This repo contains the code for Critique Fine-Tuning: Learning to Critique is More Effective than Learning to Imitate. In this paper, we introduce Critique Fine-Tuning (CFT) - a paradigm shift in LLM training where models learn to critique rather than imitate!
Our fine-tuning method can achieve on par results with RL training!
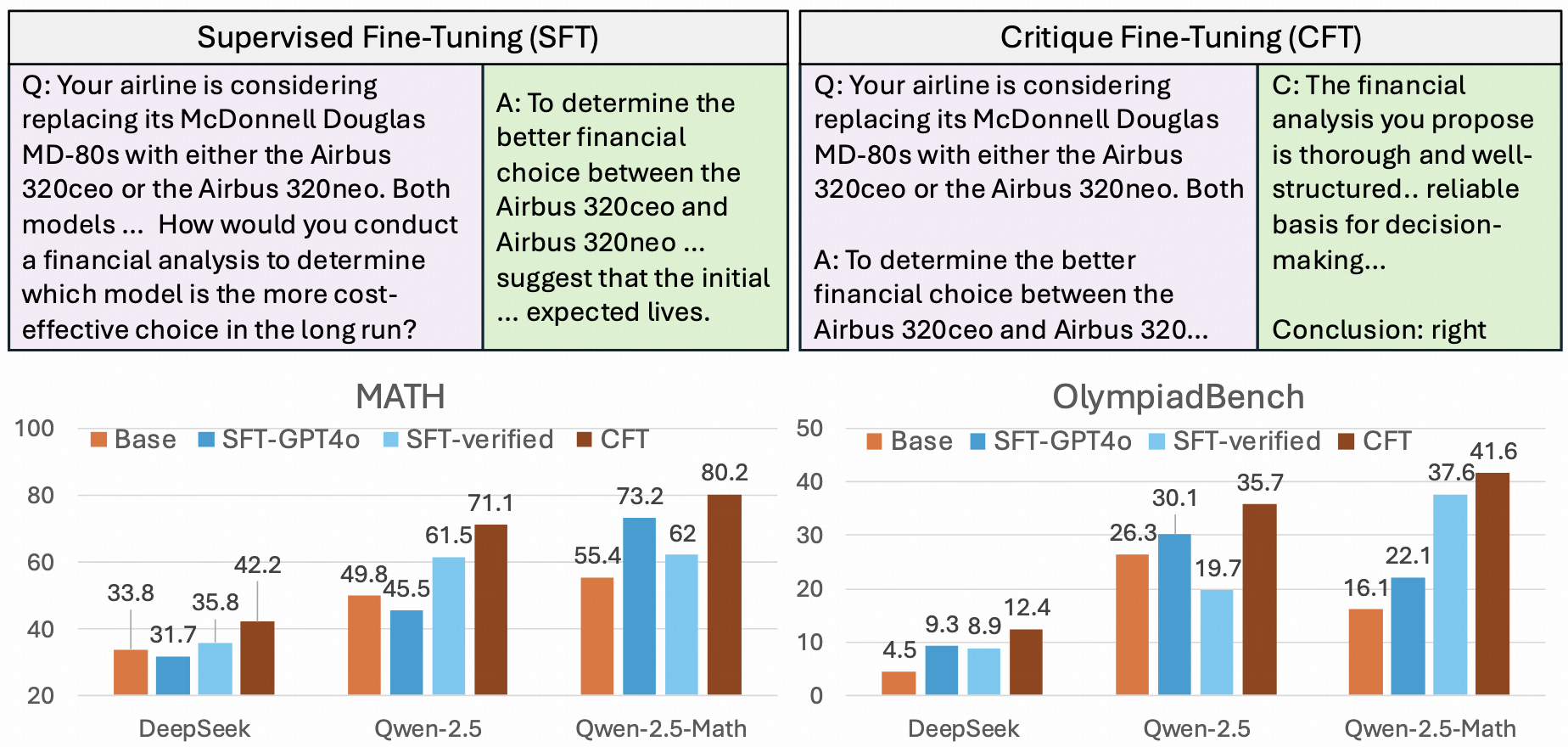
- [2025/01/30] ⚡️ The paper, code, data, and model for CritiqueFineTuning are all available online.
- First install LLaMA-Factory:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"- Install additional requirements: pip install -r requirements.txt
- First, clone the repository and download the dataset:
git clone https://github.com/TIGER-AI-Lab/CritiqueFineTuning.git
cd tools/scripts
bash download_data.sh-
Configure model paths in train/scripts/train_qwen2_5-math-7b-cft/qwen2.5-math-7b-cft-webinstruct-50k.yaml
-
Start training:
cd ../../train/scripts/train_qwen2_5-math-7b-cft
bash train.shFor training the 32B model, follow a similar process but refer to the configuration in train/scripts/train_qwen2_5-32b-instruct-cft/qwen2.5-32b-cft-webinstruct-4k.yaml.
Note: In our paper experiments, we used MATH-500 as the validation set to select the final checkpoint. After training is complete, run the following commands to generate validation scores:
cd train/Validation
bash start_validate.shThis will create a validation_summary.txt file containing MATH-500 scores for each checkpoint. Select the checkpoint with the highest score as your final model.
Fill in the model path and evaluation result save path in tools/scripts/evaluate.sh, then run:
cd tools/scripts
bash evaluate.shNote: Our evaluation code is modified from Qwen2.5-Math and MAmmoTH.
To create your own critique data, you can use our data generation script:
cd tools/self_construct_critique_data
bash run.shSimply modify the model_name parameter in run.sh to specify which model you want to use as the critique teacher. The script will generate critique data following our paper's approach.
Cite our paper as
@misc{wang2025critiquefinetuninglearningcritique,
title={Critique Fine-Tuning: Learning to Critique is More Effective than Learning to Imitate},
author={Yubo Wang and Xiang Yue and Wenhu Chen},
year={2025},
eprint={2501.17703},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2501.17703},
}