Original PIMS Documentation
In August 2024, the original build of PIMS, which used React, .NET, and MS SQL Server, was replaced.
To view the code at the time before its removal, visit the commit 3afc60ae182414a40201fcd8632a9ed83e3df368.
e.g. git checkout 3afc60ae182414a40201fcd8632a9ed83e3df368
You can also view this repo at tag v3.0.0.
For the purposes of clarity, this version of PIMS will be referred to as Old PIMS.
The modern version will be referred to as New PIMS.
This page contains the relevant documentation needed to understand the processes that maintained this original build. It also includes instructions on how to set up a local instance.
Presently there is no built in process for transferring all properties from one agency to another.
Manually a user with the SRES role (which includes the admin-properties claim) can modify each properties owning agency, but obviously with a bulk change this would take too much time.
The most efficient method is to create a database migration.
To do this follow these steps.
If you are using a Windows OS, you can use the make scripts in the root of the solution.
Generate a new database migration for the next appropriate version (i.e. 01.09.01).
make db-add n={version number}Add the appropriate folders for this migration to place your SQL scripts.
mkdir backend/dal/Migrations/{version number}/Up/PostUp
mkdir backend/dal/Migrations/{version number}/Down/PostDownAdd your SQL scripts for Up (upgrade) and Down (rollback). The Up script will transfer all properties from the current agency to the appropriate agency. The Down scripts will rollback your change and move the properties back to the original agency (if appropriate).
touch backend/dal/Migrations/{version number}/Up/PostUp/01-PropertyTransfer.sql
touch backend/dal/Migrations/{version number}/Down/PostDown/01-PropertyTransfer.sqlUpdate the Up script to contain the following.
Determine the original Agency Code and the Agency Code that the properties will be transferred to.
Ideally there would be no open projects, however if there are you will need to transfer these to the new agency as well.
declare @fromAgencyId int = (select [Id] from dbo.[Agencies] where [Code] = '{current Agency Code}')
declare @toAgencyId int = (select [Id] from dbo.[Agencies] where [Code] = '{To Agency Code}')
-- Transfer parcels to new agency.
update dbo.[Parcels]
set [AgencyId] = @toAgencyId
where [AgencyId] = @fromAgencyId
-- Transfer buildings to new agency.
update dbo.[Buildings]
set [AgencyId] = @toAgencyId
where [AgencyId] = @fromAgencyIdThe rollback script is simply an inverse. Only add a rollback if the state of the solution must return to what it was before the update.
declare @fromAgencyId int = (select [Id] from dbo.[Agencies] where [Code] = '{current Agency Code}')
declare @toAgencyId int = (select [Id] from dbo.[Agencies] where [Code] = '{original Agency Code}')
-- Transfer parcels to original agency.
update dbo.[Parcels]
set [AgencyId] = @toAgencyId
where [AgencyId] = @fromAgencyId
-- Transfer buildings to original agency.
update dbo.[Buildings]
set [AgencyId] = @toAgencyId
where [AgencyId] = @fromAgencyIdThe API uses a Entity Framework Core as the ORM to communicate with the data-source. Currently it is configured and coded to use an MS-SQL database.
When the API starts it will attempt to setup and configure the database based on the connection string set above, if the environment is not Production (i.e. Development).
It is possible with some changes to use a different type of database.
Refer to the CLI documentation here.
The database is setup and configured through Entity Framework Code-First processes. To use the Entity Framework CLI you will need to:
-
Install the .NET SDK version (download links below),
-
Install dotnet-ef tool and,
-
Optionally, add a
connectionstrings.jsonconfiguration file in the/backend/dalfolder -
Optionally, the connection string can be provided in a
.envfile in the same folder with the format:ConnectionStrings__PIMS=Server=<localhost or host.docker.internal>,<port>;User ID=sa;Database=<database name>
NOTES
- All
dotnet efcommands must be run from the/backend/daldirectory. - Please do not commit the
connectionstrings.jsonfile to source code. It is likely to contain secret information that should not be shared. By default.gitignorewill exclude it. - To help
dotnet effind the correct database connection, you will need to select one of the following configuration options, but no single one is required:- connectionstrings.json
-
connectionstrings.
Environment.json. For example, connectionstrings.Development.json - .env file
- Environment variables
dotnet tool install --global dotnet-efYou may create a connectionstrings.json configuration file within the /backend/dal project, or a .env file to contain this information. You can also create one for each environment by creating a file with the naming convention connectionstrings.Environment.json.
Enter the following information into the file;
{
"ConnectionStrings": {
"PIMS": "Server=<localhost or host.docker.internal>,<port>;User ID=sa;Database=<database name>"
}
}The default port for MS-SQL is 1433, but set it to the same value used in the docker-compose.yaml configuration file.
The database name should be the same value used in the database .env file.
dotnet ef must be installed as a global or local tool. Most developers will install dotnet ef as a global tool with the following command:
Use bash, CMD.exe or PowerShell for specific version:
dotnet tool update --global dotnet-ef --version 3.1.0or for latest version use (works also for reinstallation):
dotnet tool update --global dotnet-efSet the environment path so that the tool is executable.
For Linux and macOS, add a line to your shell's configuration:
export PATH="$PATH:$HOME/.dotnet/tools/"For Windows:
You need to add %USERPROFILE%\.dotnet\tools to the PATH.
Make sure you have a properly configured connectionstrings.json or .env file in the /backend/dalfolder.
To kill your database and start over;
dotnet ef database drop --force
dotnet ef database updateThe following example creates a SQL script for the Initial migration;
dotnet ef migrations script 0 InitialIMPORTANT - In order for initial seeding and post migration SQL scripts to run, the first migration must be named Initial (case-sensitive)
The following example creates SQL scripts for all migrations after the Initial migration;
dotnet ef migrations script 20180904195021_InitialTo add a new database code migration do the following;
In your command terminal, cd to the root folder and type the following where [name] is the name of the migration or version number that you want to create:
make db-add n=[name]This command will then create 2 new files, a "[name].Designer.cs" and a "[name].cs" as well as a modified "PimsContextModelSnapshot.cs" file. You can most likely discard the changes to the modified "PimsContextModelSnapshot.cs" file, unless you had made some structural changes to one of the models of the database which would be reflected in that file.
Then add the appropriate folders for this migration to place your SQL scripts, by using the following folder structure where {name} is the same "version number" you had used in the previous step:
mkdir backend/dal/Migrations/{name}/Up/PostUp
mkdir backend/dal/Migrations/{name}/Down/PostDown-**Note: the folders Up/PostUp & Down/PostDown are case sensitive and need to be in "Pascal Case" format.**Finally, add your SQL script for Up (upgrade) and Down (for rollback scripts if needed). If the need to revert the database to the previous state is not necessary such as updating records that contained incorrect data, then there is no need to create the "Down/PostDown" folders. The naming convention for your SQL scripts generally start with 01-{TableName.sql} as a database migration may contain more than one script and will run in sequential order.
-Please see /backend/dal/Migrations for the history of all migrations done or you can look in the database table called "__EFMigrationsHistory".
-If your "__EFMigrationsHistory" database table is not up to date with the latest migration version/s just run "make db-update".You can then test your "migration" by running the command:
make db-update"make db-update" will run any migration/s on your local machine if it detects that the table "__EFMigrationsHistory" is out of date and does not contain the "version number" or name of the migration that you had created.
In the case you need to rollback your migration because it didn't work you can use this command:
make db-rollback n={name or version number} to rollback your database to a specific version-**Note: All these make db commands actually call a dotnet ef database specific function which you can also see in the main Makefile in the root PIMS directory. Also for reference is the CLI documentation here
On a side note, the auto-generated file "[name].cs" will enable running SQL scripts during migration, for either complex database changes, or seed data.
using System;
using Microsoft.EntityFrameworkCore.Migrations;
// Add this using statement.
using Pims.Api.Helpers.Migrations;
namespace Pims.Api.Migrations
{
// Inherit from SeedMigration
public partial class Initial : SeedMigration
{
protected override void Up (MigrationBuilder migrationBuilder)
{
// Add the PreDeploy action.
PreDeploy (migrationBuilder);
...
// If required for complex db changes you can add additional ScriptDeploy(...).
// ScriptDeploy("{this.DefaultMigrationsPath}/{this.Version}/some/path");
...
// Add the PostDeploy action.
PostDeploy (migrationBuilder);
}
}
}Any SQL scripts that you want to run as part of a migration must be additionally included as build content in the project file.
- Edit the
Pims.Dal.csprojfile and; - Add the
<Content>location with a<CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory>(see below example).
NOTE - By default all *.sql files within the /backend/dal/Migrations folder will be included in the project as Content.
<?xml version="1.0" encoding="utf-8"?>
<Project Sdk="Microsoft.NET.Sdk.Web">
<PropertyGroup>
<TargetFramework>netcoreapp3.1</TargetFramework>
</PropertyGroup>
...
<ItemGroup>
<Content Include="Migrations\**\*.sql">
<CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory>
</Content>
</ItemGroup>
</Project>The PIMS solution currently uses a Microsoft SQL Server hosted within a Linux container. This database provides the primary data storage for the API and contains all Property information.
Microsoft SQL Server 2022
- Additional Links
- Architectural Design
- OpenShift Container Memory Consumption
- Disaster Recovery
- Enterprise Relational Diagram
- Primary Tables
- List Tables
- Connecting to OpenShift Database
- SQL Server 2019
- MSSQL - Linux 2019
- MSSQL - Redhat v15
- MSSQL - Linux v15
- SQL Server Management Studio
- Docker Image
The primary purpose of this datasource is to maintain an inventory of properties (Parcels, Buildings and Projects). User roles and claims are managed by keycloak, but are also contained within this datasource. There are also a number of supporting lists to support the front-end application user experience. MS SQL Server Enterprise edition is being used (this requires a license).
It has been discovered that under load MS SQL Server will run out of memory within a container that has less than 6 GB maximum memory. A container is configured with a minimum and maximum memory setting. The minimum can be as low as you want it (i.e. 100 MB). The maximum however must be 6 GB or more. Presently MS SQL Server doesn't require more than 1 GB of memory, even under load, but for some reason it still requires the 6 GB being available.
The database is backed up daily by a cron job service provided by a pod running in each namespace/environment (dev, test, prod). This service is fully configurable and also provides a way to adhoc backup, verify and restore.
| Link | Description |
|---|---|
| DevOps configuration | How to configure database backup for each environment |
| Container image | Detailed information about the database backup container and configuration |
| Disaster Recovery | How to use the database backup and recovery scripts |

As the current primary purpose of the PIMS DB is to manage inventory of properties, the structure revolves around the the two property objects Parcels and Buildings. A Parcel object represents land, and it can contain many Building objects. Additionally the DB provides a structure to support properties being owned by an Agency, so that the appropriate Users have authority to manage it.
Most objects will also include tracking columns to identify when it was created or updated and who created and updated it. Additionally objects will natively provide optimistic concurrency enforcement, which will ensure data is not overwritten in a multi-user concurrent solution.
The following are the primary objects;
| Object | Description |
|---|---|
| Parcels | Land inventory |
| Buildings | Building inventory |
| Projects | Project inventory (disposal, aquisition) |
| Users | Users accounts within PIMS |
| Roles | Roles that authorize abilities within PIMS |
| Agencies | A ministry, crown corporation or entity that owns properties |
| Addresses | A physical address to a location |
| Workflows | Light workflow engine provide a way to control the lifecycle of projects |
| Notification Templates | Manage notification templates that are used for sending email |
| Notification Queue | A queue containing all notifications that have been generated |
The following provide a way to manage lists or collections within the solution;
| Object | Description |
|---|---|
| PropertyTypes | List of property types [land | building] |
| PropertyClassifications | List of property classifications |
| Cities | List of cities |
| Provinces | List of provinces |
| BuildingConstructionTypes | List of building construction types |
| BuildingPredominateUses | List of building predominate uses |
| BuildingOccupantTypes | List of building occupant types |
| TierLevels | List of project tier levels for projects |
| Project Status | List of project status that represent stages a project will go through |
| Project Risks | List of project risks |
| Tasks | List of tasks to complete a process or stage. These are associated to project status and workflows |
"Last Editied By": "Brady Mitchell"
"Date": "May 9th, 2023"- Download SQL Server Management Studio if you haven't already.
- In OpenShift, copy login command from the account dropdown in the top right corner of the dashboard.
- In a terminal with oc CLI tool installed, paste and run the login command.
- Be sure to use the namespace you want to connect to, such as production by executing
oc project 354028-prod. - In OpenShift, Workloads > Pods (in the namespace you wish to use), find the database pod and save its name for the next command.
- In terminal, execute
oc port-forward <name-of-db-pod> 22220:1433.22220can be any number, it is the port on your machine to map to the1433port of the pod in OpenShift. - In SQL Server Management Studio, in the Object Explorer on the left, click on Connect > Database Engine.
- Set the Server Name to
127.0.0.1,22220. - Copy the username and password from OpenShift, Workloads > Secrets > pims-database.
- Connect!
The Data Access Layer (DAL) is a .Net Core 3.1 library that provides access to the datasource. It is the only way to acces the database.
It provides access through the design pattern of Services. Each service provides functions which can interact with objects within the datasource.
The DAL enforces authentication and authorization accross all functions to ensure users only have access and abilities that match their claims.
The following services are supported;
| Name | Description |
|---|---|
| User | User activation, Manage Access Requests |
| Lookup | Various lists and select options |
| Property | Search for properties |
| Building | Building CRUD |
| Parcel | Parcel CRUD |
| Project | Project CRUD |
| Workflow | Fetch project workflows |
| Project Status | Fetch project status |
| Task | Fetch project tasks |
| Project Notification | Fetch project notifications |
| Notification Template | Fetch notification templates |
| Notification Queue | Access notification queue |
Additionally there are the following admin services;
| Name | Description |
|---|---|
| Agency | Manage agencies |
| User | Manage users |
| Role | Manage roles |
| Claim | Manage claims |
| Address | Address CRUD |
| City | Manage cities |
| Province | Manage provinces |
| Property Classification | Manage property classifications |
| Property Type | Manage property types |
| Building Construction Type | Manage building construction types |
| Building Predominate Use | Manage building predominate uses |
| Project Risk | Manage project risks |
| Project Status | Manage project status |
| Tier Level | Manage project tier levels |
| Workflow | Manage Light Workflow Engine |
Development is currently supported through the use of Docker containers, and or local development with VS Code and Visual Studio 2019. Although any IDE that supports the languages should work.
If you don't already have Git installed, install it now.
Git - Make sure option for Git Bash is selected if on Windows.
(For Windows 10) Follow the instructions below to ensure console colors work correctly:
- Right click on
Windows iconin bottom-left of screen and selectSystem. - Scroll down to find and click
Advanced system settings. - Click on
Environment Variables...button, then clickNew...button. - Add a new variable with the name
FORCE_COLORand the valuetrue, save your changes and restart bash.
Clone the repository from https://github.com/bcgov/PIMS. Run the following command in Git Bash (recommended for Windows) or Command Line. If using Docker, ensure you are using a local (not network) drive.
# URL found on Code tab of repository under the green code button.
git clone https://github.com/bcgov/PIMS.git
Change into the pims directory cd pims
Install the following applications
- VS Code
- Docker Desktop - If installing for the first time, unselect WSL 2 option in the installer.
-
.NET Core SDK
- Install SDK 6.0.408 (as of April 14, 2023), which includes the ASP.NET Core Runtime 6.0.16, and .NET Runtime 6.0.16
-
EF CLI - Skip the step that says to run
dotnet add package Microsoft.EntityFrameworkCore.Design
- Chocolatey - Read installation instructions under "Install with PowerShell.exe" Run PowerShell as Administrator.
- Install make with command
choco install make --version=4.3
Here is the Make Installation Instructions for reference. You need to update your PATH for make. The documentation is out of date and only has instructions for Windows 7.
- Use Windows search bar and search for “Edit system environment variables”.
- Click on the “Environment variables” button.
- Select “Path” from the list under “System variables”.
- Click “Edit”, then “New”.
- Paste the following
C:\ProgramData\chocolatey\lib\make\bin
- Save and close tabs.
- Homebrew
- Install coreutils with command
brew install coreutils
4) Install dotnet-ef (Since we've upgraded to .NET version 7, we should install at least dotnet-ef version 7.0.7)
Install dotnet-ef
dotnet tool install --global dotnet-ef --version 7.0.7
or the following command will install the latest version of dotnet-ef (As of June, 2023 it is version 7.0.7)
dotnet tool install --global dotnet-ef
Generate the env files with the following command. You will be prompted for multiple usernames. Do Not set this as "admin", your first name is a good choice.
After generating the files, you may edit the randomly generated password (it's used in multiple .env files).
./scripts/gen-env-files.sh
You will need to obtain 3 variables either
- from someone on the development team,
- or from https://citz-imb.atlassian.net/l/cp/p86LrnB8
- if you don't have access to this confluence doc you can request permission from the IMB Full Stack Developer Chapter Lead.
for the file ./backend/api/.env.
# Add these to ./backend/api/.env
Keycloak__Secret=
Keycloak__ServiceAccount__Secret=
Keycloak__FrontendClientId=Configure Docker Desktop
- General > "Use WSL 2 based engine": needs to be unchecked.
- Resources > Advanced: ensure memory is 6 GB or greater.
- Resources > File Sharing: add path to PIMS. Ex: c:\pims.
- Click "Apply & Restart".
If you have issues trying to unselect WSL 2, you may have to uninstall Docker Desktop, reinstall it and unselect the WSL 2 option in the installer.
Seed Data - You will need to request a ZIP file (mssql-data.zip) from someone on the development team. Once you have obtained this file, place the unzipped contents inside ./database/mssql/data/.
.
├── database
| └── mssql
| └── data // Place unzipped files here.
Use make to set up the containers.
If you run into this error: "failed size validation: 121295976 != 141401206: failed precondition" while running either the make setup or restart commands, you may need to turn off your vpn.
make setup
This should output a summary before finishing. If it hangs for too long and won't finish, re-try the command.
Restart the application
make restart
If the app crashes, try the command again.
It will take the app a few minutes to load. The app container console will display when the server has started.
Open Application in Browser (localhost:3000)
If the app is stuck on the loading animation, refresh the page.
Login with your idir account.
If everything is working correctly, you should see colourful blips on the map that represent properties.
If you do not see anything on the map and get the following error message, the data did not get seeded or can not be retrieved. You may have missed a step, not allocated enough memory in Docker settings, or placed the zip file data in the incorrect directory. The first thing you should try is stopping the containers with make down, then make setup, then make restart.
- Request failed with status code 500: An error occured while fetching properties in inventory.To stop the application, run make stop.
To restart the application, run make restart.
To start the application, run make start.
For git developer workflow instructions, see Git Workflow.
To simplify development once the initial setup is complete, you can use the make commands.
make help| Command | Description |
|---|---|
| setup | Setup local container environment, initialize keycloak and database |
| build | Builds the local containers |
| up | Runs the local containers |
| up-dev | Runs the local containers, but uses the frontend-dev container. |
| stop | Stops the local containers |
| down | Stops the local containers and removes them |
| restart | Restart local docker environment |
| refresh | Recreates local docker environment |
| clean | Removes local containers, images, volumes, etc |
| npm-clean | Removes local containers, images, volumes for frontend-dev |
| npm-refresh | Cleans and rebuilds the frontend-dev container and cache to handle npm changes |
| db-migrations | Display a list of the database migrations |
| db-add | Create and add a new database migration (n={migration}) |
| db-update | Update the database with the latest migration |
| db-rollback | Rollback the specified database migration (n={migration}) |
| db-remove | Remove the last database migration files |
| db-clean | Re-creates an empty docker database - ready for seeding |
| db-refresh | Refreshes the docker database |
| db-drop | Drop the database |
| server-run | Starts local server containers |
| client-test | Runs the client tests in a container |
| server-test | Runs the server tests in a container |
| convert | Convert Excel files to JSON |
The Pathfinder-SSO team announced that as of February 2023, their Keycloak Silver service would be coming to an end, and in it's place the new Keycloak Gold. The Keycloak Silver service allowed users to request a custom Keycloak Realm for use in their application, which provided a huge amount of customization capabilities, whereas Keycloak Gold was a shared realm for all apps, and only contains the features provided by the Pathfinder-SSO team.
Each user's agency(ies) was previously found within the PIMS Keycloak Silver realm. Due to the changeover and removal of features from Keycloak, we now can only retrieve each user's roles from our database, which changed the code for getting a user's agencies in the backend from:
// OLD
var userAgencies = this.User.GetAgencies();to:
// NEW
var user = this.Context.Users
.Include(u => u.Agencies)
.ThenInclude(a => a.Agency)
.ThenInclude(a => a.Children)
.SingleOrDefault(u => u.Username == this.User.GetUsername()) ?? throw new KeyNotFoundException();
var userAgencies = user.Agencies.Select(a => a.AgencyId).ToList();Due to the users agencies no longer being stored within the access token, upon page load, the frontend now makes a request to the /users/agencies endpoint to fetch the user's agencies upon page load. This should be a temporary fix however, and this functionality should be moved to the /activate endpoint to reduce the total number of API calls made.
//TODO: "Modify the /activate endpoint to also return the users agencies, removing the need for this endpoint."
[HttpGet("agencies/{username}")]
[Produces("application/json")]
[ProducesResponseType(typeof(Model.AccessRequestModel), 200)]
[ProducesResponseType(typeof(Models.ErrorResponseModel), 400)]
[ProducesResponseType(typeof(Models.ErrorResponseModel), 403)]
[SwaggerOperation(Tags = new[] { "user" })]
public IActionResult GetUserAgencies(string username)
{
IEnumerable<int> userAgencies = _pimsService.User.GetAgencies(username);
return new JsonResult(userAgencies);
}Keycloak Gold allows the granting and removal of roles on users, as well as the granting/removal of groups of roles called "Composite Roles". PIMS uses Composite Roles in place of the previous Keycloak Silver "Groups", and can be identified in the list of roles in the Keycloak Gold console as they are structured with capital letters and spaces, as opposed to the structure of regular roles being lowercase and in kebab-case.
Composite Role: System Administrator
Role: property-view
When managing users from within the admin page, accessing said user's composite roles requires an extra call to the Keycloak Gold API, using PIMS' service account credentials. With said roles, we allow the frontend to add/remove composite roles from specific users. Each addition/removal of a role to a user now has it's own api call, and the edit user page's UI is updated to reflect that.
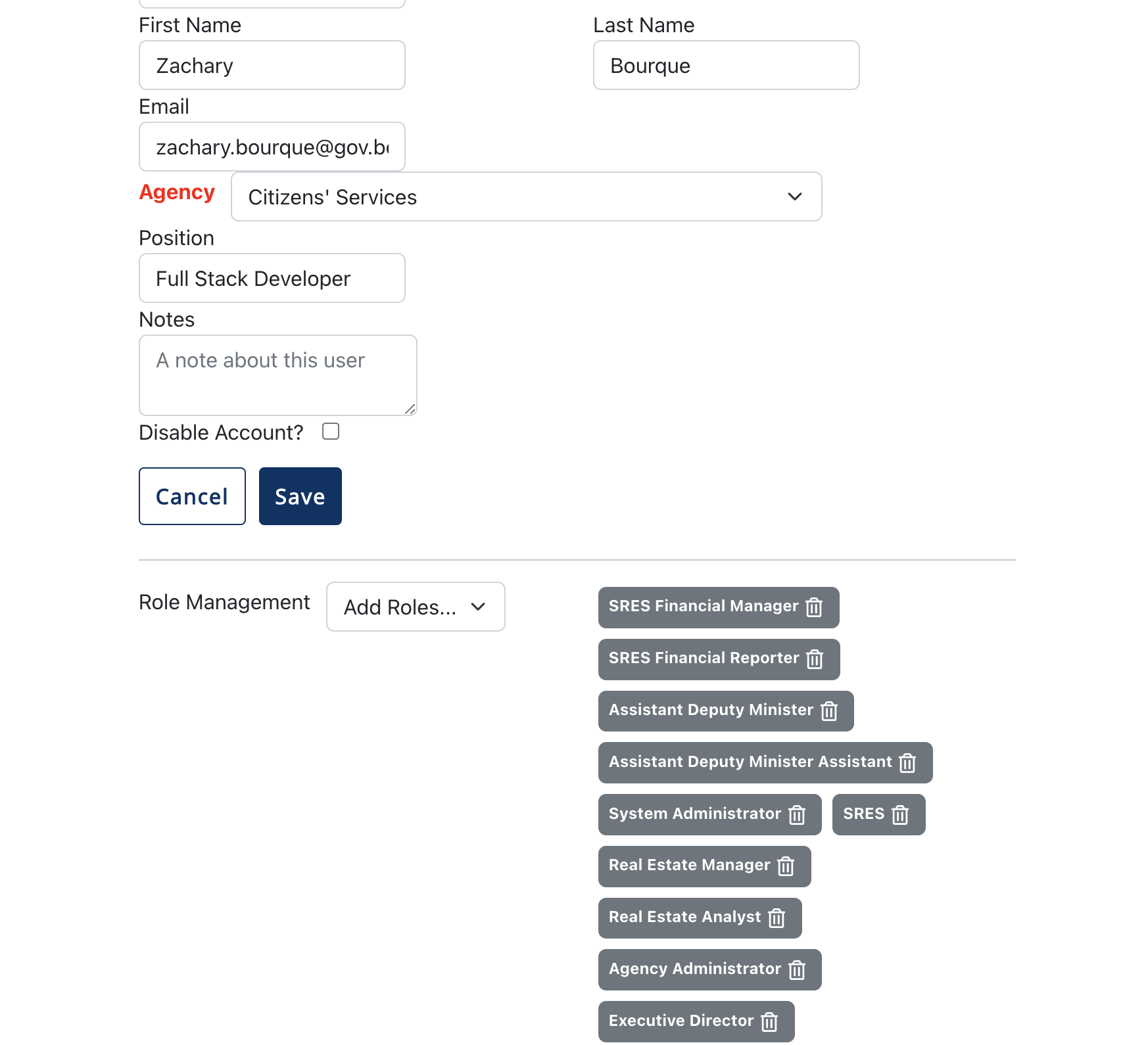
The user role selection is now below the save button, and is separated by a divider, implying that the role management is separated from the standard updating user feature.
/// <summary>
/// POST - Add a role to the user by calling the Keycloak Gold API.
/// </summary>
/// <param name="username">The user's username</param>
/// <param name="role">A JSON object with the name of the role to add.</param>
/// <returns>JSON Array of the users roles, updated with the one just added.</returns>
[HttpPost("role/{username}")]
[Produces("application/json")]
[ProducesResponseType(typeof(Model.UserModel), 200)]
[ProducesResponseType(typeof(Api.Models.ErrorResponseModel), 400)]
[SwaggerOperation(Tags = new[] { "admin-user" })]
public IActionResult AddRoleToUser(string username, [FromBody] Dictionary<string, string> role)
{
var user = _pimsAdminService.User.Get(username);
var preferred_username = _pimsAdminService.User.GetUsersPreferredUsername(user.KeycloakUserId ?? Guid.Empty, user.Username.Split("@").Last()).Result;
var res = _pimsAdminService.User.AddRoleToUser(preferred_username, role.GetValueOrDefault("name")).Result;
return new JsonResult(res);
}
/// <summary>
/// DELETE - Remove a role from the user by calling the Keycloak Gold API.
/// </summary>
/// <param name="username">The user's username</param>
/// <param name="role">A JSON object with the name of the role to remove.</param>
/// <returns>JSON Array of the users roles, updated with the one just added.</returns>
[HttpDelete("role/{username}")]
[Produces("application/json")]
[ProducesResponseType(typeof(Model.UserModel), 200)]
[ProducesResponseType(typeof(Api.Models.ErrorResponseModel), 400)]
[SwaggerOperation(Tags = new[] { "admin-user" })]
public IActionResult DeleteRoleFromUser(string username, [FromBody] Dictionary<string, string> role)
{
var user = _pimsAdminService.User.Get(username);
var preferred_username = _pimsAdminService.User.GetUsersPreferredUsername(user.KeycloakUserId ?? Guid.Empty, user.Username.Split("@").Last()).Result;
var res = _pimsAdminService.User.DeleteRoleFromUser(preferred_username, role.GetValueOrDefault("name")).Result;
return new JsonResult(res);
}Keycloak Gold only provides 3 environments per "integration", dev, test, and prod. Due to the PIMS team needing a fourth environment for local, we now manage 2 keycloak integrations, PIMS-Frontend-Local, and PIMS-Frontend. This results in the removal of the keycloak docker container within our local development environment, bringing the total container count for local down to 3.
The Keycloak Gold workflow is as follows
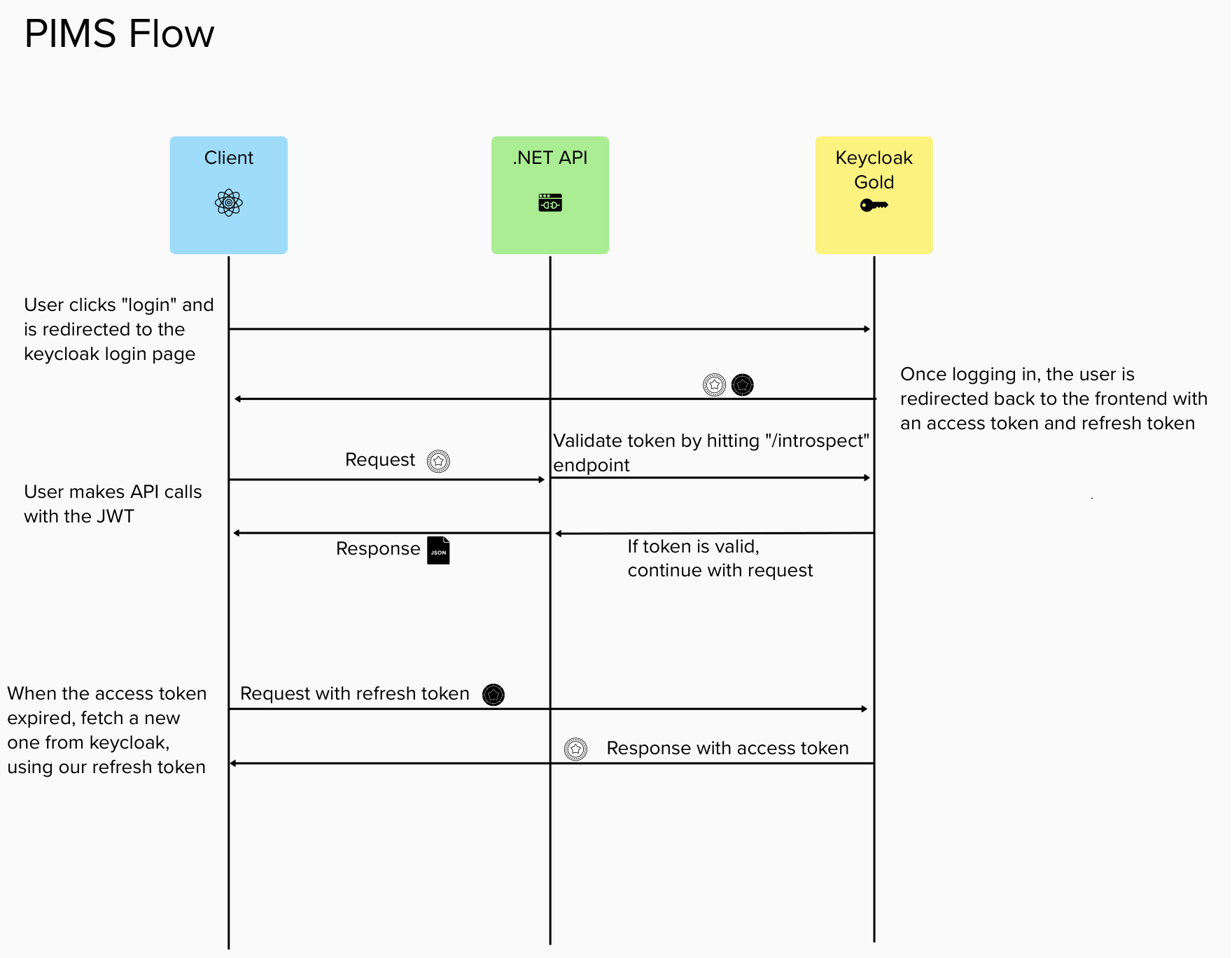
For every API request, the controller has access to the requesting user's decoded JWT token in the form of this.User. Said reference to the user contains extension methods which allow for easy consumption of the user, such as this.User.GetUsername() or this.User.GetEmail(). These extension methods, found in IdentityExtensions.cs, have been updated to align with the claims on the new Keycloak Gold access tokens.
Step 1: Set Up the Target Database
- Create the new database in the target namespace using the database deployment config.
- Setup an image stream for the official Microsoft SQL Server image.
- Create a deployment configuration for MSSQL within your target namespace. This configuration defines how the MSSQL container should run.
- Attach a persistent volume to the MSSQL pod, ensuring data persistence even if the pod restarts or moves to a different node.
- Specify the mount path as
/var/opt/mssqlin the deployment configuration, ensuring that the database files are stored persistently. - Add Env variables to Deployment config:
-
SA_PASSWORD: Set a secure password for the SA (System Administrator) account. -
DB_NAME: Specify the name of the database you want to create. -
DB_PASSWORD: Define the password for the database user. -
DB_USER: Set the username for accessing the database.
-
Step 2: Prepare the Source Database A. Navigate to the Source Database Pod in OpenShift
- Open Pod Terminal:
- Use the OpenShift Console or local terminal (by using
openshift login) and navigate to the namespace containing the backup MSSQL database. oc project sourceNamespaceoc exec -it source-database-pod -- /bin/bash
- Use the OpenShift Console or local terminal (by using
- Check for Daily Backups:
- Navigate to the directory where daily backups are stored and confirm their existence.
- Example:
cd backups/daily ls
B. Download the Backup Files
- Use
oc rsyncto Download Backups:- Utilize the
oc rsynccommand to download the backup files from the source pod to your local machine. - Example command: Replace "pims-backup-11-2h4qb" with your actual source pod name
oc rsync pims-backup-11-2h4qb:/backups/daily/ ./daily
- Utilize the
C. Upload the Backup to the Target Pod
- Switch to Target Namespace:
- Move to your local terminal and switch to the source database namespace.
oc project targetNamespace
- Use
oc rsyncto Upload Backups to Target Pod:- Employ the
oc rsynccommand to upload the downloaded backup files to the target pod. - Example command: Replace "pims-database-1-7f84t" with your actual target pod name
oc rsync ./daily/2023-10-26 pims-database-1-7f84t:/var/opt/mssql
- Employ the
Step 3: Restore the Backup A. Navigate to the New Database Pod Terminal
- Access Pod Terminal:
- Use the OpenShift Console or CLI to navigate to the namespace containing the new MSSQL database pod.
- Example: Assuming your pod is named "new-database-pod" in the "targetNamespace"
oc exec -it new-database-pod -- /bin/bash
- Check the Upload:
- Navigate to the directory where the backup files were uploaded and confirm their presence.
-
cd /var/opt/mssql ls
B. Login to the Database Server Using SA Credentials
- Use SQLCMD to Login:
- Login to the MSSQL database server in the pod terminal using the SA credentials provided in the deployment config.
- Example:
/opt/mssql-tools/bin/sqlcmd -S localhost -U SA -P 'Pass123!'
C. Restore the Backup
- Use RESTORE DATABASE:
- Restore the database from the backup file. Modify the path to the backup file according to your directory structure and file names.
- Example: assuming the backup file name to be "2023-10-26/backupFile"
RESTORE DATABASE YourNewDatabaseName FROM DISK = '/var/opt/mssql/2023-10-26/backupFile' WITH REPLACE; #if the database already existed
A. Login Issues with DB_USER Login
-
Attempt DB_USER Login:
- Try logging in using the DB_USER login created during the deployment configuration.
-
Create DB_USER User if Login Fails
-
CREATE LOGIN DB_USER # replace db_user with the username WITH PASSWORD = 'abcd'; # use the password and username provided in the deployment config -- Connect to the database USE YourNewDatabaseName;
-
-
Check Access with Admin Login:
- Attempt to access the database using the newly created admin login.
-- Connect to the database USE YourNewDatabaseName;
- Attempt to access the database using the newly created admin login.
-
Error on Access Rights:
- If access rights errors occur, log in with the SA account and provide permissions to the “DB_USER“
-- Connect to the database using SA USE YourNewDatabaseName; -- Grant necessary access rights to the DB_USER user EXEC sp_addrolemember 'db_datareader', 'DB_USER'; EXEC sp_addrolemember 'db_datawriter', 'DB_USER';
- If access rights errors occur, log in with the SA account and provide permissions to the “DB_USER“

"Last Editied By": "Brady Mitchell"
"Date": "June 2nd, 2023"pims-pipeline
- Builds and deploys to
DEV. - Automatically triggered when merging to
devbranch.
- A pull request is merged to the
devbranch. - Currently, there is two webhooks in the GitHub repo that trigger when a push or pull request are made. These are
http://pims-tekton.apps.silver.devops.gov.bc.ca/hooks/apiandhttp://pims-tekton.apps.silver.devops.gov.bc.ca/hooks/app. - In OpenShift, the webhooks can be found under Networking > Routes as
git-webhook-pim-appandgit-webhook-pim-api. - There, routes are connected with services
el-git-pims-appandel-git-pims-apiwhich trigger the pipeline event listener. - The pipeline event listeners can be found in Pipelines > Triggers > Event Listeners as
git-pims-appandgit-pims-api. These triggers will run the pipeline trigger templatesgit-pims-appandgit-pims-apiif changes are made to thedevbranch in eitherfrontendorbackend.
Tasks/Steps:
app-build - Builds from the pims-app-base.dev BuildConfig and then pims-app.dev BuildConfig.
"Last Editied By": "Brady Mitchell"
"Date": "May 10th, 2023"master-pipeline
- Builds and deploys to
TEST. - Manually triggered by selecting the pipeline, clicking
Actions>Start, and then specifying an image tag such asv02.03.12. - To know what image tag to use, follow these steps:
- Go to
Builds>Image Streams, find and click onpims-apporpims-api. - Scroll to the bottom of the
Tagssection. - Under
Namecolumn (1st column on left), you should see the final entry looks something likepims-app:v02.03.12. - The image tag to use when running the pipeline should be above this version number such as
v02.03.13. - Use semantic versioning:
- Major overhall to the application:
v03.00.00 - Minor but significant changes to the application:
v02.04.00 - Patch or minor changes to the application:
v02.03.13
- Major overhall to the application:
- Go to
"Last Editied By": "Brady Mitchell"
"Date": "May 10th, 2023"deploy
- Deploys to
PROD. - Manually triggered by selecting the pipeline, clicking
Actions>Start, and then specifying an image tag such asv02.03.12. - To know what image tag to use, follow these steps:
- Go to
Builds>Image Streams, find and click onpims-apporpims-api. - Scroll to the bottom of the
Tagssection. - Under
Namecolumn (1st column on left), you should see the final entry looks something likepims-app:v02.03.12. - Use this image tag, example:
v02.03.12.
- Go to

"Last Editied By": "Brady Mitchell"
"Date": "June 2nd, 2023"pims-app-base.dev :
- References frontend/Dockerfile.ocp which uses vite to build the production code.
- This Dockerfile references a
nodejsimage that can be found in ImageStreams. - Outputs to
pims-app-base:latestimage. - This output image will then be used by
pims-app.devduring theapp-buildtask/step of thepims-pipeline. - To test production build locally, reference Testing the Production Build Locally
pims-app.dev :
- Builds nginx runtime based on
pims-app-base:latestimage. - Outputs to
pims-app:latestimage.
pims-app-base.master :
- Specifies the source image for building the TEST app.
- Outputs to
pims-app-base:latestimage.
pims-app.master :
- Builds nginx runtime based on
pims-app-base:latestimage. - Outputs to
pims-app:latestimage.
pims-api.dev :
- Specifies Dockerfile with image for building DEV api. This image in the Dockerfile.ocp is referencing an image in OpenShift tools namespace.
pims-api.master :
- Specifies Dockerfile with image for building TEST api. This image in the Dockerfile.ocp is referencing an image in OpenShift tools namespace.
pims-database.dev :
- Specifies Dockerfile with image for building DEV database.
pims-database.master :
- Specifies Dockerfile with image for building TEST database.
backup-mssql :
-
Specifies the Docker image to use for the mssql database backups. In the yaml file of this build config, the "dockerStrategy" section contains the url to the image that will be used during the build:
`kind: DockerImage` `name: 'mcr.microsoft.com/mssql/rhel/server:2022-latest'` -
This "name" value can be updated whenever the backup-mssql image needs to be updated. After saving changes to the yaml file, all you need to do is start the "build" by clicking the actions tab in the top right of the backup-mssql buildconfig and then select "Start build". Once this completes the 'backup-mssql' image latest tag should be updated with the mssql image that you used in the yaml file.
"Last Editied By": "Sharala Perumal"
"Date": "Sept 15th, 2023"Tagging Images:
- In OpenShift, copy login command from the account dropdown in the top right corner of the dashboard.
- In a terminal with oc CLI tool installed, paste and run the login command.
- Make sure you are in the tools namespace by executing
oc project 354028-tools. - Tag an image using
oc tag <image> <imagestream>:<tag>- Where
<image>is the image and tag you want to use, such as a Docker image,
and<imagestream>:<tag>corresponds with an image in theBuilds>ImageStreamssection of OpenShift. - Example:
oc tag docker.io/node:18.17.1-bullseye-slim nodejs:18.17.1-bullseye-slim. - Note: For docker images you may need to first
docker pull <image>and thenoc tag docker.io/<image> <imagestream>:<tag>.
- Where
nodejs :
- NodeJS image for building the frontend app.
- Has tag
18.17.1-bullseye-slimused byfrontend/Dockerfile.ocp
dotnet-aspnet-runtime :
- DotNet Runtime image from Microsoft on Docker Hub for running backend api.
- Latest used tag is
7.0.
dotnet-sdk :
- DotNet SDK image from Microsoft on Docker Hub for building and compiling backend api.
- Latest used tag is
7.0.
mssql-rhel-server :
- Microsoft SQL Server from Microsoft on Docker Hub for running the database.
- Latest used tag is
2022.
backup-mssql :
- MSSQL backups using plugin developed by https://github.com/BCDevOps/backup-container
- Latest used tag is
latest. - To update the latest image, there is a "buildconfig" called backup-mssql in the tools namespace in which you need to edit the yaml section for git ref which refers to which version of the backup container to use. (see build config section for backup-mssql above)
- After updating the
latesttag, to update the remainingdev,test, andprodtags for this image, just run the following commands:oc tag -n 354028-tools backup-mssql:latest backup-mssql:dev,oc tag -n 354028-tools backup-mssql:latest backup-mssql:test, andoc tag -n 354028-tools backup-mssql:latest backup-mssql:prod
"Last Editied By": "Lawrence Lau"
"Date": "April, 2023"- Before the SSL certificate for the production site expires (usually a month in advance), we should get contacted by someone at IMB operations who will send us three files for renewing the certificate: pims.gov.bc.ca.txt, pims.gov.bc.ca.key, and L1KChain.txt.
- Basically there are 2 routes in the production namespace: pims-api & pims-app that we will need to "modify" in order to update the 3 fields corresponding to the Certificate, CA Certificate, and Key fields that are contained within the yaml of the routes.
- What we will be doing in the next steps will be to download the existing routes for the app and the api to our local machines so that we can update those 3 fields mentioned above with the new files that contain the new public and private keys. The final steps will be to "apply" the new route which will update the 2 routes in our production environment.
| Field to Modify in Yaml | File Name |
|---|---|
| Certificate | pims.gov.bc.ca.txt |
| Key (Private Key) | pims.gov.bc.ca.key |
| CA Certificate | L1KChain.txt |
- Login to your Openshift project using the oc cli, and download a copy of the "pims-app" and the "pims-api" routes yaml files from the prod namespace as a backup.
- Then use the command below to create a copy of the route on your local machine which will be used when applying the new cert. The command below will create 2 new files called pims-api-2022.yaml and pims-app-2022.yaml, based on the existing pims-api and pims-app routes, in your current directory which in our case was the root directory, the -o yaml outputs the yaml of the route into a new file which you can name whatever you want, in this case it's named: pims-app-2022.yaml. Once this file is created, we will need to "clean up" and get rid of some unnecessary fields.
oc get route pims-api -o yaml > pims-api-2022.yamloc get route pims-app -o yaml > pims-app-2022.yaml
- Next open the newly created file/s in the previous step and delete the unnecessary fields and sections in the yaml files: uid, resourceVersion, creationTimestamp, annotations, managedFields section (this one is long), status section (at the bottom). These fields will be automatically generated when the route gets “re-applied”.
- When replacing the new caCertificate, certificate, and key fields you can use this syntax shown below and then copy and paste the entire certificate/s into each section. The pipe operator with the dash
|-is yaml syntax which recognizes a multi-line string, so you don’t need to convert the certificate into one long string.
caCertificate: |-
-----BEGIN CERTIFICATE-----
MIIFDjCCA/agAwIBAgIMDulMwwAAAABR03eFMA0GCSqGSIb3DQEBCwUAMIG+MQsw
CQYDVQQGEwJVUzEWMBQGA1UEChMNRW50cnVzdCwgSW5jLjEoMCYGA1UECxMfU2Vl
IHd3dy5lbnRydXN0Lm5ldC9sZWdhbC10ZXJtczE5MDcGA1UECxMwKGMpIDIwMDkg
...-
Once the new certs have been copied and pasted into the yaml file, save it, then do a dry run using the following command:
oc apply -f pims-api-2022.yaml --dry-run=client
-
If the dry run was successfully, you should see the following with no errors:
route.route.openshift.io/pims-api configured (dry run)
-
As long as there are no errors, you should be able to “apply” the new yaml which will update the route in openshift:
oc apply -f pims-api-2022.yaml
-
If the apply was successful you will see an output similar to below:
route.route.openshift.io/pims-api configured
-
You can then follow the same steps to apply the updated yaml to the pims-app
oc apply -f pims-app-2022.yaml --dry-run=client
-
If the dry run was successfully, you should see the following with no errors:
route.route.openshift.io/pims-app configured (dry run)
-
As long as there are no errors, you should be able to “apply” the new yaml which will update the route in openshift:
oc apply -f pims-app-2022.yaml
-
If the apply was successful you will see an output similar to below:
route.route.openshift.io/pims-app configured
"Last Editied By": "Brady Mitchell"
"Date": "June 15th, 2023"To test the production build (as it would be in OpenShift) on your local machine, change target: dev to target: prod under the frontend service in docker-compose.yml. Run make npm-refresh or make rebuild n=frontend to rebuild the frontend.
"Last Editied By": "Lawrence Lau"
"Date": "June, 2023"Database backups are created every morning at 1am in Dev, Test, and in Prod. There are daily, weekly, and monthly backups, and only the most recent 3 daily backups, 1 weekly, and 1 monthly backup are retained. In each of the Dev, Test, and Prod environments there is a "pims-backup" pod that you can access to either view the backups or to manually restore a specific backup for the PIMS database.

To view existing backups, click on the Terminal tab of the pims-backup pod, and then in the terminal type the following command:
./backup.sh -l

You can view the configuration settings for the backup by clicking on the "Logs" tab:

A weekly backup should usually be created every Sunday at 1am, and the monthly backups should be created on the last day of the month. All older backups will be automatically pruned.
To restore a specific backup, open the terminal for in the environment which you want to restore, and run the following command:
./backup.sh -r mssql=pims-database:1433/pims -f /backups/monthly/2023-05-31/pims-database-pims_2023-05-31_13-55-43
You can also run ./backup.sh -h to get a list of all the commands that you can run. Also there is more documentation on the backup container itself: https://github.com/BCDevOps/backup-container as well as some additional documentation here: https://github.com/bcgov/PIMS/blob/dev/maintenance/RESTORE_BACKUPS.md and here: https://github.com/bcgov/PIMS/blob/dev/maintenance/BACKUP.md
You can change the configuration of the pims-backup by modifying the pims-backup DeploymnentConfig "Environment" variables in Openshift. For example, you can set the number of daily (DAILY_BACKUPS), weekly (WEEKLY_BACKUPS), and monthly (MONTHLY_BACKUPS) backups in the deployment config as well as the total number of backups to keep (NUM_BACKUPS is optional).

Once you save the deployment config, it will terminate the existing pims-backup pod and create a new one with the new configuration changes.
To set the "create a Rocketchat integration you can set the WEBHOOK_URL variable, but first you will need to create a Key/Value secret to store the rocketchat url in Openshift:

and then in the "pims-backup" deployment config you would choose that secret with the corresponding "key" to use:


After you save the "pims-backup" deployment config, it will create a new "pims-backup" pod, which you can then use the terminal tab in the pod to check the settings by viewing the logs tab:

Note that any change to the "pims-backup" deployment config will remove the "pims-"backup" pod and will create a new pod.

Below is an example of how to create a Rocketchat integration with the backup container service using an "incoming" webhook.
When creating an "incoming" integration, you need to click on the 3 dots on the top right of the left side panel:

Next click on the Integrations as shown below and then you will need to click the "New" button at the top right of the screen to create a new integration:

You will need to "enable" this integration, and enter the following fields highlighted in yellow below, (note: that you will need to have already created the channel to use in this integration). We are using the user "rocket.cat" as the generic username that this integration will post as. You will also need to add the user "rocket.cat" to your channel in order for it to be able to post to your channel.

You may need to create your own script, but in our case we used this script which was provided in the backup container source code
All we needed to do is copy and paste that javascript code into the "Script" field as shown below and toggle the "Script Enabled" to enable it.

After saving this integration the Webhook URL, Token, and Curl fields will be automatically generated and populated in this integration.
You can use the curl script to do a test of the webhook from a terminal on your local machine. Just copy the curl and paste it into your terminal, hit return and you should get a notification show up in the channel that you had specified for it to post to.
In our case, we are using this integration with the backup container provided by Platform Services. The backup container developed and maintained by Wade Barnes was created with Rocket Chat integration in mind
So, the next step is to copy the Webhook URL into a key/value secret in OpenShift which the backup container uses when it creates a backup. We first created a new key/value secret in each namespace (dev, test, and prod) and copied the webhook url into the Value field as shown below:

The next step is changing the configuration of the pims-backup deployment config so that it uses this new webhook. To do that, go to Deployment Configs in Openshift and then click on the pims-backup (there should only be one). Then select the "Environment" tab and scroll down to the WEBHOOK_URL section, in our case we changed it to get the webhook url from the "rocketchat-dev-backup" secret which was created in the previous step. The backup container also provided fields for the "ENVIRONMENT_FRIENDLY_NAME" as well as the "ENVIRONMENT_NAME" which will get used in the webhook, so that the notification that appears in the channel will describe which environment the backup was created in.

After you save the "pims-backup" deployment config, it will create a new "pims-backup" pod, which you can then use the terminal tab in the pod to check the settings by viewing the logs tab:

Note that any change to the "pims-backup" deployment config will remove the "pims-"backup" pod and will create a new pod.
Now, every time a database backup "runs" it will post to the webhook in Rocketchat allowing it to create a post in the pims-db-backups channel whether the backup was successfully created or if there was an error.
The Light Workflow Engine provides a simple way to manage the lifecycle of a project, while provide a degree of flexibility with customization and future changes.
Additionally as the solution expands new workflows can be created and changes can be dynamically made to alter existing workflows.
At the heart of the workflows is a collection of status (or stages). These represent steps that can or must be performed before a project can continue to another status. Each status can be mapped to allow for transition to any other status, thus enabling a way to ensure consistent workflow.
A milestone represents a critical process in a workflow. A project status can be marked as a milestone. When a project status is identified as a milestone it enforces the requirement to only be updated through the workflow engine endpoint. Other minor status can be changed through normal CRUD operations.
Milestones are commonly used to transition from one workflow into another. But this is not a requirement.
Milestones can include additional business logic that has been coded into the workflow engine.
Tasks provide essentially a checklist of activities that need to be performed.
Tasks are generally linked to a project status, but are not required to be. This provides a way to identify a checklist of activities for each status that should be performed before moving onto the next status.
Here are the currently supported workflows;