Home
During hackweek interstellar I evaluated using the boost graph library (BGL). You should be familiar with the basics of graph theory and BGL when looking at libstorage-bgl-eval. The code is of prototype quality.
There are two use-cases for graphs in libstorage. The first are the devices themself, the second and even more interesting are the actions performed when committing the queued changes to the system.
Storing the devices in libstorage as a graph looks like a natural approach.
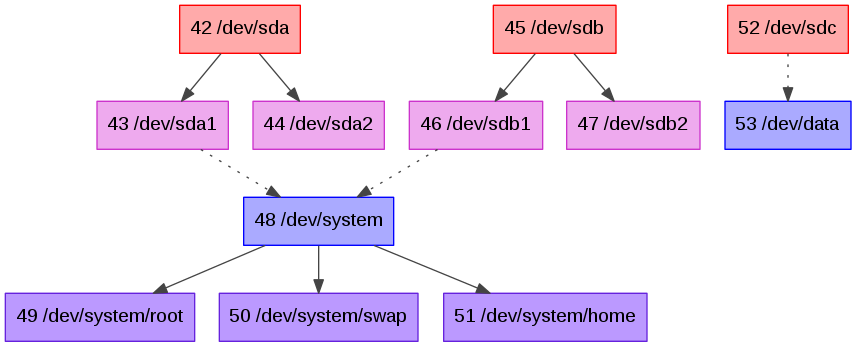
You might have seen the diagram above in YaST. But here it is a direct dump of internal data structure instead of a cumbersome transformation.
The graph approach has several advantages compared to the current list of list design:
-
No pseudo containers for e.g. MD RAID, tmpfs or NFS are needed.
-
Possibility to have special objects for IMSM and DDF RAID containers.
-
Some operations are trivial compared to the current libstorage, e.g. getting all devices using a device is just a plain BFS.
Together with a redesign of the current objects several features would be simple, e.g. using unpartitioned disks for filesystems, renaming LVM volume groups and logical volumes, switching between partitioned and unpartitioned MD RAID.
When committing the queued changes to the system libstorage has to analyse what steps are needed and in which order they must be done. Unfortunately the code here has evolved and some if statements span several lines of code. Unfortunately bugs are also frequent here.
The new approach looks different:
-
Two device graphs (the first is the current system, the second the staging system) are compared and the required steps are stored as vertices of a graph. E.g. a step is to create a partition.
-
Dependencies are added as edges in the graph. E.g. when creating two partitions on a disk the ordering is important (otherwise the partition numbers get swapped).
-
A topological sort calculates the order in which the steps can be executed.
Here is a simply action graph for deleting a volume group with one logical volume and two physical volumes.

Legend: The color indicates whether an action creates (green), modifies (blue) or deletes (red) and object. The leading number is the unique storage id. The characters in squared brackets show whether it is the first [f] or last [l] step for the object.
I see several advantages of the new approach:
-
Better testability: The code to generate the actions and their dependencies can be checked in a testsuite (some testcases already exists). Only testing the actions themself needs to be done on an actual system.
-
Checking the dependencies instead of the ordering is more robust. The ordering can be correct "by luck" while dependencies are explicit.
-
The topological sort can also be used to find actions that can be done in parallel. This might be used for filesystem creation (although newer filesystems (e.g. btrfs, xfs, ext4) have fast mkfs commands).
Here is a more complex action graph with dependencies for partition creation.

Here is a even more complex action graph with dependencies for partition creation and mount ordering. One filesystem is mounted twice resulting in cross device dependencies. AFAIS the old approach cannot handle such complex situations and it would be very difficult to implement them.

The nop is added as a synchronization point in case an action depends on all mount points of /dev/sda1 being done. Whether that is really needed I cannot say yet.
When you compile libstorage-bgl-eval you can find more action graphs in the examples directory.
The library has several testsuites.
-
Device graph: Checks basic manipulation of device graphs, e.g. adding or removing objects and copying graphs.
-
Dependencies: Checks the action graph after comparing system and staging device graphs.
-
SystemInfo: Checks parsers for external commands.
-
Probe: Mocks external commands (SystemInfo) and checks that the probed device graph is correct.
-
Utils: Checks utulity functions, e.g. parsing sizes and udev encoding names.
-
Python, Ruby, Perl Bindings: Since these are SWIG generated the scope is to test every concept, e.g. execptions, runtime polymorphism and data types (input, output and ranges).
-
Integration tests: Small Python scripts that test one or a few commit actions. Not run automatically yet.
The prototype only supports some actions for disks, partitions and filesystems so far. A compatibility layer to provide the legacy interface just handles some functions needed by YaST.
However this is already enough to make the most simple installation (starting with an empty disk and no LVM) work in YaST. Below you can see the installation summary (which is currently more detailed than in the past).
