![]()

@vvatanabeです。Go言語を用いてDynamoDBをストレージに活用したメッセージキューイングのライブラリ、DynamoMQを開発しました。このライブラリは、Go言語でのコンシューマーおよびプロデューサーの実装を支援するSDKと、管理ツールとして機能するCLIを提供します。
この記事では、DynamoMQの開発動機、提供する機能、CLIやSDKの使用方法、そしてその設計についてご紹介します。
Note: この記事は、ヌーラボブログリレー2023 for Tech Advent Calendar 2023 – Adventar の最終日に掲載されたものです。
- DynamoDBの特性とMQのベースにする利点
- 既存のAWSキューイングソリューションとの比較
- DynamoMQがサポートする機能について
- DynamoMQのインストール方法
- DynamoMQのセットアップ方法
- DynamoMQの認証とクレデンシャル情報
- DynamoMQ CLIの使用方法
- DynamoMQ SDKの使用方法
- DynamoMQの設計について
- まとめ
- 謝辞
- 著者
- ライセンス
メッセージキュー(以下、MQ)を用いたシステムは、アプリケーション間でメッセージを非同期に伝達する目的で広く採用されています。これらのシステムでは、高いスループットと信頼性が特に重視されます。このセクションでは、DynamoDBの特性をMQシステムと組み合わせることの利点を考察します。
Amazon DynamoDBは、高性能なNoSQLデータベースサービスで、単純なキーバリューストアから複雑なドキュメント型のストアまで、幅広いデータモデルに対応しています。DynamoDBが持つ主な特徴は以下のとおりです。
- パフォーマンスとスケーラビリティ: DynamoDBはミリ秒単位で応答可能であり、必要に応じて自動的に読み書きのキャパシティをスケールアップ・ダウンできます。
- 高可用性と耐久性: データは自動的に複数の地理的に分散した施設にレプリケーションされるため、高度な可用性と耐久性を実現します。
- フルマネージドでサーバーレス: サーバーの管理や設定に関する手間がかからず、運用コストを削減できます。
DynamoDBのこれらの特性をMQシステムに応用することで、以下のようなメリットを享受できます。
- スケーラビリティ: 大量のメッセージを効率的に扱う能力は、MQシステムにとって極めて重要です。DynamoDBのオンデマンドモードにより、需要の変動に応じて容易にリソースを調整できます。
- コスト効率: オンデマンドモードを利用することで、リソースのオーバープロビジョニングやアンダープロビジョニングのリスクを低減し、コストを抑えることができます。さらに、使用量を予測できる場合にはプロビジョニングモードを選択することで、コストをさらに削減することも可能です。
- 信頼性と可用性: メッセージの喪失はMQにとって致命的です。DynamoDBの高い耐久性と可用性は、メッセージの安全性を保証します。
- 柔軟性: DynamoDBに保存されたメッセージの項目を編集することで、キュー内のメッセージの順序を動的に変更したり、属性を更新したり、メッセージの処理をキャンセルするなど、より柔軟な操作が可能になります。
AWSでは、MQに対して、Amazon SQS、Amazon MQ、そしてKafkaに基づくAmazon MSKなど、複数のソリューションを提供しています。これらのサービスとDynamoMQを比較することで、DynamoMQ独自の利点を考察します。
Amazon SQSはフルマネージドでサーバーレスなMQサービスであり、大規模な分散アプリケーションにおけるメッセージの非同期処理に広く利用されています。
スケーラビリティ、コスト効率、信頼性、そして可用性は非常に優れており、筆者の見解としては基本的にAmazon SQSの使用を推奨します。
しかし、Amazon SQSは柔軟性に欠ける面もあります。キューに送信されたメッセージは外部から順序を変更したり、メッセージの属性や項目を更新することができません。また、キュー内のメッセージを参照するには、一度受信する必要があります。これらの制約は、特定の問題に対処する際に調査や復旧作業を困難にすることがあります。
Amazon MQは、Apache ActiveMQやRabbitMQをベースにしたメッセージブローカーサービスで、既存のアプリケーションからの移行を主な目的としています。JMS、AMQP、STOMP、MQTT、OpenWire、WebSocketといった多様なプロトコルをサポートしています。
ベースとなるActiveMQやRabbitMQが提供する機能をそのまま利用できるため、Amazon MQは多くの機能を提供しています。しかし、Amazon MQはサーバーレスではないため、セットアップと管理には手間がかかります。
Amazon MSKは、Apache Kafkaをフルマネージドで提供するサービスで、大量のストリーミングデータ処理に適しています。
MSKはリアルタイムデータストリーミングに特化している一方で、DynamoMQは一般的なメッセージキューイングのニーズに焦点を当てています。また、MSKは高度な設定が可能ですが、それに伴い複雑さとコストが増加する傾向にあります。
DynamoMQは、DynamoDBのスケーラビリティ、耐久性、そしてサーバーレスという特性を活かし、従来のAWSキューイングソリューションと比較して、メッセージの順序や属性を柔軟に管理できる点、低コストでの運用、そして簡単なセットアップと管理などの優位性を持っています。
DynamoMQは、MQとして提供すべき主要な機能を備えており、柔軟かつ信頼性の高いシステムの実現を支援します。
メッセージが正常に処理されなかった場合に再配信を行います。これにより、一時的なエラーや処理の遅延に対応し、メッセージが確実に処理される機会を増やします。
複数のゴルーチンを使用して、メッセージの処理を並行して行います。この機能により、高スループットと効率的なリソース利用が可能になります。
再配信の最大回数を超えたメッセージをデッドレターキューに移動します。これにより、永続的なエラーを持つメッセージを分離し、後で分析や手動での処理を可能にします。
コンシューマプロセスのシャットダウン前にメッセージの処理を完了させます。これにより、プロセス終了時に処理中のメッセージが失われることを防ぎます。
FIFO(先入れ先出し)方式でメッセージをキューから取得します。これは、メッセージが送信された順序で処理されることを保証し、順序性が重要なアプリケーションに適しています。
複数のコンシューマプロセスを起動し、スケールアウトできます。同じメッセージキューからのメッセージを重複して取得することはありません。これにより、負荷に応じて処理能力を動的に調整できます。
一定期間、すべてのコンシューマによるメッセージの可視性タイムアウトを設定します。これにより、メッセージが処理中に他のコンシューマによって受信されることを防ぎます。
新しいメッセージの消費者への配信を設定した秒数だけ遅らせる遅延キューイングを提供します。
Goのバージョン1.21以上が必要です。
以下のgo installコマンドを使用して、このパッケージをCLIとしてインストールできます:
$ go install github.com/vvatanabe/dynamomq/cmd/dynamomq@latest
以下のgo getコマンドを使用して、このパッケージをSDKとしてインストールできます:
$ go get -u github.com/vvatanabe/dynamomq@latest
必要なIAMポリシーとテーブルの作成方法について説明します。
必要なIAMポリシーに関する詳細は、dynamomq-iam-policy.json または dynamomq-iam-policy.tf をご覧ください。
以下のコマンドを使用してAWS CLIでテーブルを作成します:
aws dynamodb create-table --cli-input-json file://dynamomq-table.json dynamomq-table.json をご覧ください。
詳細は、dynamomq-table.tf をご覧ください。
DynamoMQのCLIとSDKでは、外部の設定ソースから取得されたクレデンシャル情報を用います。設定のためのデフォルトソースは以下の通りです:
AWS_REGION- AWSリージョンを指定します。AWS_PROFILE- 使用するAWSプロファイルを指定します。AWS_ACCESS_KEY_ID- AWSアクセスキーを指定します。AWS_SECRET_ACCESS_KEY- AWSシークレットキーを指定します。AWS_SESSION_TOKEN- 一時的なクレデンシャルのセッショントークンを指定します。
DynamoMQ CLIは、DynamoDBベースのMQとやりとりするために一連のコマンドを提供しています。以下に、dynamomqで利用可能なコマンドとグローバルフラグを紹介します。
completion: 指定されたシェル用の自動補完スクリプトを生成し、コマンドの利用を容易にします。delete: IDを使ってキューからメッセージを削除します。dlq: デッドレターキュー(DLQ)の統計を取得し、メッセージ処理の失敗に関する情報を提供します。enqueue-test: IDがA-101、A-202、A-303、A-404のテストメッセージをDynamoDBテーブルに送信します。既存の同じIDのメッセージは上書きされます。fail: メッセージ処理の失敗をシミュレートし、メッセージをキューに戻します。get: IDを使ってDynamoDBテーブルから特定のメッセージを取得します。help: 各コマンドに関するヘルプ情報を表示します。invalid: スタンダードキューからDLQにメッセージを移動し、手動での確認と修正を行います。ls: キュー内の全てのメッセージのIDをリストを最大10要素を表示します。purge: DynamoMQテーブルから全てのメッセージを削除し、キューをクリアします。qstat: キューの統計情報を取得し、その現在の状態についての概要を提供します。receive: キューからメッセージを受信します。redrive: DLQからスタンダードキューへメッセージを戻し、再処理します。reset: メッセージのシステム情報をリセットします。
--endpoint-url: 特定のエンドポイントURLを指定してデフォルトのURLを上書きします。-h,--help:dynamomqに関するヘルプ情報を表示します。--queueing-index-name: 使用するキューインデックスの名前を指定します(デフォルトは"dynamo-mq-index-queue_type-sent_at")。--table-name: アイテムを格納するDynamoDBテーブルの名前を定義します(デフォルトは"dynamo-mq-table")。
特定のコマンドに関する詳細情報を取得するには、dynamomq [command] --helpを使用してください。
DynamoMQ CLIはインタラクティブモードをサポートしています。インタラクティブモードに入るには、サブコマンドを指定せずにdynamomqコマンドを実行します。
インタラクティブモードでは、以下のコマンドを提供します:
qstat: キューの統計情報を取得します。dlq: デッドレターキュー(DLQ)の統計情報を取得します。enqueue-testまたはet: IDがA-101、A-202、A-303、A-404のテストメッセージをDynamoDBテーブルに送信します。既存のメッセージが存在する場合は上書きされます。purge: DynamoMQテーブルから全てのメッセージを削除します。ls: 最大10要素までの全メッセージIDをリスト表示します。receive: キューからメッセージを受信します。id <id>: IDを指定して対象のメッセージに対して様々な操作を実行できるようにします:sys: メッセージのシステム情報をJSON形式で表示します。data: 現在のメッセージのdata部分ををJSONで出力します。info: メッセージに関する全情報をJSON形式で出力します。reset: メッセージのシステム情報をリセットします。redrive: DLQからスタンダードキューへメッセージを戻します。delete: IDを使ってメッセージを削除します。fail: キューに戻されるメッセージの処理失敗をシミュレートします。その後、メッセージは再受信できるようなります。invalid: スタンダードキューからDLQへメッセージを移動します。
DynamoMQは、Go言語用のSDKを提供し、コンシューマーとプロデューサーの実装をサポートします。以下に、DynamoMQライブラリを使用するための簡単な例を示します。詳細についてはGoDocを参照してください。
DynamoMQの利用を始めるには、まずAWS SDK for Go v2とDynamoMQから必要なパッケージをインポートします。これらは、AWSサービスとDynamoMQの機能にアクセスするために必要です。
import (
"github.com/aws/aws-sdk-go-v2/config"
"github.com/vvatanabe/dynamomq"
)次のコードブロックでDynamoMQクライアントを初期化します。AWSの設定を読み込み、その設定を使って新しいDynamoMQクライアントを作成します。ジェネリクスで指定している'ExampleData'を必要に応じて独自のデータ構造に置き換えてください。
ctx := context.Background()
cfg, err := config.LoadDefaultConfig(ctx)
if err != nil {
panic("failed to load aws config")
}
client, err := dynamomq.NewFromConfig[ExampleData](cfg)
if err != nil {
panic("AWS session could not be established!")
}DynamoMQで使用するデータ構造を定義します。'ExampleData'はDynamoDBのデータを表すために使用される構造体です。
type ExampleData struct {
Data1 string `dynamodbav:"data_1"`
Data2 string `dynamodbav:"data_2"`
Data3 string `dynamodbav:"data_3"`
}次のスニペットでは、'ExampleData'型のDynamoMQプロデューサーを作成し、事前に定義されたデータを持つメッセージをキューに送信します。
producer := dynamomq.NewProducer[ExampleData](client)
_, err = producer.Produce(ctx, &dynamomq.ProduceInput[ExampleData]{
Data: ExampleData{
Data1: "foo",
Data2: "bar",
Data3: "baz",
},
})
if err != nil {
panic("failed to produce message")
}メッセージを消費するために、'ExampleData'のDynamoMQコンシューマーをインスタンス化し、新しいゴルーチンで起動します。コンシューマーは、中断シグナルを受け取るまでメッセージを処理し続けます。以下の例には、コンシューマーのグレースフルシャットダウンのロジックが含まれています。
consumer := dynamomq.NewConsumer[ExampleData](client, &Counter[ExampleData]{})
go func() {
err = consumer.StartConsuming()
if err != nil {
fmt.Println(err)
}
}()
done := make(chan os.Signal, 1)
signal.Notify(done, os.Interrupt, syscall.SIGTERM)
<-done
ctx, cancel := context.WithTimeout(context.Background(), time.Minute)
defer cancel()
if err := consumer.Shutdown(ctx); err != nil {
fmt.Println("failed to consumer shutdown:", err)
}以下に、消費されたメッセージを処理するための'Counter'型を定義します。メッセージが処理されるたびにカウンターが増え、メッセージの詳細が表示されます。
type Counter[T any] struct {
Value int
}
func (c *Counter[T]) Process(msg *dynamomq.Message[T]) error {
c.Value++
fmt.Printf("value: %d, message: %v\n", c.Value, msg)
return nil
}DynamoMQの内部的な設計について説明します。
以下はDynamoMQがメッセージキューを実現するためのテーブル定義を示した図です。
| Key | Attributes | Type | Example Value |
|---|---|---|---|
| PK | id | string | A-101 |
| data | any | any | |
| receive_count | number | 1 | |
| GSIPK | queue_type | string | STANDARD or DLQ |
| version | number | 1 | |
| created_at | string | 2006-01-02T15:04:05.999999999Z07:00 | |
| updated_at | string | 2006-01-02T15:04:05.999999999Z07:00 | |
| GSISK | sent_at | string | 2006-01-02T15:04:05.999999999Z07:00 |
| received_at | string | 2006-01-02T15:04:05.999999999Z07:00 | |
| invisible_until_at | string | 2006-01-02T15:04:05.999999999Z07:00 |
このテーブル定義に基づき、各属性とグローバルセカンダリインデックス(以下、GSI)について解説します。
メッセージの一意な識別子で、DynamoDBのパーティションキーとして機能します。これによりDynamoDB内のデータの分散と効率的なアクセスが可能になります。DynamoMQのパブリッシャーを使用すると、デフォルトでUUIDが自動生成されます。ユーザーは独自のIDを指定することも可能です。
メッセージに含まれるデータの内容です。DynamoDBがサポートする任意の形式で保存できます。
参考:
メッセージが受信された回数を表します。この数値は再試行やデッドレターキューへの移動を管理する際に使用されます。
メッセージが保存されているキューのタイプを示します。スタンダードキュー(STANDARD)かデッドレターキュー(DLQ)かを区別します。
メッセージのバージョン番号です。メッセージが更新されるたびにこの数値は増加し、楽観的排他制御を実現します。
メッセージが作成された日時です。ISO 8601形式で記録されます。
メッセージが最後に更新された日時です。ISO 8601形式で記録されます。
メッセージがキューに送信された日時です。ISO 8601形式で記録されます。
メッセージが受信された日時です。ISO 8601形式で記録されます。
メッセージがキュー内で次に可視化される日時です。この時間が過ぎると、メッセージは再度受信可能になります。
キューに追加された順序でメッセージを受信するために、queue_typeをパーティションキーとし、sent_atをソートキーとするGSIが設定されています。
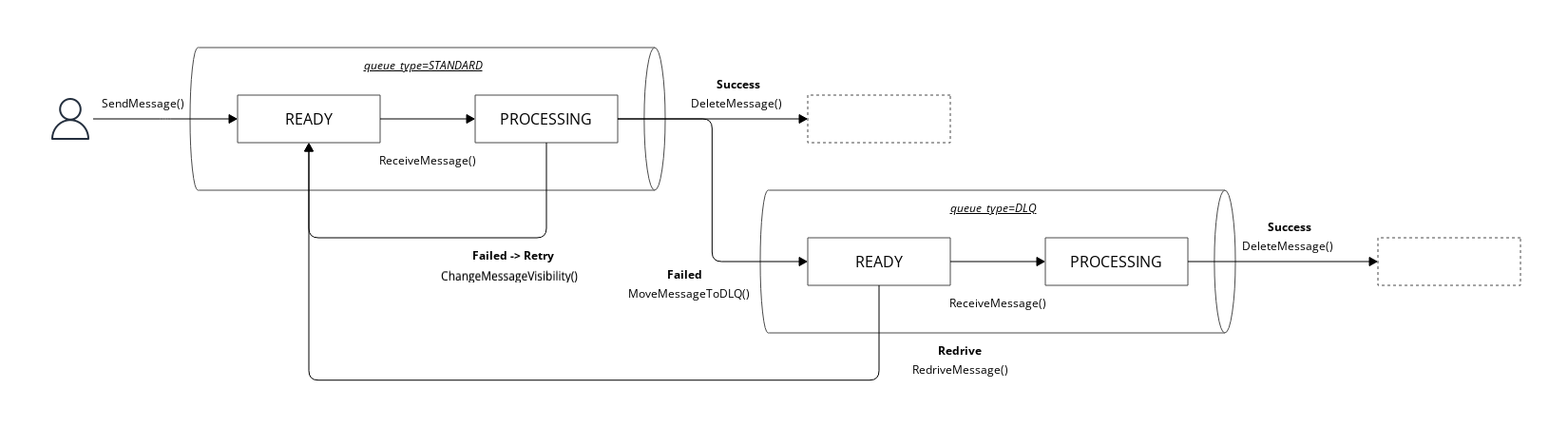
以下の状態遷移図は、DynamoMQにおけるメッセージのライフサイクルと、それが取りうる状態の遷移を示しています。図には、スタンダードキュー(queue_type=STANDARD)とデッドレターキュー(queue_type=DLQ)でのメッセージの処理方法が示されています。
また、以下の図ではメッセージの属性が状態遷移に伴いどのように変化するかを示しています。赤色で示された属性は状態遷移によって更新されます。
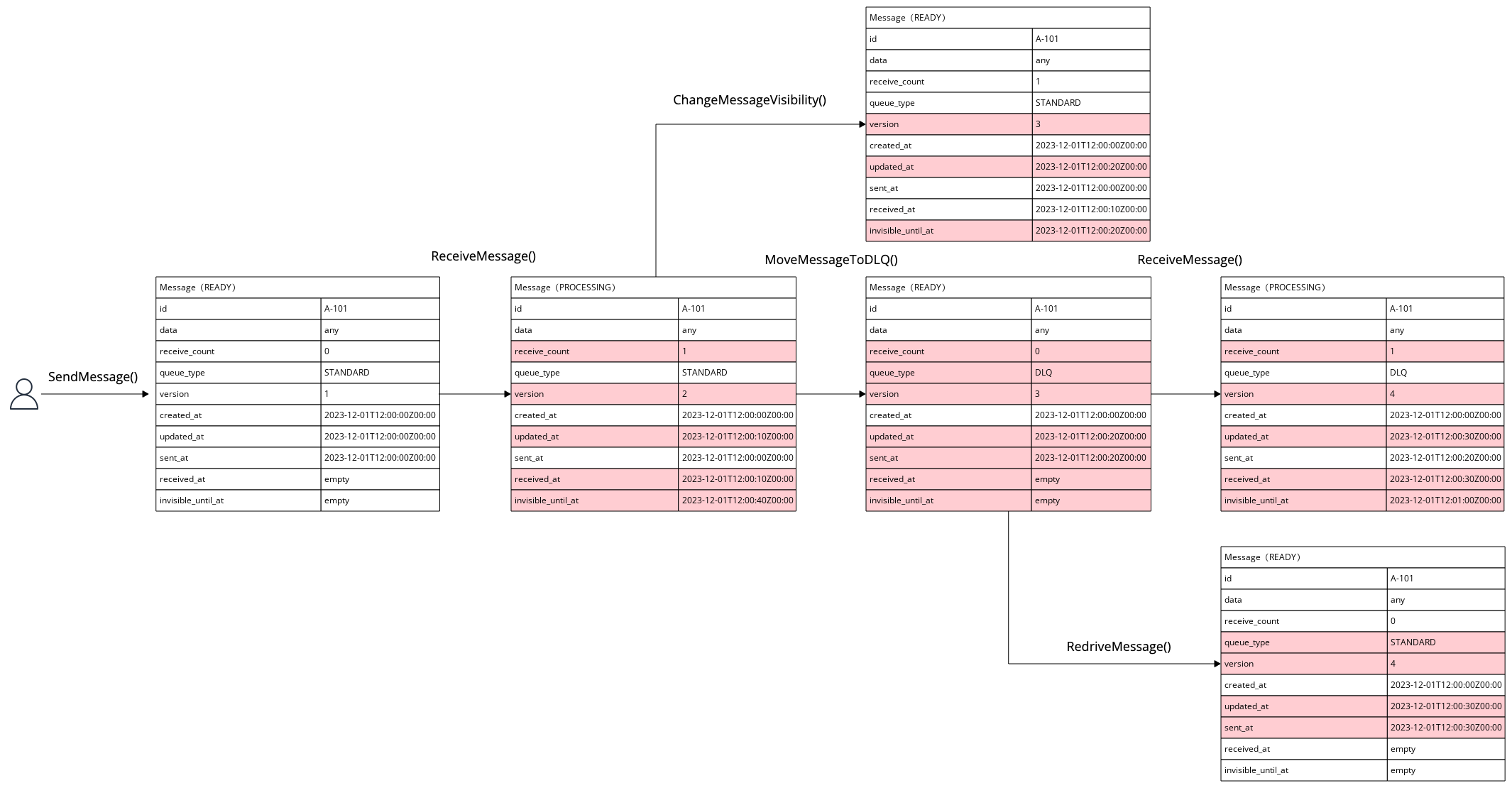
これらの図に示されたプロセスをステップバイステップで説明します。
-
メッセージの送信
- プロデューサーは、
SendMessage()関数を使用してスタンダードキューにメッセージを送信します。 - 送信されたメッセージは「READY」状態になり、これはメッセージが受信可能な状態を意味します。
- このメッセージには一意のIDが割り当てられ、
dataフィールドには処理されるべきデータが含まれます。 - メッセージの
queue_type属性はSTANDARDに設定され、バージョンは初期状態で1になります。 created_at、updated_at、sent_atのタイムスタンプが記録されます。
- プロデューサーは、
-
メッセージの受信
- コンシューマーは、
ReceiveMessage()関数を利用してメッセージを受信し、処理を開始します。 - メッセージは「PROCESSING」状態に移行し、この期間中は他のコンシューマーからは見えなくなり、受信されなくなります。
- メッセージの
receive_countとversionはそれぞれ受信の度にインクリメントされます。 updated_at、received_atのタイムスタンプが更新され、invisible_until_atが新しい日時で設定されます。
- コンシューマーは、
-
処理の成功
- 処理が成功した場合、コンシューマーは
DeleteMessage()関数を使用してメッセージをキューから削除します。
- 処理が成功した場合、コンシューマーは
-
処理の失敗
- 処理に失敗した場合、特にリトライが必要な場合は、
ChangeMessageVisibility()を使用してメッセージのinvisible_until_at属性を更新し、後で再処理できるようにします。 invisible_until_atの設定された日時が過ぎれば、メッセージは再び「READY」状態に戻り、再度受信が可能になります。
- 処理に失敗した場合、特にリトライが必要な場合は、
-
DLQへの移動
- メッセージの処理が最大再配信回数を超えて失敗すると、
MoveMessageToDLQ()関数によってメッセージはデッドレターキュー(DLQ)に移動されます。 - この時、メッセージの
queue_typeはDLQに変更され、receive_countは0にリセットされます。 - DLQに移動されたメッセージは、再び「READY」状態に戻ります。
- メッセージの処理が最大再配信回数を超えて失敗すると、
-
メッセージの受信
- DLQ内で、メッセージは再び
ReceiveMessage()によって受信され、PROCESSING状態に遷移します。 - この期間中、メッセージは他のコンシューマーからは見えなくなります。
- DLQ内で、メッセージは再び
-
処理の成功
- メッセージが正常に処理されると、
DeleteMessage()によってDLQから削除されます。
- メッセージが正常に処理されると、
-
スタンダードキューへの移動
RedriveMessage()を使用してメッセージを元のスタンダードキューに戻すことも可能です。- この操作により、
queue_typeは再びSTANDARDに設定され、メッセージは「READY」状態に戻ります。
DynamoMQは、DynamoDBの特性を生かし、高いスケーラビリティ、信頼性、およびコスト効率を実現するメッセージキューのライブラリです。特に、メッセージの順序変更や属性を動的に編集できる点は、アプリケーションの要求を柔軟に対応することを可能にします。
既存のソリューションと比較して、DynamoMQは開発者にとって管理が容易でありながら、Amazon SQSのようなフルマネージドサービスの信頼性を提供します。また、複数のゴルーチンによる並列実行処理や、デッドレターキュー、FIFO順序の保証など、メッセージキューが提供すべき主要な機能を網羅しています。
DynamoMQの開発にあたり参考とさせていただいたAWSの公式ブログ「Implementing priority queueing with Amazon DynamoDB」に深く感謝申し上げます。このブログでは、Amazon DynamoDBを使用した優先度付きキューイングの実装方法が詳細に解説されており、その知識がDynamoMQの構築に非常に役立ちました。
- vvatanabe - 主要な貢献者
このプロジェクトはMITライセンスです。詳細なライセンス情報については、リポジトリに含まれるLICENSEファイルを参照してください。