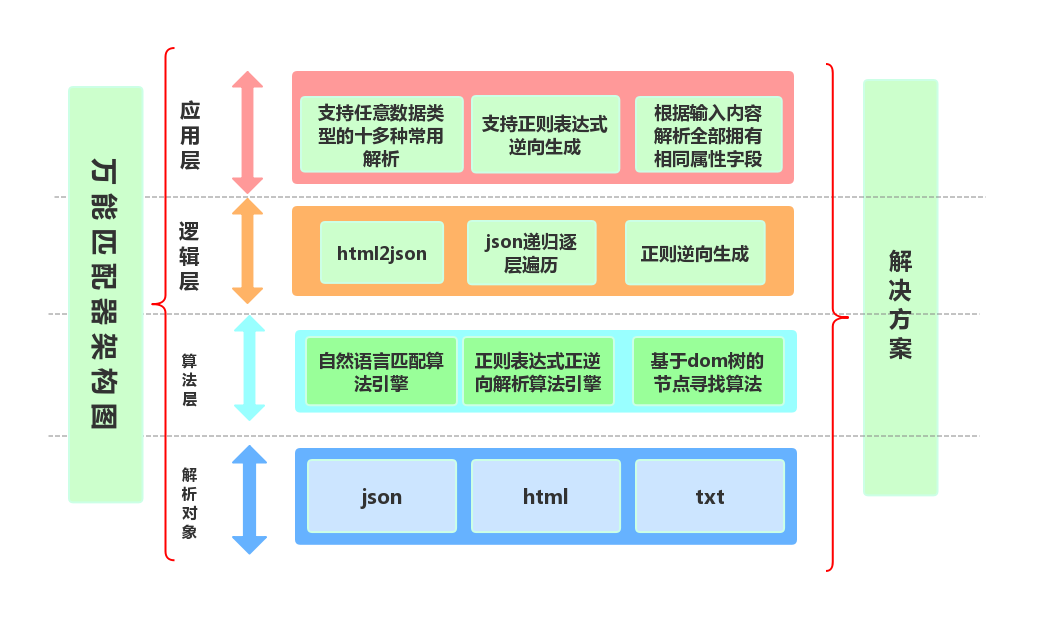
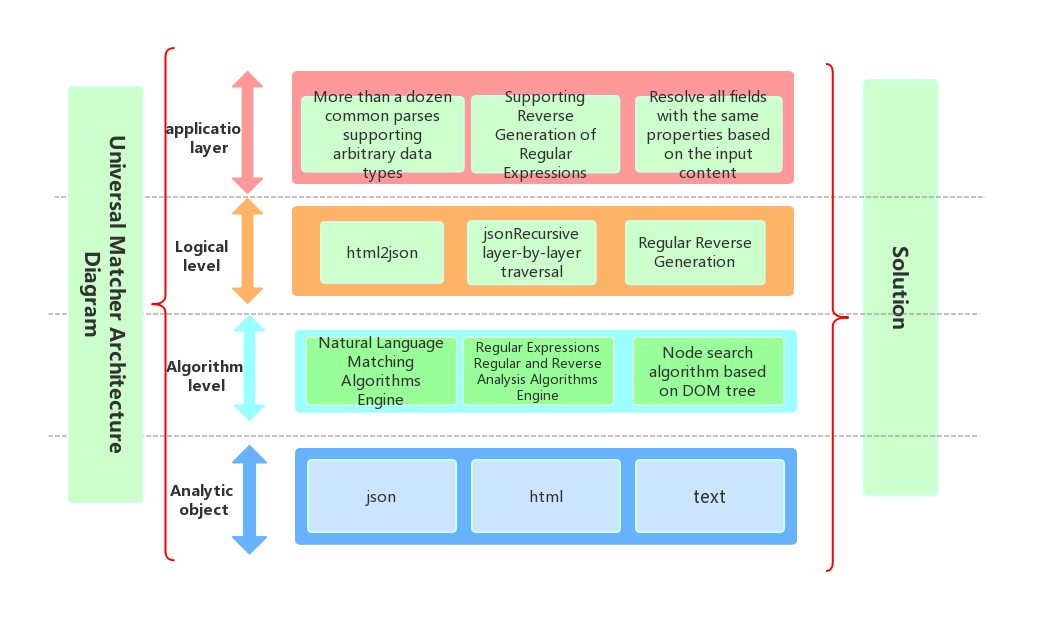
pymatchers 打造最好用的万能解析神器/Create the Best Universal Resolution Artifact.
- Python 3.+
- Works on Linux, Windows, Mac OSX, BSD
The quick way:
pip install pymatchers
✨🍰✨
Behold, the power of pymatchers:
>>> from pymatchers import Matchers
>>> content = '''
华为创立于1987年,是全球领先的ICT(信息与通信)基础设施和智能终端提供商,我们致力于把数字世界带入每个人、每个家庭、每个组织,构建万物互联的智能世界。目前华为有18.8万员工,业务遍及170多个国家和地区,服务30多亿人口。
地址: 深圳市龙岗区坂田华为总部办公楼。邮箱:[email protected]。电话:18813754316。
官网地址http://www.huawei.com/cn/,统一社会信用代码914403001922038216。
'''
For: Web pages, strings, and JSON. Common Analytical Examples:
>>># email提取/email extraction
>>> Matchers().match_email(content)
2019-09-13 22:43:42,337 - root - INFO - Start commonParse engine
['[email protected]']
>>># 地址提取/Address extraction
>>> Matchers().match_address("服务30多亿人口。地址:深圳市龙岗区坂田华为总部办公楼。邮箱:[email protected]。")
['深圳市龙岗区坂田华为总部办公楼']
>>># 手机号码提取/Mobile phone number extraction
>>> Matchers().match_phone(content)
['18813754316']
>>># 通用网页正文提取/General Web Page Text Extraction
>>> Matchers().match_content(requests.get("http://baijiahao.baidu.com/s?id=1644453217226236035&wfr=spider&for=pc").text)
'''放假通知!原来,中秋和国庆之间还有一个节!放假通知!原来,中秋和国庆之间还有一个节!
大河客户端发布时间:09-1215:20大河传媒有限公司虽然刚刚开学没几天可是还是想说:中秋节、国庆节马上就到啦!
高速公路小客车是否免收通行费?快一起来了解!......'''
Supporting Reverse Generation of Regular Expressions:
>>> # 正则表达式逆向生成/Reverse Generation of Regular Expressions
>>> inputStr = ["http://www.huawei.com/cn/"]
>>> Matchers().generate_regular(inputStr,content)
'([a-z]{4}\\:/{2}[a-z]{3}\\.[a-z]{6}\\.[a-z]{3}/[a-z]{2}/)'
According to the complete label content input, it is extended to parse all the same attributes in the whole web page.:
>>> url = "https://xin.baidu.com/s?q=%E7%99%BE%E5%BA%A6"
>>> # 想要解析所有的企业法人,只需要输入一个法人即可。/If you want to analyze all corporate entities, you only need to enter a legal person.
>>> inputStr = '向海龙'
>>> doc = requests.get(url).content.decode()
>>> Matchers().match_data_by_content(inputStr,doc)
['百度', '梁志祥', '向海龙', '向海龙', '向海龙', '向海龙', '崔珊珊', '向海龙', '吴迪', '刘维', '李彦宏']
Pymatchers is ready for today's all type data string.
- Quickly parse web pages, JSON and text according to feature content.
- Supporting the reverse generation of regular expressions.
- Supporting the general parsing of web pages.
- Support one-click resolution of telephone number, IP, ID number, address, person name and link, etc.
pymatchers officially supports Python 3+, and runs great on PyPy.