entry_size": 14903 },
{ "entry_size": 6930 },
{ "entry_size": 1965 },
{ "entry_size": 384 },
{ "entry_size": 405 },
{ "entry_size": 2383 },
{ "entry_size": 433 },
{ "entry_size": 522 },
{ "entry_size": 9499 },
{ "entry_size": 2297 },
{ "entry_size": 415 },
{ "entry_size": 466 },
{ "entry_size": 3349 },
{ "entry_size": 506 },
{ "entry_size": 557 },
{ "entry_size": 86826 },
{ "entry_size": 18558 },
{ "entry_size": 8331 },
{ "entry_size": 2051 },
{ "entry_size": 420 },
{ "entry_size": 515 },
{ "entry_size": 2484 },
{ "entry_size": 403 },
{ "entry_size": 423 },
{ "entry_size": 9043 },
{ "entry_size": 2859 },
{ "entry_size": 368 },
{ "entry_size": 429 },
{ "entry_size": 3071 },
{ "entry_size": 360 },
{ "entry_size": 443 },
{ "entry_size": 83602 },
{ "entry_size": 17848 },
{ "entry_size": 8262 },
{ "entry_size": 1783 },
{ "entry_size": 405 },
{ "entry_size": 393 },
{ "entry_size": 2476 },
{ "entry_size": 435 },
{ "entry_size": 453 },
{ "entry_size": 8338 },
{ "entry_size": 2303 },
{ "entry_size": 423 },
{ "entry_size": 384 },
{ "entry_size": 2728 },
{ "entry_size": 403 },
{ "entry_size": 437 },
{ "entry_size": 88092 },
{ "entry_size": 18975 },
{ "entry_size": 9010 },
{ "entry_size": 2161 },
{ "entry_size": 368 },
{ "entry_size": 451 },
{ "entry_size": 2766 },
{ "entry_size": 480 },
{ "entry_size": 425 },
{ "entry_size": 8764 },
{ "entry_size": 2417 },
{ "entry_size": 444 },
{ "entry_size": 602 },
{ "entry_size": 2245 },
{ "entry_size": 512 },
{ "entry_size": 417 },
{ "entry_size": 78171 },
{ "entry_size": 17933 },
{ "entry_size": 7793 },
{ "entry_size": 1995 },
{ "entry_size": 371 },
{ "entry_size": 413 },
{ "entry_size": 2758 },
{ "entry_size": 431 },
{ "entry_size": 414 },
{ "entry_size": 8474 },
Track 1 seems to be completely made up of small samples all of which are roughly the same size at around 600-700 bytes or so. Track 2 on the other hand, has a much greater variability in the size in bytes of each sample. If you have any knowledge of MPEG video codecs (in this case it is actually HEVC) you can probably figure out why, namely I, B and P frames have different compression efficiency. You can probably guess the GOP structure as well.
From the stco and the stsc we know the first 12 samples of track 1 will be found consecutively in chunk 1 starting at byte position 121923 from the start of the file.
With regard to random access into an AV presentation, an end consumer of the presentation is unlikely to express a desire to see the the 3000th sample of a presentation, much more likely the requirement would be to seek 100 seconds from the start. The stts maps samples to time.
for track 1 the table looks like this:
Has header:
{"size": 24, "type": "stts"}
Has values:
{
"version": 0,
"flags": "0x000000",
"entry_count": 1,
"entry_list": [
{
"sample_count": 3559,
"sample_delta": 1024
}
]
}
and for track 2 the table looks like this:
Has header:
{"size": 24, "type": "stts"}
Has values:
{
"version": 0,
"flags": "0x000000",
"entry_count": 1,
"entry_list": [
{
"sample_count": 8535,
"sample_delta": 1
}
]
}
Both tables have exactly one entry. This means that all the samples for each track have the same duration. The standard does allow for multiple entries in the stts table, but I don't recall ever seeing more than one.
The standard states 'The Decoding Time to Sample Box contains decode time delta's: DT(n+1) = DT(n) + STTS(n) where STTS(n) is the (uncompressed) table entry for sample n.' i.e. the decode time of a given sample is the accumulated time deltas of all preceding samples in the track.
What units are the sample deltas measured in? We find this by looking at the timescale value defined in the media header box, mdhd of the track.
for track 1 the timescale value is 24000 indicating units of 1/24000th of a second so the duration of all samples in track 1 is 1024/24000th of a second.
for track 2 the timescale value is 60 indicating units of 1/60th of a second so the duration of all samples in track 2 is 1/60th of a second (considering track 2 is a video track recorded at 60 fps this is not a surprising result.)
From the above we can determine the byte and time offsets for the first few chunks and samples within the mdat.
| track/chunk id (from tkhd and stco) | chunk offset(from stco) | samples per chunk (from stsc) | sample size (from stsz) | sample offset (combining data from stco, stsc and stsz) | sample time delta (from stts) | sample time from start in seconds (combining stts with timescale from mdhd) |
|---|---|---|---|---|---|---|
| 1/1 | 121923 | 12 | 682 | 121923 | 1024 | 0.00 |
| 683 | 122605 | 1024 | 0.04 | |||
| 682 | 123288 | 1024 | 0.09 | |||
| 683 | 123970 | 1024 | 0.13 | |||
| 683 | 124653 | 1024 | 0.17 | |||
| 682 | 125336 | 1024 | 0.21 | |||
| 683 | 126018 | 1024 | 0.26 | |||
| 886 | 126701 | 1024 | 0.30 | |||
| 862 | 127587 | 1024 | 0.34 | |||
| 786 | 128449 | 1024 | 0.38 | |||
| 702 | 129235 | 1024 | 0.43 | |||
| 698 | 129937 | 1024 | 0.47 | |||
| 2/1 | 130635 | 31 | 532641 | 130635 | 1 | 0.00 |
| 53341 | 663276 | 1 | 0.02 | |||
| 14903 | 716617 | 1 | 0.03 | |||
| 6930 | 731520 | 1 | 0.05 | |||
| 1965 | 738450 | 1 | 0.07 | |||
| 384 | 740415 | 1 | 0.08 | |||
| 405 | 740799 | 1 | 0.10 | |||
| 2383 | 741204 | 1 | 0.12 | |||
| 433 | 743587 | 1 | 0.13 | |||
| 522 | 744020 | 1 | 0.15 | |||
| 9499 | 744542 | 1 | 0.17 | |||
| 2297 | 754041 | 1 | 0.18 | |||
| 415 | 756338 | 1 | 0.20 | |||
| 466 | 756753 | 1 | 0.22 | |||
| 3349 | 757219 | 1 | 0.23 | |||
| 506 | 760568 | 1 | 0.25 | |||
| 557 | 761074 | 1 | 0.27 | |||
| 86826 | 761631 | 1 | 0.28 | |||
| 18558 | 848457 | 1 | 0.30 | |||
| 8331 | 867015 | 1 | 0.32 | |||
| 2051 | 875346 | 1 | 0.33 | |||
| 420 | 877397 | 1 | 0.35 | |||
| 515 | 877817 | 1 | 0.37 | |||
| 2484 | 878332 | 1 | 0.38 | |||
| 403 | 880816 | 1 | 0.40 | |||
| 423 | 881219 | 1 | 0.42 | |||
| 9043 | 881642 | 1 | 0.43 | |||
| 2859 | 890685 | 1 | 0.45 | |||
| 368 | 893544 | 1 | 0.47 | |||
| 429 | 893912 | 1 | 0.48 | |||
| 3071 | 894341 | 1 | 0.50 | |||
| 1/2 | 897412 | 11 | 684 | 897412 | 1024 | 0.51 |
| 713 | 898096 | 1024 | 0.55 | |||
| 661 | 898809 | 1024 | 0.60 | |||
| 638 | 899470 | 1024 | 0.64 | |||
| 653 | 900108 | 1024 | 0.68 | |||
| 640 | 900761 | 1024 | 0.73 | |||
| 687 | 901401 | 1024 | 0.77 | |||
| 633 | 902088 | 1024 | 0.81 | |||
| 614 | 902721 | 1024 | 0.85 | |||
| 619 | 903335 | 1024 | 0.90 | |||
| 649 | 903954 | 1024 | 0.94 | |||
| 2/2 | 904603 | 30 | 360 | 904603 | 1 | 0.52 |
| 443 | 904963 | 1 | 0.53 | |||
| 83602 | 905406 | 1 | 0.55 | |||
| 17848 | 989008 | 1 | 0.57 | |||
| 8262 | 1006856 | 1 | 0.58 | |||
| 1783 | 1015118 | 1 | 0.60 | |||
| 405 | 1016901 | 1 | 0.62 | |||
| 393 | 1017306 | 1 | 0.63 | |||
| 2476 | 1017699 | 1 | 0.65 | |||
| 435 | 1020175 | 1 | 0.67 | |||
| 453 | 1020610 | 1 | 0.68 | |||
| 8338 | 1021063 | 1 | 0.70 | |||
| 2303 | 1029401 | 1 | 0.72 | |||
| 423 | 1031704 | 1 | 0.73 | |||
| 384 | 1032127 | 1 | 0.75 | |||
| 2728 | 1032511 | 1 | 0.77 | |||
| 403 | 1035239 | 1 | 0.78 | |||
| 437 | 1035642 | 1 | 0.80 | |||
| 88092 | 1036079 | 1 | 0.82 | |||
| 18975 | 1124171 | 1 | 0.83 | |||
| 9010 | 1143146 | 1 | 0.85 | |||
| 2161 | 1152156 | 1 | 0.87 | |||
| 368 | 1154317 | 1 | 0.88 | |||
| 451 | 1154685 | 1 | 0.90 | |||
| 2766 | 1155136 | 1 | 0.92 | |||
| 480 | 1157902 | 1 | 0.93 | |||
| 425 | 1158382 | 1 | 0.95 | |||
| 8764 | 1158807 | 1 | 0.97 | |||
| 2417 | 1167571 | 1 | 0.98 | |||
| 444 | 1169988 | 1 | 1.00 |