-
Notifications
You must be signed in to change notification settings - Fork 2.6k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
feat: gen ai tuning and eval sample (#1628)
# Description Adds a sample Vertex AI Pipeline that tunes a Gemini model and then evaluates the tuned model against a previously-tuned model. --------- Co-authored-by: code-review-assist[bot] <182814678+code-review-assist[bot]@users.noreply.github.com> Co-authored-by: Holt Skinner <[email protected]> Co-authored-by: Holt Skinner <[email protected]>
- Loading branch information
4 people
authored
Jan 27, 2025
1 parent
8580052
commit aed6ebf
Showing
7 changed files
with
428 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
|
|
@@ -957,6 +957,7 @@ podcast | |
| podcasts | ||
| podfile | ||
| podhelper | ||
| podman | ||
| powerups | ||
| praw | ||
| prcntg | ||
|
|
||
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,6 @@ | ||
| __pycache__ | ||
| pipeline.json | ||
| venv | ||
| local/local_outputs | ||
| local/pipeline.json | ||
| local/venv |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,83 @@ | ||
| # Gen AI MLOps Tune and Evaluation | ||
|
|
||
| Author: [Chris Willis](https://github.com/willisc7) | ||
|
|
||
| This tutorial will take you through using Vertex AI Pipelines to automate tuning an LLM and evaluating it against a previously tuned LLM. The example used is an LLM that summarizes a week of glucose values for a diabetes patient. | ||
|
|
||
| 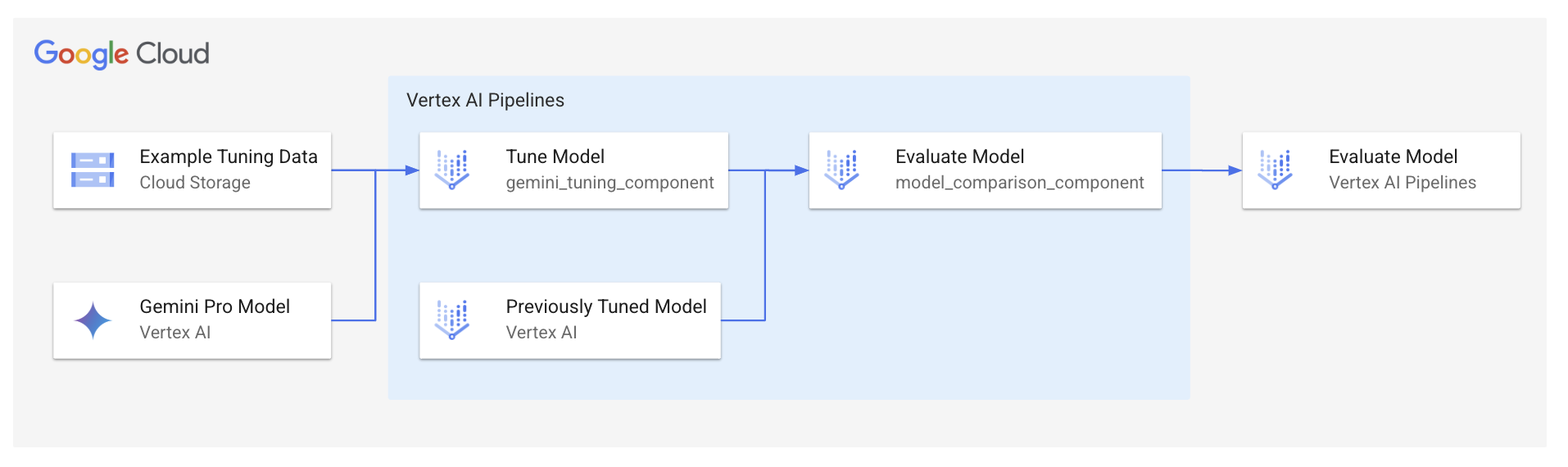 | ||
|
|
||
| ## Optional: Prepare the data | ||
|
|
||
| This step is optional because I've already prepared the data in `gs://github-repo/generative-ai/gemini/tuning/mlops-tune-and-eval/patient_1_glucose_examples.jsonl`. | ||
|
|
||
| - Create a week of glucose sample data for one patient using the following prompt with Gemini: | ||
|
|
||
| ```none | ||
| Create a CSV with a week's worth of example glucose values for a diabetic patient. The columns should be date, time, patient ID, and glucose value. Each day there should be timestamps for 7am, 8am, 11am, 12pm, 5pm, and 6pm. Most of the glucose values should be between 70 and 100. Some of the glucose values should be 100-150. | ||
| ``` | ||
|
|
||
| - Flatten the CSV by doing the following: | ||
| 1. Open the CSV | ||
| 2. Press Ctrl + a to select all text | ||
| 3. Press Alt + Shift + i to go to the end of each line | ||
| 4. Add a newline character (i.e. \n) | ||
| 5. Press Delete to squash it all to a single line | ||
| - Copy `glucose_examples_template.jsonl` (or create it if it doesn't exist) to `patient_X_glucose_examples.jsonl` | ||
| - Copy the flattened CSV and paste it into the patient_X_glucose_examples.jsonl | ||
| - Flatten the contents of the patient_X_glucose_examples.jsonl file using a JSON to JSONL converter online | ||
|
|
||
| ## Setup IAM, Tuning Examples, and Vertex AI Pipelines | ||
|
|
||
| - Grant Default Compute Service Account IAM permissions | ||
|
|
||
| ```sh | ||
| PROJECT_NUMBER=$(gcloud projects describe $(gcloud config get-value project) --format="value(projectNumber)") | ||
| SERVICE_ACCOUNT="${PROJECT_NUMBER}[email protected]" | ||
|
|
||
| gcloud projects add-iam-policy-binding $PROJECT_NUMBER \ | ||
| --member="serviceAccount:${SERVICE_ACCOUNT}" \ | ||
| --role="roles/aiplatform.user" | ||
| gcloud projects add-iam-policy-binding $PROJECT_NUMBER \ | ||
| --member="serviceAccount:${SERVICE_ACCOUNT}" \ | ||
| --role="roles/storage.objectUser" | ||
| ``` | ||
|
|
||
| - Enable the Cloud Resource Manager API | ||
|
|
||
| ```sh | ||
| gcloud services enable cloudresourcemanager.googleapis.com | ||
| ``` | ||
|
|
||
| - Create the pipeline root bucket | ||
|
|
||
| ```sh | ||
| gsutil mb gs://vertex-ai-pipeline-root-$(date +%Y%m%d) | ||
| ``` | ||
|
|
||
| ## Run Vertex AI Pipelines | ||
|
|
||
| - Install required packages and compile the pipeline | ||
|
|
||
| ```sh | ||
| python3 -m venv venv | ||
| source venv/bin/activate | ||
| pip install -r requirements.txt | ||
| kfp dsl compile --py pipeline.py --output pipeline.json | ||
| ``` | ||
|
|
||
| - Edit `pipeline.py` and change the following: | ||
|
|
||
| - `project` - change to your project ID | ||
|
|
||
| - Edit `submit_pipeline_job.py` and change the following: | ||
|
|
||
| - `pipeline_root` - change to the `gs://vertex-ai-pipeline-root-<DATETIME>` bucket you created earlier | ||
| - `project` - change to your project ID | ||
|
|
||
| - Create the pipeline run | ||
|
|
||
| ```sh | ||
| python submit_pipeline_job.py | ||
| ``` | ||
|
|
||
| - For subsequent runs, change `baseline_model_endpoint` in `submit_pipeline_job.py` to a tuned model endpoint you want to compare against (typically the previously trained endpoint) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,273 @@ | ||
| # pylint: disable=import-outside-toplevel,too-many-locals,too-many-arguments,too-many-positional-arguments,unused-argument | ||
| from typing import NamedTuple | ||
|
|
||
| from kfp.v2 import dsl | ||
| from kfp.v2.dsl import component | ||
|
|
||
|
|
||
| @component( | ||
| packages_to_install=["google-cloud-aiplatform", "vertexai"], | ||
| base_image="python:3.9", | ||
| ) | ||
| def gemini_tuning_component( | ||
| project: str, | ||
| location: str, | ||
| source_model: str, | ||
| train_dataset_uri: str, | ||
| ) -> str: | ||
| """Output the tuned model name as a string""" | ||
|
|
||
| import time | ||
|
|
||
| import vertexai | ||
| from vertexai.tuning import sft | ||
|
|
||
| vertexai.init(project=project, location=location) | ||
|
|
||
| tuned_model_display_name = f"tuned-{source_model}-{int(time.time())}" | ||
|
|
||
| sft_tuning_job = sft.train( | ||
| source_model=source_model, | ||
| train_dataset=train_dataset_uri, | ||
| tuned_model_display_name=tuned_model_display_name, | ||
| ) | ||
|
|
||
| while not sft_tuning_job.has_ended: | ||
| time.sleep(60) | ||
| sft_tuning_job.refresh() | ||
|
|
||
| print(f"Tuned Model Endpoint Name: {sft_tuning_job.tuned_model_endpoint_name}") | ||
| return sft_tuning_job.tuned_model_endpoint_name | ||
|
|
||
|
|
||
| @component( | ||
| packages_to_install=[ | ||
| "google-cloud-aiplatform", | ||
| "vertexai", | ||
| "plotly", | ||
| "pandas", | ||
| "IPython", | ||
| "google-cloud-aiplatform[evaluation]", | ||
| ], | ||
| base_image="python:3.9", | ||
| ) | ||
| def model_comparison_component( | ||
| project: str, | ||
| location: str, | ||
| baseline_model_endpoint: str, # Baseline model name | ||
| candidate_model_endpoint: str, # Candidate model name | ||
| ) -> NamedTuple("outputs", best_response=str, metrics=dict): # type: ignore[valid-type] | ||
| """Compares base model to newly tuned model""" | ||
| import functools | ||
| from functools import partial | ||
| import typing | ||
| from typing import Union | ||
| import uuid | ||
|
|
||
| import pandas as pd | ||
| from vertexai.evaluation import EvalResult, EvalTask, MetricPromptTemplateExamples | ||
| from vertexai.generative_models import GenerationConfig, GenerativeModel | ||
|
|
||
| experiment_name = "qa-quality" | ||
|
|
||
| def pairwise_greater( | ||
| instructions: str, | ||
| context: str, | ||
| project: str, | ||
| location: str, | ||
| experiment_name: str, | ||
| baseline: str, | ||
| candidate: str, | ||
| ) -> tuple: | ||
| """ | ||
| Takes Instructions, Context and two different responses. | ||
| Returns the response which best matches the instructions/Context for the given | ||
| quality metric ( in this case question answering). | ||
| More details on the web API and different quality metrics which this function | ||
| can be extended to can be found on | ||
| https://cloud.google.com/vertex-ai/generative-ai/docs/model-reference/evaluation | ||
| """ | ||
| eval_dataset = pd.DataFrame( | ||
| { | ||
| "instruction": [instructions], | ||
| "context": [context], | ||
| "response": [candidate], | ||
| "baseline_model_response": [baseline], | ||
| } | ||
| ) | ||
|
|
||
| eval_task = EvalTask( | ||
| dataset=eval_dataset, | ||
| metrics=[ | ||
| MetricPromptTemplateExamples.Pairwise.QUESTION_ANSWERING_QUALITY, | ||
| ], | ||
| experiment=experiment_name, | ||
| ) | ||
| results = eval_task.evaluate( | ||
| prompt_template="{instruction} \n {context}", | ||
| experiment_run_name="gemini-qa-pairwise-" + str(uuid.uuid4()), | ||
| ) | ||
| result = results.metrics_table[ | ||
| [ | ||
| "pairwise_question_answering_quality/pairwise_choice", | ||
| "pairwise_question_answering_quality/explanation", | ||
| ] | ||
| ].to_dict("records")[0] | ||
| choice = ( | ||
| baseline | ||
| if result["pairwise_question_answering_quality/pairwise_choice"] | ||
| == "BASELINE" | ||
| else candidate | ||
| ) | ||
| return (choice, result["pairwise_question_answering_quality/explanation"]) | ||
|
|
||
| def greater(cmp: typing.Callable, a: str, b: str) -> int: | ||
| """ | ||
| A comparison function which takes the comparison function, and two variables as input | ||
| and returns the one which is greater according to the logic defined inside the cmp function. | ||
| """ | ||
| choice, _ = cmp(a, b) | ||
|
|
||
| if choice == a: | ||
| return 1 | ||
| return -1 | ||
|
|
||
| def pointwise_eval( | ||
| instruction: str, | ||
| context: str, | ||
| responses: list[str], | ||
| eval_metrics: Union[list[MetricPromptTemplateExamples.Pointwise], None] = None, | ||
| experiment_name: str = experiment_name, | ||
| ) -> EvalResult: | ||
| """ | ||
| Takes the instruction, context and a variable number of corresponding | ||
| generated responses, and returns the pointwise evaluation metrics | ||
| for each of the provided metrics. For this example the metrics are | ||
| Q & A related, however the full list can be found on the website: | ||
| https://cloud.google.com/vertex-ai/generative-ai/docs/models/online-pipeline-services | ||
| """ | ||
|
|
||
| instructions = [instruction] * len(responses) | ||
|
|
||
| contexts = [context] * len(responses) | ||
|
|
||
| eval_dataset = pd.DataFrame( | ||
| { | ||
| "instruction": instructions, | ||
| "context": contexts, | ||
| "response": responses, | ||
| } | ||
| ) | ||
|
|
||
| eval_metrics = eval_metrics or [ | ||
| MetricPromptTemplateExamples.Pointwise.QUESTION_ANSWERING_QUALITY, | ||
| MetricPromptTemplateExamples.Pointwise.GROUNDEDNESS, | ||
| ] | ||
|
|
||
| eval_task = EvalTask( | ||
| dataset=eval_dataset, metrics=eval_metrics, experiment=experiment_name | ||
| ) | ||
| results = eval_task.evaluate( | ||
| prompt_template="{instruction} \n {context}", | ||
| experiment_run_name="gemini-qa-pointwise-" + str(uuid.uuid4()), | ||
| ) | ||
| return results | ||
|
|
||
| def rank_responses(instruction: str, context: str, responses: list[str]) -> tuple: | ||
| """ | ||
| Takes the instruction, context and a variable number of responses as | ||
| input, and returns the best performing response as well as its associated | ||
| human readable pointwise quality metrics for the configured criteria in the above functions. | ||
| The process consists of two steps: | ||
| 1. Selecting the best response by using Pairwise comparisons between the responses for | ||
| the user specified metric ( e.g. Q & A) | ||
| 2. Doing pointwise evaluation of the best response and returning human readable quality | ||
| metrics and explanation along with the best response. | ||
| """ | ||
| cmp_f = partial( | ||
| pairwise_greater, instruction, context, project, location, experiment_name | ||
| ) | ||
| cmp_greater = partial(greater, cmp_f) | ||
|
|
||
| pairwise_best_response = max(responses, key=functools.cmp_to_key(cmp_greater)) | ||
| pointwise_metric = pointwise_eval( | ||
| instruction, context, [pairwise_best_response] | ||
| ) | ||
| qa_metrics = pointwise_metric.metrics_table[ | ||
| [ | ||
| col | ||
| for col in pointwise_metric.metrics_table.columns | ||
| if ("question_answering" in col) or ("groundedness" in col) | ||
| ] | ||
| ].to_dict("records")[0] | ||
|
|
||
| return pairwise_best_response, qa_metrics | ||
|
|
||
| # Compare response from baseline model to candidate model to see which is better | ||
| generation_config = GenerationConfig( | ||
| temperature=0.4, | ||
| max_output_tokens=512, | ||
| ) | ||
| baseline_model = GenerativeModel( | ||
| baseline_model_endpoint, | ||
| generation_config=generation_config, | ||
| ) | ||
| candidate_model = GenerativeModel( | ||
| candidate_model_endpoint, | ||
| generation_config=generation_config, | ||
| ) | ||
|
|
||
| instruction_qa = "Analyze the glucose trends in the glucose values provided in the CSV contained in the context. Ensure the analysis you provide can easily be understood by a diabetes patient with no medical expertise." | ||
| context_qa = ( | ||
| "Context:\n" | ||
| + "```csv\ndate,time,patient ID,glucose\n2024-11-12,7:00 AM,1,80\n2024-11-12,8:00 AM,1,96\n2024-11-12,11:00 AM,1,90\n2024-11-12,12:00 PM,1,115\n2024-11-12,5:00 PM,1,77\n2024-11-12,6:00 PM,1,80\n2024-11-13,7:00 AM,1,94\n2024-11-13,8:00 AM,1,100\n2024-11-13,11:00 AM,1,87\n2024-11-13,12:00 PM,1,126\n2024-11-13,5:00 PM,1,71\n2024-11-13,6:00 PM,1,82\n2024-11-14,7:00 AM,1,84\n2024-11-14,8:00 AM,1,72\n2024-11-14,11:00 AM,1,96\n2024-11-14,12:00 PM,1,110\n2024-11-14,5:00 PM,1,99\n2024-11-14,6:00 PM,1,74\n2024-11-15,7:00 AM,1,96\n2024-11-15,8:00 AM,1,97\n2024-11-15,11:00 AM,1,99\n2024-11-15,12:00 PM,1,130\n2024-11-15,5:00 PM,1,99\n2024-11-15,6:00 PM,1,87\n2024-11-16,7:00 AM,1,89\n2024-11-16,8:00 AM,1,92\n2024-11-16,11:00 AM,1,77\n2024-11-16,12:00 PM,1,105\n2024-11-16,5:00 PM,1,79\n2024-11-16,6:00 PM,1,90\n2024-11-17,7:00 AM,1,74\n2024-11-17,8:00 AM,1,82\n2024-11-17,11:00 AM,1,74\n2024-11-17,12:00 PM,1,78\n2024-11-17,5:00 PM,1,95\n2024-11-17,6:00 PM,1,74\n2024-11-18,7:00 AM,1,95\n2024-11-18,8:00 AM,1,87\n2024-11-18,11:00 AM,1,79\n2024-11-18,12:00 PM,1,90\n2024-11-18,5:00 PM,1,79\n2024-11-18,6:00 PM,1,77\n" | ||
| ) | ||
| prompt_qa = instruction_qa + "\n" + context_qa + "\n\nAnswer:\n" | ||
|
|
||
| baseline_model_response = baseline_model.generate_content( | ||
| contents=prompt_qa, | ||
| ) | ||
| candidate_model_response = candidate_model.generate_content( | ||
| contents=prompt_qa, | ||
| ) | ||
| responses = [ | ||
| baseline_model_response.candidates[0].text, | ||
| candidate_model_response.candidates[0].text, | ||
| ] | ||
|
|
||
| best_response, metrics = rank_responses(instruction_qa, context_qa, responses) | ||
|
|
||
| for ix, response in enumerate(responses, start=1): | ||
| print(f"Response no. {ix}: \n {response}") | ||
|
|
||
| print(f"Best response: {best_response}") | ||
| print(f"Metrics: {metrics}") | ||
| outputs = NamedTuple("outputs", best_response=str, metrics=dict) # type: ignore[misc] | ||
| return outputs(best_response, metrics) # type: ignore[call-arg] | ||
|
|
||
|
|
||
| @dsl.pipeline(name="gemini-tuning-pipeline") | ||
| def gemini_tuning_pipeline( | ||
| project: str = "genai-mlops-tune-and-eval", | ||
| location: str = "us-central1", | ||
| source_model_name: str = "gemini-1.5-pro-002", | ||
| train_data_uri: str = "gs://github-repo/generative-ai/gemini/tuning/mlops-tune-and-eval/patient_1_glucose_examples.jsonl", | ||
| # For first run, set `baseline_model_endpoint`` to any tunable Gemini model | ||
| # because a tuned model endpoint doesn't exist yet | ||
| baseline_model_endpoint: str = "gemini-1.5-pro-002", | ||
| # For subsequent runs, set baseline_model_endpoint to a tuned model endpoint | ||
| # baseline_model_endpoint: str = "projects/824264063118/locations/us-central1/endpoints/797393320253849600", | ||
| ) -> None: | ||
| """Defines the pipeline to tune a model and compare it to the previously tuned model""" | ||
| tuning_task = gemini_tuning_component( | ||
| project=project, | ||
| location=location, | ||
| source_model=source_model_name, | ||
| train_dataset_uri=train_data_uri, | ||
| ) | ||
| model_comparison_component( | ||
| project=project, | ||
| location=location, | ||
| baseline_model_endpoint=baseline_model_endpoint, | ||
| candidate_model_endpoint=tuning_task.output, | ||
| ) |
Oops, something went wrong.