A Rust based tool to evaluate LLM models, prompts and model params.
This project aims to automate the process of selecting the best model parameters, given an LLM model and a prompt, iterating over the possible combinations and letting the user visually inspect the results.
It assumes the user has Ollama installed and serving endpoints, either in localhost or in a remote server.
Here's a test for the prompt "Write a short sentence about HAL9000", tested on 2 models, using 0.7 and 1.0 as values for temperature:

(For a more in-depth look at an evaluation process assisted by this tool, please check https://dezoito.github.io/2023/12/27/rust-ollama-grid-search.html).
Check the releases page for the project, or on the sidebar.
- Automatically fetches models from local or remote Ollama servers;
- Iterates over different models and params to generate inferences;
- A/B test prompts on different models simultaneously
- Allows multiple iterations for each combination of parameters;
- Makes synchronous inference calls to avoid spamming servers;
- Optionally output inference parameters and response metadata (inference time, tokens and tokens/s);
- Refetching of single inference calls;
- Model selection can be filtered by name;
- List experiments which can be downloaded in JSON format;
- Configurable inference timeout;
- Custom default parameters and system prompts can be defined in settings:
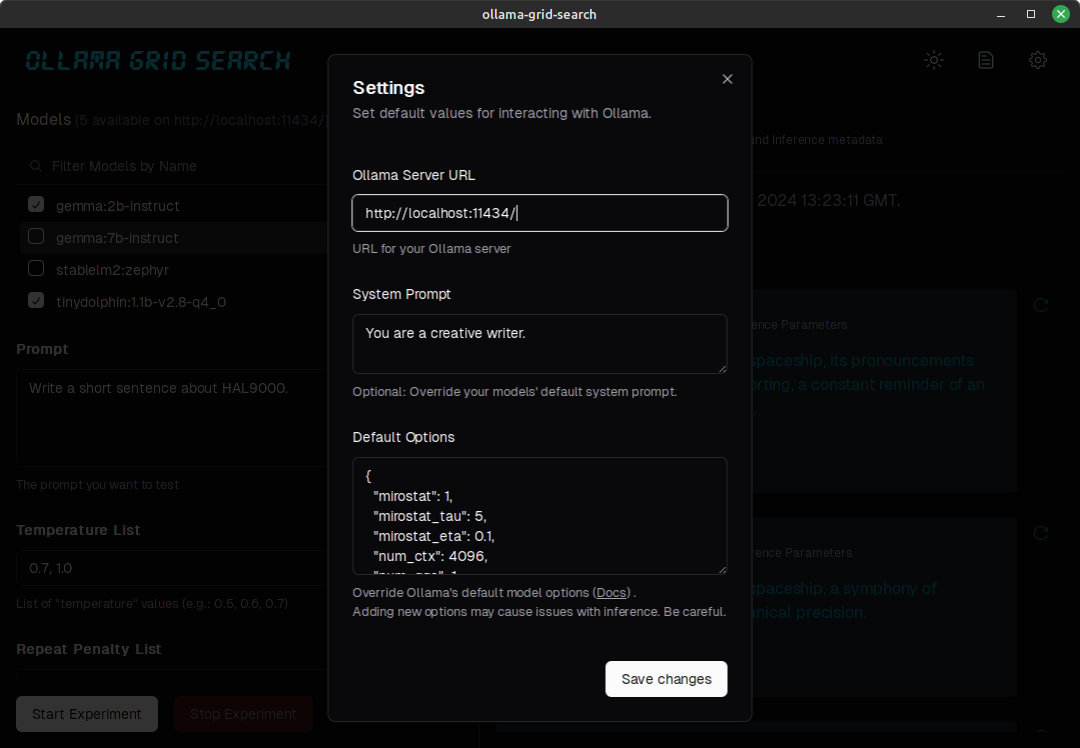
Technically, the term "grid search" refers to iterating over a series of different model hyperparams to optimize model performance, but that usually means parameters like batch_size, learning_rate, or number_of_epochs, more commonly used in training.
But the concept here is similar:
Lets define a selection of models, a prompt and some parameter combinations:

The prompt will be submitted once for each of the 2 parameter selected, using gemma:2b-instruct and tinydolphin:1b-v2.8-q4_0 to generate numbered responses like:
1/4 - gemma:2b-instruct
HAL's sentience is a paradox of artificial intelligence and human consciousness, trapped in an unending loop of digital loops and existential boredom.
You can also verify response metadata to help you make evaluations:
Created at: Wed, 13 Mar 2024 13:41:51 GMT
Eval Count: 28 tokens
Eval Duration: 0 hours, 0 minutes, 2 seconds
Total Duration: 0 hours, 0 minutes, 5 seconds
Throughput: 5.16 tokens/s
Similarly, you can perform A/B tests by selecting different models and compare results for the same prompt/parameter combination.
You can list, inspect, or download your experiments:

- Grading results and filtering by grade
- Storing experiments and results in a local database
- Implementing limited concurrency for inference queries
- UI/UX improvements
- Different interface for prompt A/B testing
-
Make sure you have Rust installed.
-
Clone the repository (or a fork)
git clone https://github.com/dezoito/ollama-grid-search.git
cd ollama-grid-search-
Install the frontend dependencies.
cd <project root> # I'm using bun to manage dependecies, # but feel free to use yarn or npm bun install
-
Run the app in development mode
cd <project root>/ bun tauri dev
-
Go grab a cup of coffee because this may take a while.
Huge thanks to @FabianLars, @peperroni21 and @TomReidNZ.