diff --git a/.github/workflows/build.yml b/.github/workflows/build.yml
index 17f15a03f..11732c819 100644
--- a/.github/workflows/build.yml
+++ b/.github/workflows/build.yml
@@ -32,11 +32,8 @@ jobs:
strategy:
matrix:
python-version: [3.7]
- torch: [1.5.0, 1.6.0, 1.7.0, 1.8.0, 1.9.0]
+ torch: [1.6.0, 1.7.0, 1.8.0, 1.9.0]
include:
- - torch: 1.5.0
- torch_version: 1.5
- torchvision: 0.6.0
- torch: 1.6.0
torch_version: 1.6
torchvision: 0.7.0
@@ -88,7 +85,7 @@ jobs:
run: |
coverage run --branch --source mmselfsup -m pytest tests/
coverage xml
- coverage report -m --omit="mmselfsup/apis/*"
+ coverage report -m
# Only upload coverage report for python3.8 && pytorch1.9.0
- name: Upload coverage to Codecov
if: ${{matrix.torch == '1.9.0' && matrix.python-version == '3.8'}}
diff --git a/.gitignore b/.gitignore
index 0c7c355e1..3c319c23b 100644
--- a/.gitignore
+++ b/.gitignore
@@ -121,6 +121,7 @@ tensorboard.sh
replace.sh
benchmarks/detection/datasets
benchmarks/detection/output
+INFO
# Pytorch
*.pth
diff --git a/README.md b/README.md
index 7797fc08a..e2f493d8b 100644
--- a/README.md
+++ b/README.md
@@ -66,13 +66,12 @@ This project is released under the [Apache 2.0 license](LICENSE).
## ChangeLog
-MMSelfSup **v0.8.0** was released in 31/03/2022.
+MMSelfSup **v0.9.0** was released in 29/04/2022.
Highlights of the new version:
-* Support **SimMIM**
-* Add **KNN** benchmark, support KNN test with checkpoint and extracted backbone weights
-* Support ImageNet-21k dataset
+* Support **CAE**
+* Support **Barlow Twins**
Please refer to [changelog.md](docs/en/changelog.md) for details and release history.
@@ -97,9 +96,11 @@ Supported algorithms:
- [x] [SwAV (NeurIPS'2020)](https://arxiv.org/abs/2006.09882)
- [x] [DenseCL (CVPR'2021)](https://arxiv.org/abs/2011.09157)
- [x] [SimSiam (CVPR'2021)](https://arxiv.org/abs/2011.10566)
+- [x] [Barlow Twins (ICML'2021)](https://arxiv.org/abs/2103.03230)
- [x] [MoCo v3 (ICCV'2021)](https://arxiv.org/abs/2104.02057)
- [x] [MAE](https://arxiv.org/abs/2111.06377)
- [x] [SimMIM](https://arxiv.org/abs/2111.09886)
+- [x] [CAE](https://arxiv.org/abs/2202.03026)
More algorithms are in our plan.
@@ -121,7 +122,7 @@ More algorithms are in our plan.
## Installation
-MMSelfSup depends on [PyTorch](https://pytorch.org/)], [MMCV](https://github.com/open-mmlab/mmcv) and [MMClassification](https://github.com/open-mmlab/mmclassification).
+MMSelfSup depends on [PyTorch](https://pytorch.org/), [MMCV](https://github.com/open-mmlab/mmcv) and [MMClassification](https://github.com/open-mmlab/mmclassification).
Please refer to [install.md](docs/en/install.md) for more detailed instruction.
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 4a47441c5..35631f512 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -64,13 +64,12 @@ MMSelfSup 是一个基于 PyTorch 实现的开源自监督表征学习工具箱
## 更新日志
-最新的 **v0.8.0** 版本已经在 2022.03.31 发布。
+最新的 **v0.9.0** 版本已经在 2022.04.29 发布。
新版本亮点:
-* 支持 **SimMIM**
-* 增加 **KNN** 基准测试,支持中间 checkpoint 和提取的 backbone 权重进行评估
-* 支持 ImageNet-21k 数据集
+* 支持 **CAE**
+* 支持 **Barlow Twins**
请参考 [更新日志](docs/zh_cn/changelog.md) 获取更多细节和历史版本信息。
@@ -96,9 +95,11 @@ MMSelfSup 和 OpenSelfSup 的不同点写在 [对比文档](docs/en/compatibilit
- [x] [SwAV (NeurIPS'2020)](https://arxiv.org/abs/2006.09882)
- [x] [DenseCL (CVPR'2021)](https://arxiv.org/abs/2011.09157)
- [x] [SimSiam (CVPR'2021)](https://arxiv.org/abs/2011.10566)
+- [x] [Barlow Twins (ICML'2021)](https://arxiv.org/abs/2103.03230)
- [x] [MoCo v3 (ICCV'2021)](https://arxiv.org/abs/2104.02057)
- [x] [MAE](https://arxiv.org/abs/2111.06377)
- [x] [SimMIM](https://arxiv.org/abs/2111.09886)
+- [x] [CAE](https://arxiv.org/abs/2202.03026)
更多的算法实现已经在我们的计划中。
@@ -120,7 +121,7 @@ MMSelfSup 和 OpenSelfSup 的不同点写在 [对比文档](docs/en/compatibilit
## 安装
-MMSelfSup 依赖 [PyTorch](https://pytorch.org/)], [MMCV](https://github.com/open-mmlab/mmcv) 和 [MMClassification](https://github.com/open-mmlab/mmclassification).
+MMSelfSup 依赖 [PyTorch](https://pytorch.org/), [MMCV](https://github.com/open-mmlab/mmcv) 和 [MMClassification](https://github.com/open-mmlab/mmclassification).
请参考 [安装文档](docs/zh_cn/install.md) 获取更详细的安装指南。
diff --git a/configs/benchmarks/classification/_base_/datasets/imagenet.py b/configs/benchmarks/classification/_base_/datasets/imagenet.py
index a4400aa4c..410397593 100644
--- a/configs/benchmarks/classification/_base_/datasets/imagenet.py
+++ b/configs/benchmarks/classification/_base_/datasets/imagenet.py
@@ -30,8 +30,7 @@
data_source=dict(
type=data_source,
data_prefix='data/imagenet/train',
- ann_file='data/imagenet/meta/train.txt',
- ),
+ ann_file='data/imagenet/meta/train.txt'),
pipeline=train_pipeline,
prefetch=prefetch),
val=dict(
@@ -39,8 +38,7 @@
data_source=dict(
type=data_source,
data_prefix='data/imagenet/val',
- ann_file='data/imagenet/meta/val.txt',
- ),
+ ann_file='data/imagenet/meta/val.txt'),
pipeline=test_pipeline,
prefetch=prefetch))
evaluation = dict(interval=10, topk=(1, 5))
diff --git a/configs/benchmarks/classification/imagenet/resnet50-sobel_8xb32-steplr-100e_in1k.py b/configs/benchmarks/classification/imagenet/resnet50-sobel_linear-8xb32-steplr-100e_in1k.py
similarity index 64%
rename from configs/benchmarks/classification/imagenet/resnet50-sobel_8xb32-steplr-100e_in1k.py
rename to configs/benchmarks/classification/imagenet/resnet50-sobel_linear-8xb32-steplr-100e_in1k.py
index d0f759291..f8fb3b2df 100644
--- a/configs/benchmarks/classification/imagenet/resnet50-sobel_8xb32-steplr-100e_in1k.py
+++ b/configs/benchmarks/classification/imagenet/resnet50-sobel_linear-8xb32-steplr-100e_in1k.py
@@ -1,4 +1,4 @@
-_base_ = 'resnet50_8xb32-steplr-100e_in1k.py'
+_base_ = 'resnet50_linear-8xb32-steplr-100e_in1k.py'
# model settings
model = dict(with_sobel=True, backbone=dict(in_channels=2, frozen_stages=4))
diff --git a/configs/benchmarks/classification/imagenet/resnet50-sobel_mhead_8xb32-steplr-90e_in1k.py b/configs/benchmarks/classification/imagenet/resnet50-sobel_mhead_linear-8xb32-steplr-90e_in1k.py
similarity index 62%
rename from configs/benchmarks/classification/imagenet/resnet50-sobel_mhead_8xb32-steplr-90e_in1k.py
rename to configs/benchmarks/classification/imagenet/resnet50-sobel_mhead_linear-8xb32-steplr-90e_in1k.py
index 5047ac10c..37a434185 100644
--- a/configs/benchmarks/classification/imagenet/resnet50-sobel_mhead_8xb32-steplr-90e_in1k.py
+++ b/configs/benchmarks/classification/imagenet/resnet50-sobel_mhead_linear-8xb32-steplr-90e_in1k.py
@@ -1,4 +1,4 @@
-_base_ = 'resnet50_mhead_8xb32-steplr-90e_in1k.py'
+_base_ = 'resnet50_mhead_linear-8xb32-steplr-90e_in1k.py'
# model settings
model = dict(with_sobel=True, backbone=dict(in_channels=2, frozen_stages=4))
diff --git a/configs/benchmarks/classification/imagenet/resnet50-nofrz_8xb32-steplr-90e_in1k.py b/configs/benchmarks/classification/imagenet/resnet50_8xb32-steplr-90e_in1k.py
similarity index 100%
rename from configs/benchmarks/classification/imagenet/resnet50-nofrz_8xb32-steplr-90e_in1k.py
rename to configs/benchmarks/classification/imagenet/resnet50_8xb32-steplr-90e_in1k.py
diff --git a/configs/benchmarks/classification/imagenet/resnet50_8xb32-coslr-100e_in1k.py b/configs/benchmarks/classification/imagenet/resnet50_linear-8xb32-coslr-100e_in1k.py
similarity index 93%
rename from configs/benchmarks/classification/imagenet/resnet50_8xb32-coslr-100e_in1k.py
rename to configs/benchmarks/classification/imagenet/resnet50_linear-8xb32-coslr-100e_in1k.py
index c9d4d546a..e63c2bbd2 100644
--- a/configs/benchmarks/classification/imagenet/resnet50_8xb32-coslr-100e_in1k.py
+++ b/configs/benchmarks/classification/imagenet/resnet50_linear-8xb32-coslr-100e_in1k.py
@@ -4,10 +4,10 @@
'../_base_/schedules/sgd_coslr-100e.py',
'../_base_/default_runtime.py',
]
+# SwAV linear evaluation setting
model = dict(backbone=dict(frozen_stages=4))
-# swav setting
# runtime settings
# the max_keep_ckpts controls the max number of ckpt file in your work_dirs
# if it is 3, when CheckpointHook (in mmcv) saves the 4th ckpt
diff --git a/configs/benchmarks/classification/imagenet/resnet50_8xb32-steplr-100e_in1k.py b/configs/benchmarks/classification/imagenet/resnet50_linear-8xb32-steplr-100e_in1k.py
similarity index 94%
rename from configs/benchmarks/classification/imagenet/resnet50_8xb32-steplr-100e_in1k.py
rename to configs/benchmarks/classification/imagenet/resnet50_linear-8xb32-steplr-100e_in1k.py
index a0bb07ec2..3a7795a05 100644
--- a/configs/benchmarks/classification/imagenet/resnet50_8xb32-steplr-100e_in1k.py
+++ b/configs/benchmarks/classification/imagenet/resnet50_linear-8xb32-steplr-100e_in1k.py
@@ -4,12 +4,12 @@
'../_base_/schedules/sgd_steplr-100e.py',
'../_base_/default_runtime.py',
]
+# MoCo v1/v2 linear evaluation setting
model = dict(backbone=dict(frozen_stages=4))
evaluation = dict(interval=1, topk=(1, 5))
-# moco setting
# optimizer
optimizer = dict(type='SGD', lr=30., momentum=0.9, weight_decay=0.)
diff --git a/configs/benchmarks/classification/imagenet/resnet50_8xb512-coslr-90e_in1k.py b/configs/benchmarks/classification/imagenet/resnet50_linear-8xb512-coslr-90e_in1k.py
similarity index 67%
rename from configs/benchmarks/classification/imagenet/resnet50_8xb512-coslr-90e_in1k.py
rename to configs/benchmarks/classification/imagenet/resnet50_linear-8xb512-coslr-90e_in1k.py
index ea9d8ceea..2742bf133 100644
--- a/configs/benchmarks/classification/imagenet/resnet50_8xb512-coslr-90e_in1k.py
+++ b/configs/benchmarks/classification/imagenet/resnet50_linear-8xb512-coslr-90e_in1k.py
@@ -4,13 +4,17 @@
'../_base_/schedules/lars_coslr-90e.py',
'../_base_/default_runtime.py',
]
+# SimSiam linear evaluation setting
+# According to SimSiam paper, this setting can also be used to evaluate
+# other methods like SimCLR, MoCo, BYOL, SwAV
model = dict(backbone=dict(frozen_stages=4))
# dataset summary
-data = dict(samples_per_gpu=512) # total 512*8=4096, 8GPU linear cls
+data = dict(
+ samples_per_gpu=512,
+ workers_per_gpu=8) # total 512*8=4096, 8GPU linear cls
-# simsiam setting
# runtime settings
# the max_keep_ckpts controls the max number of ckpt file in your work_dirs
# if it is 3, when CheckpointHook (in mmcv) saves the 4th ckpt
diff --git a/configs/benchmarks/classification/imagenet/resnet50_mhead_8xb32-steplr-90e_in1k.py b/configs/benchmarks/classification/imagenet/resnet50_mhead_linear-8xb32-steplr-90e_in1k.py
similarity index 79%
rename from configs/benchmarks/classification/imagenet/resnet50_mhead_8xb32-steplr-90e_in1k.py
rename to configs/benchmarks/classification/imagenet/resnet50_mhead_linear-8xb32-steplr-90e_in1k.py
index 16cc862d3..c569c7fd8 100644
--- a/configs/benchmarks/classification/imagenet/resnet50_mhead_8xb32-steplr-90e_in1k.py
+++ b/configs/benchmarks/classification/imagenet/resnet50_mhead_linear-8xb32-steplr-90e_in1k.py
@@ -4,6 +4,7 @@
'../_base_/schedules/sgd_steplr-100e.py',
'../_base_/default_runtime.py',
]
+# Multi-head linear evaluation setting
model = dict(backbone=dict(frozen_stages=4))
@@ -45,4 +46,8 @@
# runtime settings
runner = dict(type='EpochBasedRunner', max_epochs=90)
-checkpoint_config = dict(interval=10)
+
+# the max_keep_ckpts controls the max number of ckpt file in your work_dirs
+# if it is 3, when CheckpointHook (in mmcv) saves the 4th ckpt
+# it will remove the oldest one to keep the number of total ckpts as 3
+checkpoint_config = dict(interval=10, max_keep_ckpts=3)
diff --git a/configs/benchmarks/classification/imagenet/swin-base_ft-8xb256-coslr-100e_in1k-224.py b/configs/benchmarks/classification/imagenet/swin-base_ft-8xb256-coslr-100e_in1k-224.py
new file mode 100644
index 000000000..d69ea5d0e
--- /dev/null
+++ b/configs/benchmarks/classification/imagenet/swin-base_ft-8xb256-coslr-100e_in1k-224.py
@@ -0,0 +1,34 @@
+_base_ = 'swin-base_ft-8xb256-coslr-100e_in1k.py'
+
+# model
+model = dict(
+ backbone=dict(
+ img_size=224, stage_cfgs=dict(block_cfgs=dict(window_size=7))))
+
+# dataset
+img_norm_cfg = dict(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+train_pipeline = [
+ dict(
+ type='RandomAug',
+ input_size=224,
+ color_jitter=0.4,
+ auto_augment='rand-m9-mstd0.5-inc1',
+ interpolation='bicubic',
+ re_prob=0.25,
+ re_mode='pixel',
+ re_count=1,
+ mean=(0.485, 0.456, 0.406),
+ std=(0.229, 0.224, 0.225))
+]
+test_pipeline = [
+ dict(type='Resize', size=256, interpolation=3),
+ dict(type='CenterCrop', size=224),
+ dict(type='ToTensor'),
+ dict(type='Normalize', **img_norm_cfg)
+]
+data = dict(
+ samples_per_gpu=256,
+ drop_last=False,
+ workers_per_gpu=32,
+ train=dict(pipeline=train_pipeline),
+ val=dict(pipeline=test_pipeline))
diff --git a/configs/benchmarks/classification/imagenet/vit-base-p16_ft-8xb128-coslr-100e-rpe_in1k.py b/configs/benchmarks/classification/imagenet/vit-base-p16_ft-8xb128-coslr-100e-rpe_in1k.py
new file mode 100644
index 000000000..eab6e459e
--- /dev/null
+++ b/configs/benchmarks/classification/imagenet/vit-base-p16_ft-8xb128-coslr-100e-rpe_in1k.py
@@ -0,0 +1,38 @@
+_base_ = 'vit-base-p16_ft-8xb128-coslr-100e_in1k.py'
+
+# model
+model = dict(backbone=dict(use_window=True, init_values=0.1))
+
+# optimizer
+optimizer = dict(lr=8e-3)
+
+# learning policy
+lr_config = dict(warmup_iters=5)
+
+# dataset
+img_norm_cfg = dict(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
+train_pipeline = [
+ dict(
+ type='RandomAug',
+ input_size=224,
+ color_jitter=0.4,
+ auto_augment='rand-m9-mstd0.5-inc1',
+ interpolation='bicubic',
+ re_prob=0.25,
+ re_mode='pixel',
+ re_count=1,
+ mean=(0.5, 0.5, 0.5),
+ std=(0.5, 0.5, 0.5))
+]
+test_pipeline = [
+ dict(type='Resize', size=256, interpolation=3),
+ dict(type='CenterCrop', size=224),
+ dict(type='ToTensor'),
+ dict(type='Normalize', **img_norm_cfg)
+]
+data = dict(
+ train=dict(pipeline=train_pipeline),
+ val=dict(pipeline=test_pipeline),
+ samples_per_gpu=128)
+
+find_unused_parameters = True
diff --git a/configs/benchmarks/classification/imagenet/vit-b-p16_ft-8xb128-coslr-100e_in1k.py b/configs/benchmarks/classification/imagenet/vit-base-p16_ft-8xb128-coslr-100e_in1k.py
similarity index 100%
rename from configs/benchmarks/classification/imagenet/vit-b-p16_ft-8xb128-coslr-100e_in1k.py
rename to configs/benchmarks/classification/imagenet/vit-base-p16_ft-8xb128-coslr-100e_in1k.py
diff --git a/configs/benchmarks/classification/imagenet/vit-small-p16_8xb128-coslr-90e_in1k.py b/configs/benchmarks/classification/imagenet/vit-small-p16_linear-8xb128-coslr-90e_in1k.py
similarity index 100%
rename from configs/benchmarks/classification/imagenet/vit-small-p16_8xb128-coslr-90e_in1k.py
rename to configs/benchmarks/classification/imagenet/vit-small-p16_linear-8xb128-coslr-90e_in1k.py
diff --git a/configs/selfsup/_base_/datasets/imagenet_cae.py b/configs/selfsup/_base_/datasets/imagenet_cae.py
new file mode 100644
index 000000000..944696c2f
--- /dev/null
+++ b/configs/selfsup/_base_/datasets/imagenet_cae.py
@@ -0,0 +1,40 @@
+# dataset settings
+data_source = 'ImageNet'
+dataset_type = 'SingleViewDataset'
+img_norm_cfg = dict(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
+train_pipeline = [
+ dict(type='RandomHorizontalFlip', p=0.5),
+ dict(
+ type='RandomResizedCropAndInterpolationWithTwoPic',
+ size=224,
+ second_size=112,
+ interpolation='bicubic',
+ second_interpolation='lanczos',
+ scale=(0.08, 1.0)),
+]
+
+# prefetch
+prefetch = False
+if not prefetch:
+ train_pipeline.extend([dict(type='ToTensor')])
+
+train_pipeline.append(
+ dict(
+ type='BEiTMaskGenerator',
+ input_size=(14, 14),
+ num_masking_patches=75,
+ max_num_patches=None,
+ min_num_patches=16))
+
+# dataset summary
+data = dict(
+ samples_per_gpu=256,
+ workers_per_gpu=8,
+ train=dict(
+ type=dataset_type,
+ data_source=dict(
+ type=data_source,
+ data_prefix='data/imagenet/train',
+ ann_file='data/imagenet/meta/train.txt'),
+ pipeline=train_pipeline,
+ prefetch=prefetch))
diff --git a/configs/selfsup/_base_/datasets/imagenet_mae.py b/configs/selfsup/_base_/datasets/imagenet_mae.py
index 939fc1039..cd833b5ab 100644
--- a/configs/selfsup/_base_/datasets/imagenet_mae.py
+++ b/configs/selfsup/_base_/datasets/imagenet_mae.py
@@ -17,7 +17,7 @@
# dataset summary
data = dict(
- imgs_per_gpu=128,
+ samples_per_gpu=128,
workers_per_gpu=8,
train=dict(
type=dataset_type,
diff --git a/configs/selfsup/_base_/models/barlowtwins.py b/configs/selfsup/_base_/models/barlowtwins.py
new file mode 100644
index 000000000..577284db1
--- /dev/null
+++ b/configs/selfsup/_base_/models/barlowtwins.py
@@ -0,0 +1,22 @@
+# model settings
+model = dict(
+ type='BarlowTwins',
+ backbone=dict(
+ type='ResNet',
+ depth=50,
+ in_channels=3,
+ out_indices=[4], # 0: conv-1, x: stage-x
+ norm_cfg=dict(type='SyncBN'),
+ zero_init_residual=True),
+ neck=dict(
+ type='NonLinearNeck',
+ in_channels=2048,
+ hid_channels=8192,
+ out_channels=8192,
+ num_layers=3,
+ with_last_bn=False,
+ with_last_bn_affine=False,
+ with_avg_pool=True,
+ init_cfg=dict(
+ type='Kaiming', distribution='uniform', layer=['Linear'])),
+ head=dict(type='LatentCrossCorrelationHead', in_channels=8192))
diff --git a/configs/selfsup/_base_/models/cae.py b/configs/selfsup/_base_/models/cae.py
new file mode 100644
index 000000000..941a56505
--- /dev/null
+++ b/configs/selfsup/_base_/models/cae.py
@@ -0,0 +1,17 @@
+# model settings
+model = dict(
+ type='CAE',
+ backbone=dict(type='CAEViT', arch='b', patch_size=16, init_values=0.1),
+ neck=dict(
+ type='CAENeck',
+ patch_size=16,
+ embed_dims=768,
+ num_heads=12,
+ regressor_depth=4,
+ decoder_depth=4,
+ mlp_ratio=4,
+ init_values=0.1,
+ ),
+ head=dict(
+ type='CAEHead', tokenizer_path='cae_ckpt/dalle_encoder.pth', lambd=2),
+ base_momentum=0.0)
diff --git a/configs/selfsup/_base_/models/simclr.py b/configs/selfsup/_base_/models/simclr.py
index e9f8a9dd9..150f74b5e 100644
--- a/configs/selfsup/_base_/models/simclr.py
+++ b/configs/selfsup/_base_/models/simclr.py
@@ -6,7 +6,8 @@
depth=50,
in_channels=3,
out_indices=[4], # 0: conv-1, x: stage-x
- norm_cfg=dict(type='SyncBN')),
+ norm_cfg=dict(type='SyncBN'),
+ zero_init_residual=True),
neck=dict(
type='NonLinearNeck', # SimCLR non-linear neck
in_channels=2048,
diff --git a/configs/selfsup/barlowtwins/README.md b/configs/selfsup/barlowtwins/README.md
new file mode 100644
index 000000000..06e25543c
--- /dev/null
+++ b/configs/selfsup/barlowtwins/README.md
@@ -0,0 +1,52 @@
+# BarlowTwins
+
+> [Barlow Twins: Self-Supervised Learning via Redundancy Reduction](https://arxiv.org/abs/2103.03230)
+
+
+
+## Abstract
+
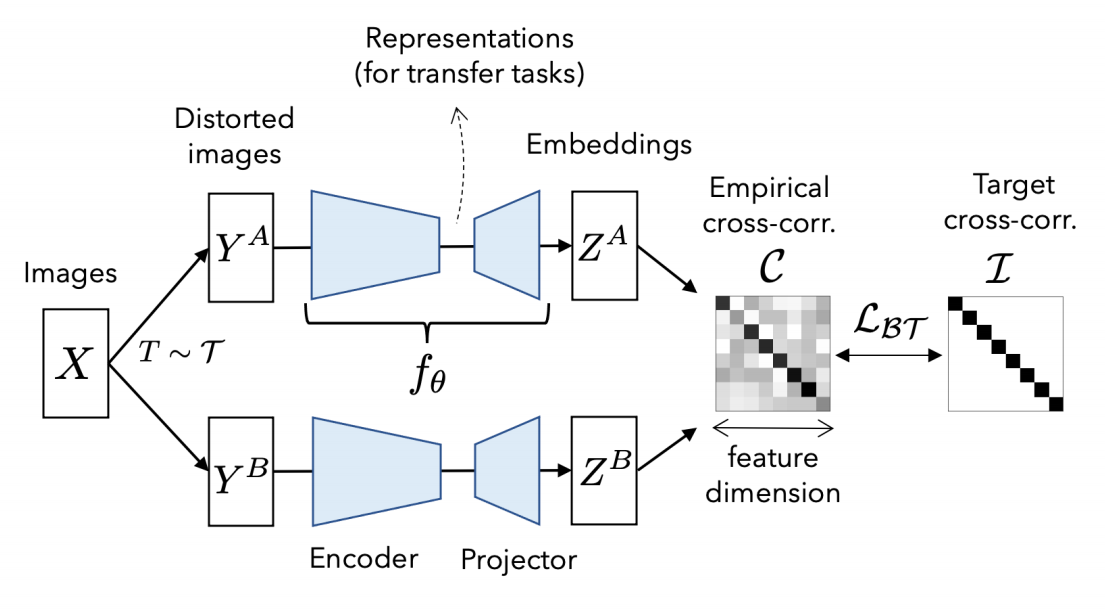
+Self-supervised learning (SSL) is rapidly closing the gap with supervised methods on large computer vision benchmarks. A successful approach to SSL is to learn embeddings which are invariant to distortions of the input sample. However, a recurring issue with this approach is the existence of trivial constant solutions. Most current methods avoid such solutions by careful implementation details. We propose an objective function that naturally avoids collapse by measuring the cross-correlation matrix between the outputs of two identical networks fed with distorted versions of a sample, and making it as close to the identity matrix as possible. This causes the embedding vectors of distorted versions of a sample to be similar, while minimizing the redundancy between the components of these vectors. The method is called Barlow Twins, owing to neuroscientist H. Barlow's redundancy-reduction principle applied to a pair of identical networks. Barlow Twins does not require large batches nor asymmetry between the network twins such as a predictor network, gradient stopping, or a moving average on the weight updates. Intriguingly it benefits from very high-dimensional output vectors. Barlow Twins outperforms previous methods on ImageNet for semi-supervised classification in the low-data regime, and is on par with current state of the art for ImageNet classification with a linear classifier head, and for transfer tasks of classification and object detection.
+
+
+
+
+

+
+
+
+
+
+
+
+
+