이 폴더에는 모호성 해소 성능을 평가하기 위한 코드와 데이터가 있습니다. 평가 데이터는 testset 폴더 안에 있으며 다음과 같이 구성되어 있습니다.
- irregular_verbs(불규칙활용): 형태가 동일한 불규칙 활용 동사와 규칙 활용 동사를 구분하는 평가
- verb_vs_adj(동/형용사): 형태가 동일한 동사와 형용사를 구분하는 평가
- nouns(명사): 헷갈리기 쉬운 명사 + 조사 조합을 구분하는 평가
- distant(장거리): 위의 평가셋에서 문장의 길이를 늘려 난이도를 높인 평가
또한 다음 평가 코드를 제공합니다.
- disambiguate.py:
Kiwi및 다른 형태소 분석기의 성능을 평가합니다.
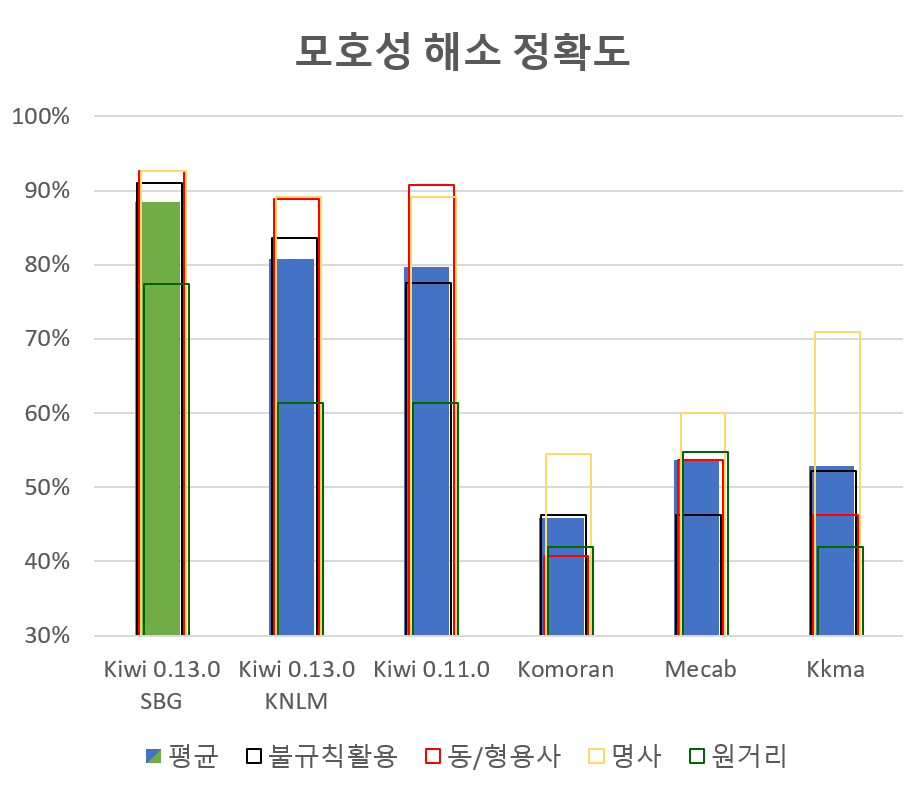
Kiwi가 다른 형태소 분석기에 비해 압도적으로 높은 정확도를 보임을 확인할 수 있습니다.
다른 형태소 분석기를 테스트하기 위해서는 konlpy가 필요합니다. 특히 Mecab을 이용시 split_inflect 기능 패치가 추가된 konlpy 버전이 필요합니다.
$ python disambiguate.py testset/*.txt --target=kiwi,komoran,mecab,kkma,hannanum,okt --error_output_dir=errors/
Initialize kiwipiepy (0.11.0)
Initialize Komoran from konlpy (0.6.0)
Initialize Mecab from konlpy (0.6.0)
Initialize Kkma from konlpy (0.6.0)
Initialize Hannanum from konlpy (0.6.0)
Initialize Okt from konlpy (0.6.0)
kiwi komoran mecab kkma hannanum okt
irregular_verbs.txt 0.776 0.463 0.463 0.522 0.463 0.463
verb_vs_adj.txt 0.907 0.407 0.537 0.463 - -
nouns.txt 0.891 0.545 0.600 0.709 0.473 0.527
distant.txt 0.613 0.419 0.548 0.419 - -Hannanum과 Okt의 경우 동사와 형용사를 별도로 구분하는 기능이 없어서 verb_vs_adj이나 distant 평가에서 점수를 매기지 않습니다.