diff --git a/docs/agent/aclk.md b/docs/agent/aclk.md
index 4a0196144..e7bbc8009 100644
--- a/docs/agent/aclk.md
+++ b/docs/agent/aclk.md
@@ -11,15 +11,25 @@ The Agent-Cloud link (ACLK) is the mechanism responsible for securely connecting
through Netdata Cloud. The ACLK establishes an outgoing secure WebSocket (WSS) connection to Netdata Cloud on port
`443`. The ACLK is encrypted, safe, and _is only established if you connect your node_.
-The Cloud App lives at app.netdata.cloud which currently resolves to 35.196.244.138. However, this IP or range of
-IPs can change without notice. Watch this page for updates.
+The Cloud App lives at app.netdata.cloud which currently resolves to the following list of IPs:
+
+- 54.198.178.11
+- 44.207.131.212
+- 44.196.50.41
+
+:::caution
+
+This list of IPs can change without notice, we strongly advise you to whitelist the domain `app.netdata.cloud`, if
+this is not an option in your case always verify the current domain resolution (e.g via the `host` command).
+
+:::
For a guide to connecting a node using the ACLK, plus additional troubleshooting and reference information, read our [get
started with Cloud](/docs/cloud/get-started) guide or the full [connect to Cloud
documentation](/docs/agent/claim).
## Data privacy
-[Data privacy](https://netdata.cloud/data-privacy/) is very important to us. We firmly believe that your data belongs to
+[Data privacy](https://netdata.cloud/privacy/) is very important to us. We firmly believe that your data belongs to
you. This is why **we don't store any metric data in Netdata Cloud**.
All the data that you see in the web browser when using Netdata Cloud, is actually streamed directly from the Netdata Agent to the Netdata Cloud dashboard.
@@ -50,12 +60,12 @@ You can configure following keys in the `netdata.conf` section `[cloud]`:
[cloud]
statistics = yes
query thread count = 2
- mqtt5 = no
+ mqtt5 = yes
```
- `statistics` enables/disables ACLK related statistics and their charts. You can disable this to save some space in the database and slightly reduce memory usage of Netdata Agent.
- `query thread count` specifies the number of threads to process cloud queries. Increasing this setting is useful for nodes with many children (streaming), which can expect to handle more queries (and/or more complicated queries).
-- `mqtt5` enables the new MQTT5 protocol implementation in the Agent. Currently a technical preview.
+- `mqtt5` allows disabling the new MQTT5 implementation which is used now by default in case of issues. This option will be removed in future stable release.
## Disable the ACLK
diff --git a/docs/agent/anonymous-statistics.md b/docs/agent/anonymous-statistics.md
index 118b4cad0..10279abe5 100644
--- a/docs/agent/anonymous-statistics.md
+++ b/docs/agent/anonymous-statistics.md
@@ -8,7 +8,7 @@ custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/anonymous-s
By default, Netdata collects anonymous usage information from the open-source monitoring agent using the open-source
product analytics platform [PostHog](https://github.com/PostHog/posthog). We use their [cloud enterprise platform](https://posthog.com/product).
-We are strongly committed to your [data privacy](https://netdata.cloud/data-privacy/).
+We are strongly committed to your [data privacy](https://netdata.cloud/privacy/).
We use the statistics gathered from this information for two purposes:
diff --git a/docs/agent/changelog.md b/docs/agent/changelog.md
index 3264800c8..31e1f81e9 100644
--- a/docs/agent/changelog.md
+++ b/docs/agent/changelog.md
@@ -6,12 +6,128 @@
**Merged pull requests:**
+- Add chart\_context to alert snapshots [\#13492](https://github.com/netdata/netdata/pull/13492) ([MrZammler](https://github.com/MrZammler))
+- Remove prompt to add dashboard issues [\#13490](https://github.com/netdata/netdata/pull/13490) ([cakrit](https://github.com/cakrit))
+- docs: fix unresolved file references [\#13488](https://github.com/netdata/netdata/pull/13488) ([ilyam8](https://github.com/ilyam8))
+- docs: add a note about edit-config for docker installs [\#13487](https://github.com/netdata/netdata/pull/13487) ([ilyam8](https://github.com/ilyam8))
+- health: disable go python last collected alarms [\#13485](https://github.com/netdata/netdata/pull/13485) ([ilyam8](https://github.com/ilyam8))
+- bump go.d.plugin version to v0.34.0 [\#13484](https://github.com/netdata/netdata/pull/13484) ([ilyam8](https://github.com/ilyam8))
+- chore: add WireGuard description and icon to dashboard info [\#13483](https://github.com/netdata/netdata/pull/13483) ([ilyam8](https://github.com/ilyam8))
+- feat\(cgroups.plugin\): resolve nomad containers name \(docker driver only\) [\#13481](https://github.com/netdata/netdata/pull/13481) ([ilyam8](https://github.com/ilyam8))
+- Check for protected when excluding mounts [\#13479](https://github.com/netdata/netdata/pull/13479) ([MrZammler](https://github.com/MrZammler))
+- update postgres dashboard info [\#13474](https://github.com/netdata/netdata/pull/13474) ([ilyam8](https://github.com/ilyam8))
+- Remove the single threaded arrayallocator optiomization during agent startup [\#13473](https://github.com/netdata/netdata/pull/13473) ([stelfrag](https://github.com/stelfrag))
+- Handle cases where entries where stored as text \(with strftime\("%s"\)\) [\#13472](https://github.com/netdata/netdata/pull/13472) ([stelfrag](https://github.com/stelfrag))
+- Enable rrdcontexts by default [\#13471](https://github.com/netdata/netdata/pull/13471) ([stelfrag](https://github.com/stelfrag))
+- Fix cgroup name detection for docker containers in containerd cgroup [\#13470](https://github.com/netdata/netdata/pull/13470) ([xkisu](https://github.com/xkisu))
+- Trimmed-median, trimmed-mean and percentile [\#13469](https://github.com/netdata/netdata/pull/13469) ([ktsaou](https://github.com/ktsaou))
+- rrdcontext support for hidden charts [\#13466](https://github.com/netdata/netdata/pull/13466) ([ktsaou](https://github.com/ktsaou))
+- Load host labels for archived hosts [\#13464](https://github.com/netdata/netdata/pull/13464) ([stelfrag](https://github.com/stelfrag))
+- fix\(python.d/smartd\_log\): handle log rotation [\#13460](https://github.com/netdata/netdata/pull/13460) ([ilyam8](https://github.com/ilyam8))
+- docs: add a note about network interface monitoring when running in a Docker container [\#13458](https://github.com/netdata/netdata/pull/13458) ([ilyam8](https://github.com/ilyam8))
+- fix a guide so we can reference it's subsections [\#13455](https://github.com/netdata/netdata/pull/13455) ([tkatsoulas](https://github.com/tkatsoulas))
+- Revert "Query queue only for queries" [\#13452](https://github.com/netdata/netdata/pull/13452) ([stelfrag](https://github.com/stelfrag))
+- /api/v1/weights endpoint [\#13449](https://github.com/netdata/netdata/pull/13449) ([ktsaou](https://github.com/ktsaou))
+- Get last\_entry\_t only when st changes [\#13448](https://github.com/netdata/netdata/pull/13448) ([MrZammler](https://github.com/MrZammler))
+- additional stats [\#13445](https://github.com/netdata/netdata/pull/13445) ([ktsaou](https://github.com/ktsaou))
+- Store host label information in the metadata database [\#13441](https://github.com/netdata/netdata/pull/13441) ([stelfrag](https://github.com/stelfrag))
+- Fix typo in PostgreSQL section header [\#13440](https://github.com/netdata/netdata/pull/13440) ([shyamvalsan](https://github.com/shyamvalsan))
+- Fix tests so that the actual metadata database is not accessed [\#13439](https://github.com/netdata/netdata/pull/13439) ([stelfrag](https://github.com/stelfrag))
+- Delete aclk\_alert table on start streaming from seq 1 batch 1 [\#13438](https://github.com/netdata/netdata/pull/13438) ([MrZammler](https://github.com/MrZammler))
+- Fix agent crash when archived host has not been registered to the cloud [\#13437](https://github.com/netdata/netdata/pull/13437) ([stelfrag](https://github.com/stelfrag))
+- Dont duplicate buffered bytes [\#13435](https://github.com/netdata/netdata/pull/13435) ([vlvkobal](https://github.com/vlvkobal))
+- Show last 15 alerts in notification [\#13434](https://github.com/netdata/netdata/pull/13434) ([MrZammler](https://github.com/MrZammler))
+- Query queue only for queries [\#13431](https://github.com/netdata/netdata/pull/13431) ([underhood](https://github.com/underhood))
+- Remove octopus from demo-sites [\#13423](https://github.com/netdata/netdata/pull/13423) ([cakrit](https://github.com/cakrit))
+- Tiering statistics API endpoint [\#13420](https://github.com/netdata/netdata/pull/13420) ([ktsaou](https://github.com/ktsaou))
+- add discord, youtube, linkedin links to README [\#13419](https://github.com/netdata/netdata/pull/13419) ([andrewm4894](https://github.com/andrewm4894))
+- add ML bullet point to features section on README [\#13418](https://github.com/netdata/netdata/pull/13418) ([andrewm4894](https://github.com/andrewm4894))
+- Set value to SN\_EMPTY\_SLOT if flags is SN\_EMPTY\_SLOT [\#13417](https://github.com/netdata/netdata/pull/13417) ([MrZammler](https://github.com/MrZammler))
+- Add missing comma \(handle coverity warning CID 379360\) [\#13413](https://github.com/netdata/netdata/pull/13413) ([stelfrag](https://github.com/stelfrag))
+- codacy/lgtm ignore judy sources [\#13411](https://github.com/netdata/netdata/pull/13411) ([underhood](https://github.com/underhood))
+- Send chart context with alert events to the cloud [\#13409](https://github.com/netdata/netdata/pull/13409) ([MrZammler](https://github.com/MrZammler))
+- Remove SIGSEGV and SIGABRT \(ebpf.plugin\) [\#13407](https://github.com/netdata/netdata/pull/13407) ([thiagoftsm](https://github.com/thiagoftsm))
+- minor fixes on metadata fields [\#13406](https://github.com/netdata/netdata/pull/13406) ([tkatsoulas](https://github.com/tkatsoulas))
+- chore\(health\): remove py web\_log alarms [\#13404](https://github.com/netdata/netdata/pull/13404) ([ilyam8](https://github.com/ilyam8))
+- Store host system information in the database [\#13402](https://github.com/netdata/netdata/pull/13402) ([stelfrag](https://github.com/stelfrag))
+- Fix coverity issue 379240 \(Unchecked return value\) [\#13401](https://github.com/netdata/netdata/pull/13401) ([stelfrag](https://github.com/stelfrag))
+- Fix netdata-updater.sh sha256sum on BSDs [\#13391](https://github.com/netdata/netdata/pull/13391) ([tnyeanderson](https://github.com/tnyeanderson))
+- chore\(python.d\): clarify haproxy module readme [\#13388](https://github.com/netdata/netdata/pull/13388) ([ilyam8](https://github.com/ilyam8))
+- Fix bitmap unit tests [\#13374](https://github.com/netdata/netdata/pull/13374) ([stelfrag](https://github.com/stelfrag))
+- chore\(dashboard\): update chrony dashboard info [\#13371](https://github.com/netdata/netdata/pull/13371) ([ilyam8](https://github.com/ilyam8))
+- chore\(python.d\): remove python.d/\* announced in v1.35.0 deprecation notice [\#13370](https://github.com/netdata/netdata/pull/13370) ([ilyam8](https://github.com/ilyam8))
+- bump go.d.plugin version to v0.33.1 [\#13369](https://github.com/netdata/netdata/pull/13369) ([ilyam8](https://github.com/ilyam8))
+- Add Oracle Linux 9 to officially supported platforms. [\#13367](https://github.com/netdata/netdata/pull/13367) ([Ferroin](https://github.com/Ferroin))
+- Address Coverity issues [\#13364](https://github.com/netdata/netdata/pull/13364) ([stelfrag](https://github.com/stelfrag))
+- chore\(python.d\): improve config file parsing error message [\#13363](https://github.com/netdata/netdata/pull/13363) ([ilyam8](https://github.com/ilyam8))
+- in source Judy [\#13362](https://github.com/netdata/netdata/pull/13362) ([underhood](https://github.com/underhood))
+- Add additional Docker image build with debug info included. [\#13359](https://github.com/netdata/netdata/pull/13359) ([Ferroin](https://github.com/Ferroin))
+- Move host tags to netdata\_info [\#13358](https://github.com/netdata/netdata/pull/13358) ([vlvkobal](https://github.com/vlvkobal))
+- Get rid of extra comma in OpenTSDB exporting [\#13355](https://github.com/netdata/netdata/pull/13355) ([vlvkobal](https://github.com/vlvkobal))
+- Fix chart update ebpf.plugin [\#13351](https://github.com/netdata/netdata/pull/13351) ([thiagoftsm](https://github.com/thiagoftsm))
+- add job to move bugs to project board [\#13350](https://github.com/netdata/netdata/pull/13350) ([hugovalente-pm](https://github.com/hugovalente-pm))
+- added another way to get ansible plays [\#13349](https://github.com/netdata/netdata/pull/13349) ([mhkarimi1383](https://github.com/mhkarimi1383))
+- Send node info message sooner [\#13348](https://github.com/netdata/netdata/pull/13348) ([MrZammler](https://github.com/MrZammler))
+- query engine: omit first point if not needed [\#13345](https://github.com/netdata/netdata/pull/13345) ([ktsaou](https://github.com/ktsaou))
+- fix 32bit calculation on array allocator [\#13343](https://github.com/netdata/netdata/pull/13343) ([ktsaou](https://github.com/ktsaou))
+- fix crash on start on slow disks because ml is initialized before dbengine starts [\#13342](https://github.com/netdata/netdata/pull/13342) ([ktsaou](https://github.com/ktsaou))
+- fix\(packaging\): respect CFLAGS arg when building Docker image [\#13340](https://github.com/netdata/netdata/pull/13340) ([ilyam8](https://github.com/ilyam8))
+- add github stars badge to readme [\#13338](https://github.com/netdata/netdata/pull/13338) ([andrewm4894](https://github.com/andrewm4894))
+- Fix coverity 379241 [\#13336](https://github.com/netdata/netdata/pull/13336) ([MrZammler](https://github.com/MrZammler))
+- Rrdcontext [\#13335](https://github.com/netdata/netdata/pull/13335) ([ktsaou](https://github.com/ktsaou))
+- Detect stored metric size by page type [\#13334](https://github.com/netdata/netdata/pull/13334) ([stelfrag](https://github.com/stelfrag))
+- Silence compile warnings on external source [\#13332](https://github.com/netdata/netdata/pull/13332) ([MrZammler](https://github.com/MrZammler))
+- UpdateNodeCollectors message [\#13330](https://github.com/netdata/netdata/pull/13330) ([MrZammler](https://github.com/MrZammler))
+- Cid 379238 379238 [\#13328](https://github.com/netdata/netdata/pull/13328) ([stelfrag](https://github.com/stelfrag))
+- Docs fix metric storage [\#13327](https://github.com/netdata/netdata/pull/13327) ([tkatsoulas](https://github.com/tkatsoulas))
+- Fix two helgrind reports [\#13325](https://github.com/netdata/netdata/pull/13325) ([vkalintiris](https://github.com/vkalintiris))
+- fix\(cgroups.plugin\): adjust kubepods patterns to filter pods when using Kind cluster [\#13324](https://github.com/netdata/netdata/pull/13324) ([ilyam8](https://github.com/ilyam8))
+- Add link to docker config section [\#13323](https://github.com/netdata/netdata/pull/13323) ([cakrit](https://github.com/cakrit))
+- Guide for troubleshooting Agent with Cloud connection for new nodes [\#13322](https://github.com/netdata/netdata/pull/13322) ([Ancairon](https://github.com/Ancairon))
+- fix\(apps.plugin\): adjust `zmstat*` pattern to exclude zoneminder scripts [\#13314](https://github.com/netdata/netdata/pull/13314) ([ilyam8](https://github.com/ilyam8))
+- array allocator for dbengine page descriptors [\#13312](https://github.com/netdata/netdata/pull/13312) ([ktsaou](https://github.com/ktsaou))
+- fix\(health\): disable go.d last collected alarm for prometheus module [\#13309](https://github.com/netdata/netdata/pull/13309) ([ilyam8](https://github.com/ilyam8))
+- Explicitly skip uploads and notifications in third-party repositories. [\#13308](https://github.com/netdata/netdata/pull/13308) ([Ferroin](https://github.com/Ferroin))
+- Protect shared variables with log lock. [\#13306](https://github.com/netdata/netdata/pull/13306) ([vkalintiris](https://github.com/vkalintiris))
+- Keep rc before freeing it during labels unlink alarms [\#13305](https://github.com/netdata/netdata/pull/13305) ([MrZammler](https://github.com/MrZammler))
+- fix\(cgroups.plugin\): adjust kubepods regex to fix name resolution in a kind cluster [\#13302](https://github.com/netdata/netdata/pull/13302) ([ilyam8](https://github.com/ilyam8))
+- Null terminate string if file read was not successful [\#13299](https://github.com/netdata/netdata/pull/13299) ([stelfrag](https://github.com/stelfrag))
+- fix\(health\): fix incorrect Redis dimension names [\#13296](https://github.com/netdata/netdata/pull/13296) ([ilyam8](https://github.com/ilyam8))
+- chore: remove python-mysql from install-required-packages.sh [\#13288](https://github.com/netdata/netdata/pull/13288) ([ilyam8](https://github.com/ilyam8))
+- Use new MQTT as default \(revert \#13258\)" [\#13287](https://github.com/netdata/netdata/pull/13287) ([underhood](https://github.com/underhood))
+- query engine fixes for alarms and dashboards [\#13282](https://github.com/netdata/netdata/pull/13282) ([ktsaou](https://github.com/ktsaou))
+- Better ACLK debug communication log [\#13281](https://github.com/netdata/netdata/pull/13281) ([underhood](https://github.com/underhood))
+- bump go.d.plugin version to v0.33.0 [\#13280](https://github.com/netdata/netdata/pull/13280) ([ilyam8](https://github.com/ilyam8))
+- Fixes vbi parser in mqtt5 implementation [\#13277](https://github.com/netdata/netdata/pull/13277) ([underhood](https://github.com/underhood))
+- Fix alignment in charts endpoint [\#13275](https://github.com/netdata/netdata/pull/13275) ([thiagoftsm](https://github.com/thiagoftsm))
+- Dont print io errors for cgroups [\#13274](https://github.com/netdata/netdata/pull/13274) ([vlvkobal](https://github.com/vlvkobal))
+- Pluginsd doc [\#13273](https://github.com/netdata/netdata/pull/13273) ([thiagoftsm](https://github.com/thiagoftsm))
+- Remove obsolete --use-system-lws option from netdata-installer.sh help [\#13272](https://github.com/netdata/netdata/pull/13272) ([Dim-P](https://github.com/Dim-P))
+- Rename the chart of real memory usage in FreeBSD [\#13271](https://github.com/netdata/netdata/pull/13271) ([vlvkobal](https://github.com/vlvkobal))
+- Update documentation about our REST API documentation. [\#13269](https://github.com/netdata/netdata/pull/13269) ([Ferroin](https://github.com/Ferroin))
+- Fix package build filtering on PRs. [\#13267](https://github.com/netdata/netdata/pull/13267) ([Ferroin](https://github.com/Ferroin))
+- Add document explaining how to proxy Netdata via H2O [\#13266](https://github.com/netdata/netdata/pull/13266) ([Ferroin](https://github.com/Ferroin))
+- chore\(python.d\): remove deprecated modules from python.d.conf [\#13264](https://github.com/netdata/netdata/pull/13264) ([ilyam8](https://github.com/ilyam8))
+- Multi-Tier database backend for long term metrics storage [\#13263](https://github.com/netdata/netdata/pull/13263) ([stelfrag](https://github.com/stelfrag))
+- Get rid of extra semicolon in Graphite exporting [\#13261](https://github.com/netdata/netdata/pull/13261) ([vlvkobal](https://github.com/vlvkobal))
+- fix RAM calculation on macOS in system-info [\#13260](https://github.com/netdata/netdata/pull/13260) ([ilyam8](https://github.com/ilyam8))
+- Ebpf issues [\#13259](https://github.com/netdata/netdata/pull/13259) ([thiagoftsm](https://github.com/thiagoftsm))
+- Use old mqtt implementation as default [\#13258](https://github.com/netdata/netdata/pull/13258) ([MrZammler](https://github.com/MrZammler))
+- Remove warnings while compiling ML on FreeBSD [\#13255](https://github.com/netdata/netdata/pull/13255) ([thiagoftsm](https://github.com/thiagoftsm))
+- Fix issues with DEB postinstall script. [\#13252](https://github.com/netdata/netdata/pull/13252) ([Ferroin](https://github.com/Ferroin))
+- Remove strftime from statements and use unixepoch instead [\#13250](https://github.com/netdata/netdata/pull/13250) ([stelfrag](https://github.com/stelfrag))
+- Query engine with natural and virtual points [\#13248](https://github.com/netdata/netdata/pull/13248) ([ktsaou](https://github.com/ktsaou))
+- Add fstype labels to disk charts [\#13245](https://github.com/netdata/netdata/pull/13245) ([vlvkobal](https://github.com/vlvkobal))
+- Don’t pull in GCC for build if Clang is already present. [\#13244](https://github.com/netdata/netdata/pull/13244) ([Ferroin](https://github.com/Ferroin))
- Delay health until obsoletions check is complete [\#13239](https://github.com/netdata/netdata/pull/13239) ([MrZammler](https://github.com/MrZammler))
+- Improve anomaly detection guide [\#13238](https://github.com/netdata/netdata/pull/13238) ([andrewm4894](https://github.com/andrewm4894))
- Implement PackageCloud cleanup [\#13236](https://github.com/netdata/netdata/pull/13236) ([maneamarius](https://github.com/maneamarius))
- Bump repoconfig package version used in kickstart.sh [\#13235](https://github.com/netdata/netdata/pull/13235) ([Ferroin](https://github.com/Ferroin))
- Updates the sqlite version in the agent [\#13233](https://github.com/netdata/netdata/pull/13233) ([stelfrag](https://github.com/stelfrag))
+- Migrate data when machine GUID changes [\#13232](https://github.com/netdata/netdata/pull/13232) ([stelfrag](https://github.com/stelfrag))
- Add more sqlite unittests [\#13227](https://github.com/netdata/netdata/pull/13227) ([stelfrag](https://github.com/stelfrag))
- ci: add issues to the Agent Board project workflow [\#13225](https://github.com/netdata/netdata/pull/13225) ([ilyam8](https://github.com/ilyam8))
+- Exporting/send variables [\#13221](https://github.com/netdata/netdata/pull/13221) ([boxjan](https://github.com/boxjan))
- fix\(cgroups.plugin\): fix qemu VMs and LXC containers name resolution [\#13220](https://github.com/netdata/netdata/pull/13220) ([ilyam8](https://github.com/ilyam8))
- netdata doubles [\#13217](https://github.com/netdata/netdata/pull/13217) ([ktsaou](https://github.com/ktsaou))
- deduplicate mountinfo based on mount point [\#13215](https://github.com/netdata/netdata/pull/13215) ([ktsaou](https://github.com/ktsaou))
@@ -22,6 +138,8 @@
- Ensure tmpdir is set for every function that uses it. [\#13206](https://github.com/netdata/netdata/pull/13206) ([Ferroin](https://github.com/Ferroin))
- Add user plugin dirs to environment [\#13203](https://github.com/netdata/netdata/pull/13203) ([vlvkobal](https://github.com/vlvkobal))
- Fix cgroups netdev chart labels [\#13200](https://github.com/netdata/netdata/pull/13200) ([vlvkobal](https://github.com/vlvkobal))
+- Add hostname in the worker structure to avoid constant lookups [\#13199](https://github.com/netdata/netdata/pull/13199) ([stelfrag](https://github.com/stelfrag))
+- Rpm group creation [\#13197](https://github.com/netdata/netdata/pull/13197) ([iigorkarpov](https://github.com/iigorkarpov))
- Allow for an easy way to do metadata migrations [\#13196](https://github.com/netdata/netdata/pull/13196) ([stelfrag](https://github.com/stelfrag))
- Dictionaries with reference counters and full deletion support during traversal [\#13195](https://github.com/netdata/netdata/pull/13195) ([ktsaou](https://github.com/ktsaou))
- Add configuration for dbengine page fetch timeout and retry count [\#13194](https://github.com/netdata/netdata/pull/13194) ([stelfrag](https://github.com/stelfrag))
@@ -33,11 +151,13 @@
- fix\(freebsd.plugin\): fix wired/cached/avail memory calculation on FreeBSD with ZFS [\#13183](https://github.com/netdata/netdata/pull/13183) ([ilyam8](https://github.com/ilyam8))
- make configuration example clearer [\#13182](https://github.com/netdata/netdata/pull/13182) ([andrewm4894](https://github.com/andrewm4894))
- add k8s\_state dashboard\_info [\#13181](https://github.com/netdata/netdata/pull/13181) ([ilyam8](https://github.com/ilyam8))
+- Docs housekeeping [\#13179](https://github.com/netdata/netdata/pull/13179) ([tkatsoulas](https://github.com/tkatsoulas))
- Update dashboard to version v2.26.2. [\#13177](https://github.com/netdata/netdata/pull/13177) ([netdatabot](https://github.com/netdatabot))
- feat\(proc/proc\_net\_dev\): add dim per phys link state to the "Interface Physical Link State" chart [\#13176](https://github.com/netdata/netdata/pull/13176) ([ilyam8](https://github.com/ilyam8))
- set default for `minimum num samples to train` to `900` [\#13174](https://github.com/netdata/netdata/pull/13174) ([andrewm4894](https://github.com/andrewm4894))
- Add ml alerts examples [\#13173](https://github.com/netdata/netdata/pull/13173) ([andrewm4894](https://github.com/andrewm4894))
- Revert "Configurable storage engine for Netdata agents: step 3 \(\#12892\)" [\#13171](https://github.com/netdata/netdata/pull/13171) ([vkalintiris](https://github.com/vkalintiris))
+- Remove warnings when openssl 3 is used. [\#13170](https://github.com/netdata/netdata/pull/13170) ([thiagoftsm](https://github.com/thiagoftsm))
- Don’t manipulate positional parameters in DEB postinst script. [\#13169](https://github.com/netdata/netdata/pull/13169) ([Ferroin](https://github.com/Ferroin))
- Fix coverity issues [\#13168](https://github.com/netdata/netdata/pull/13168) ([stelfrag](https://github.com/stelfrag))
- feat\(proc/proc\_net\_dev\): add dim per operstate to the "Interface Operational State" chart [\#13167](https://github.com/netdata/netdata/pull/13167) ([ilyam8](https://github.com/ilyam8))
@@ -77,9 +197,12 @@
- Statistics on bytes recvd and sent [\#13091](https://github.com/netdata/netdata/pull/13091) ([underhood](https://github.com/underhood))
- fix virtualization detection on FreeBSD [\#13087](https://github.com/netdata/netdata/pull/13087) ([ilyam8](https://github.com/ilyam8))
- Update netdata commands [\#13080](https://github.com/netdata/netdata/pull/13080) ([tkatsoulas](https://github.com/tkatsoulas))
+- fix: fix a base64\_encode bug [\#13074](https://github.com/netdata/netdata/pull/13074) ([kklionz](https://github.com/kklionz))
- Labels with dictionary [\#13070](https://github.com/netdata/netdata/pull/13070) ([ktsaou](https://github.com/ktsaou))
- Use a separate thread for slow mountpoints in the diskspace plugin [\#13067](https://github.com/netdata/netdata/pull/13067) ([vlvkobal](https://github.com/vlvkobal))
+- Remove official support for Debian 9. [\#13065](https://github.com/netdata/netdata/pull/13065) ([Ferroin](https://github.com/Ferroin))
- Fix coverity 378587 [\#13024](https://github.com/netdata/netdata/pull/13024) ([MrZammler](https://github.com/MrZammler))
+- Remove Ubuntu 21.10 from CI and package builds. [\#12918](https://github.com/netdata/netdata/pull/12918) ([Ferroin](https://github.com/Ferroin))
- Configurable storage engine for Netdata agents: step 3 [\#12892](https://github.com/netdata/netdata/pull/12892) ([aberaud](https://github.com/aberaud))
## [v1.35.1](https://github.com/netdata/netdata/tree/v1.35.1) (2022-06-10)
@@ -215,99 +338,6 @@
- Allow usage of new MQTT 5 implementation [\#12838](https://github.com/netdata/netdata/pull/12838) ([underhood](https://github.com/underhood))
- Set a page wait timeout and retry count [\#12836](https://github.com/netdata/netdata/pull/12836) ([stelfrag](https://github.com/stelfrag))
- Expose anomaly-bit option to health. [\#12835](https://github.com/netdata/netdata/pull/12835) ([vkalintiris](https://github.com/vkalintiris))
-- feat\(plugins.d\): allow external plugins to create chart labels [\#12834](https://github.com/netdata/netdata/pull/12834) ([ilyam8](https://github.com/ilyam8))
-- Ignore obsolete charts/dims in prediction thread. [\#12833](https://github.com/netdata/netdata/pull/12833) ([vkalintiris](https://github.com/vkalintiris))
-- fix\(exporting\)" make 'send charts matching' behave the same as 'filter' for prometheus format [\#12832](https://github.com/netdata/netdata/pull/12832) ([ilyam8](https://github.com/ilyam8))
-- Remove sync warning [\#12831](https://github.com/netdata/netdata/pull/12831) ([thiagoftsm](https://github.com/thiagoftsm))
-- Reduce the number of messages written in the error log due to out of bound timestamps [\#12829](https://github.com/netdata/netdata/pull/12829) ([stelfrag](https://github.com/stelfrag))
-- Bug fix in netdata-uninstaller.sh [\#12828](https://github.com/netdata/netdata/pull/12828) ([maneamarius](https://github.com/maneamarius))
-- Cleanup the node instance table on startup [\#12825](https://github.com/netdata/netdata/pull/12825) ([stelfrag](https://github.com/stelfrag))
-- Accept a data query timeout parameter from the cloud [\#12823](https://github.com/netdata/netdata/pull/12823) ([stelfrag](https://github.com/stelfrag))
-- Broadcast completion before unlocking condition variable's mutex [\#12822](https://github.com/netdata/netdata/pull/12822) ([vkalintiris](https://github.com/vkalintiris))
-- Add chart filtering parameter to the allmetrics API query [\#12820](https://github.com/netdata/netdata/pull/12820) ([vlvkobal](https://github.com/vlvkobal))
-- Write the entire request with parameters in the access.log file [\#12815](https://github.com/netdata/netdata/pull/12815) ([stelfrag](https://github.com/stelfrag))
-- Add a parameter for how many worker threads the libuv library needs to pre-initialize [\#12814](https://github.com/netdata/netdata/pull/12814) ([stelfrag](https://github.com/stelfrag))
-- Optimize linking of foreach alarms to dimensions. [\#12813](https://github.com/netdata/netdata/pull/12813) ([vkalintiris](https://github.com/vkalintiris))
-- fix!: do not replace a hyphen in the chart name with an underscore [\#12812](https://github.com/netdata/netdata/pull/12812) ([ilyam8](https://github.com/ilyam8))
-- speedup queries by providing optimization in the main loop [\#12811](https://github.com/netdata/netdata/pull/12811) ([ktsaou](https://github.com/ktsaou))
-- onewayallocator to use mallocz\(\) instead of mmap\(\) [\#12810](https://github.com/netdata/netdata/pull/12810) ([ktsaou](https://github.com/ktsaou))
-- Add support for installing static builds on systems without usable internet connections. [\#12809](https://github.com/netdata/netdata/pull/12809) ([Ferroin](https://github.com/Ferroin))
-- Configurable storage engine for Netdata agents: step 2 [\#12808](https://github.com/netdata/netdata/pull/12808) ([aberaud](https://github.com/aberaud))
-- Workers utilization charts [\#12807](https://github.com/netdata/netdata/pull/12807) ([ktsaou](https://github.com/ktsaou))
-- add --repositories-only option [\#12806](https://github.com/netdata/netdata/pull/12806) ([maneamarius](https://github.com/maneamarius))
-- Move kickstart argument parsing code to a function. [\#12805](https://github.com/netdata/netdata/pull/12805) ([Ferroin](https://github.com/Ferroin))
-- Fill missing removed events after a crash [\#12803](https://github.com/netdata/netdata/pull/12803) ([MrZammler](https://github.com/MrZammler))
-- Switch to Alma Linux for RHEL compatible support. [\#12799](https://github.com/netdata/netdata/pull/12799) ([Ferroin](https://github.com/Ferroin))
-- Rename --install option for kickstart.sh [\#12798](https://github.com/netdata/netdata/pull/12798) ([maneamarius](https://github.com/maneamarius))
-- chore\(python.d\): remove python.d/\* announced in v1.34.0 deprecation notice [\#12796](https://github.com/netdata/netdata/pull/12796) ([ilyam8](https://github.com/ilyam8))
-- Don't use MADV\_DONTDUMP on non-linux builds [\#12795](https://github.com/netdata/netdata/pull/12795) ([vkalintiris](https://github.com/vkalintiris))
-- Speed up BUFFER increases \(minimize reallocs\) [\#12792](https://github.com/netdata/netdata/pull/12792) ([ktsaou](https://github.com/ktsaou))
-- procfile: more comfortable initial settings and faster/fewer reallocs [\#12791](https://github.com/netdata/netdata/pull/12791) ([ktsaou](https://github.com/ktsaou))
-- just a simple fix to avoid recompiling protobuf all the time [\#12790](https://github.com/netdata/netdata/pull/12790) ([ktsaou](https://github.com/ktsaou))
-- fix\(proc/net/dev\): exclude Proxmox bridge interfaces [\#12789](https://github.com/netdata/netdata/pull/12789) ([ilyam8](https://github.com/ilyam8))
-- fix\(cgroups.plugin\): do not add network devices if cgroup proc is in the host net ns [\#12788](https://github.com/netdata/netdata/pull/12788) ([ilyam8](https://github.com/ilyam8))
-- One way allocator to double the speed of parallel context queries [\#12787](https://github.com/netdata/netdata/pull/12787) ([ktsaou](https://github.com/ktsaou))
-- fix\(installer\): non interpreted new lines when printing deferred errors [\#12786](https://github.com/netdata/netdata/pull/12786) ([ilyam8](https://github.com/ilyam8))
-- Trace rwlocks of netdata [\#12785](https://github.com/netdata/netdata/pull/12785) ([ktsaou](https://github.com/ktsaou))
-- update ml defaults in docs [\#12782](https://github.com/netdata/netdata/pull/12782) ([andrewm4894](https://github.com/andrewm4894))
-- fix: printing a warning msg in installer [\#12781](https://github.com/netdata/netdata/pull/12781) ([ilyam8](https://github.com/ilyam8))
-- feat\(cgroups.plugin\): add filtering by cgroups names and improve renaming in k8s [\#12778](https://github.com/netdata/netdata/pull/12778) ([ilyam8](https://github.com/ilyam8))
-- Skip ACLK dimension update when dimension is freed [\#12777](https://github.com/netdata/netdata/pull/12777) ([stelfrag](https://github.com/stelfrag))
-- Configurable storage engine for Netdata agents: step 1 [\#12776](https://github.com/netdata/netdata/pull/12776) ([aberaud](https://github.com/aberaud))
-- Fix coverity on receiver setsockopt [\#12772](https://github.com/netdata/netdata/pull/12772) ([MrZammler](https://github.com/MrZammler))
-- some config updates for ml [\#12771](https://github.com/netdata/netdata/pull/12771) ([andrewm4894](https://github.com/andrewm4894))
-- Remove node.d.plugin and relevant files [\#12769](https://github.com/netdata/netdata/pull/12769) ([surajnpn](https://github.com/surajnpn))
-- Fix checking of enviornment file in updater. [\#12768](https://github.com/netdata/netdata/pull/12768) ([Ferroin](https://github.com/Ferroin))
-- use aclk\_parse\_otp\_error on /env error [\#12767](https://github.com/netdata/netdata/pull/12767) ([underhood](https://github.com/underhood))
-- feat\(dbengine\): make dbengine page cache undumpable and dedupuble [\#12765](https://github.com/netdata/netdata/pull/12765) ([ilyam8](https://github.com/ilyam8))
-- fix: use 'diskutil info` to calculate the disk size on macOS [\#12764](https://github.com/netdata/netdata/pull/12764) ([ilyam8](https://github.com/ilyam8))
-- faster execution of external programs [\#12759](https://github.com/netdata/netdata/pull/12759) ([ktsaou](https://github.com/ktsaou))
-- Fix and improve netdata-updater.sh script [\#12757](https://github.com/netdata/netdata/pull/12757) ([MarianSavchuk](https://github.com/MarianSavchuk))
-- fix implicit declaration of function 'appconfig\_section\_option\_destroy\_non\_loaded' [\#12756](https://github.com/netdata/netdata/pull/12756) ([ilyam8](https://github.com/ilyam8))
-- Update netdata-installer.sh [\#12755](https://github.com/netdata/netdata/pull/12755) ([petecooper](https://github.com/petecooper))
-- Tag Gotify health notifications for the Gotify phone app [\#12753](https://github.com/netdata/netdata/pull/12753) ([JaphethLim](https://github.com/JaphethLim))
-- fix\(cgroups.plugin\): remove "search for cgroups under PATH" conf option to fix memory leak [\#12752](https://github.com/netdata/netdata/pull/12752) ([ilyam8](https://github.com/ilyam8))
-- fix\(cgroups.plugin\): run renaming script only for containers in k8s [\#12747](https://github.com/netdata/netdata/pull/12747) ([ilyam8](https://github.com/ilyam8))
-- fix\(cgroups.plugin\): remove "enable cgroup X" config option on cgroup deletion [\#12746](https://github.com/netdata/netdata/pull/12746) ([ilyam8](https://github.com/ilyam8))
-- chore\(cgroup.plugin\): remove undocumented feature reading cgroups-names.sh when renaming cgroups [\#12745](https://github.com/netdata/netdata/pull/12745) ([ilyam8](https://github.com/ilyam8))
-- feat\(cgroups.plugin\): add "CPU Time Relative Share" chart [\#12741](https://github.com/netdata/netdata/pull/12741) ([ilyam8](https://github.com/ilyam8))
-- chore: reduce logging in rrdset [\#12739](https://github.com/netdata/netdata/pull/12739) ([ilyam8](https://github.com/ilyam8))
-- feat\(cgroups.plugin\): add k8s\_qos\_class label [\#12737](https://github.com/netdata/netdata/pull/12737) ([ilyam8](https://github.com/ilyam8))
-- expand on the various parent-child config options [\#12734](https://github.com/netdata/netdata/pull/12734) ([andrewm4894](https://github.com/andrewm4894))
-- Mention serial numbers in chart names in the plugins.d API documentation [\#12733](https://github.com/netdata/netdata/pull/12733) ([vlvkobal](https://github.com/vlvkobal))
-- Make atomics a hard-dep. [\#12730](https://github.com/netdata/netdata/pull/12730) ([vkalintiris](https://github.com/vkalintiris))
-- add --install-version flag for installing specific version of Netdata [\#12729](https://github.com/netdata/netdata/pull/12729) ([maneamarius](https://github.com/maneamarius))
-- Remove per chart configuration. [\#12728](https://github.com/netdata/netdata/pull/12728) ([vkalintiris](https://github.com/vkalintiris))
-- Avoid clearing already unset flags. [\#12727](https://github.com/netdata/netdata/pull/12727) ([vkalintiris](https://github.com/vkalintiris))
-- Remove commented code. [\#12726](https://github.com/netdata/netdata/pull/12726) ([vkalintiris](https://github.com/vkalintiris))
-- chore\(kickstart.sh\): remove unused `--auto-update` option when using static/build install method [\#12725](https://github.com/netdata/netdata/pull/12725) ([ilyam8](https://github.com/ilyam8))
-- \[Chore\]: Small typo in macos document [\#12724](https://github.com/netdata/netdata/pull/12724) ([MrZammler](https://github.com/MrZammler))
-- fix upgrading all currently installed packages when updating Netdata on Debian [\#12716](https://github.com/netdata/netdata/pull/12716) ([iigorkarpov](https://github.com/iigorkarpov))
-- chore\(cgroups.plugin\): reduce the CPU time required for cgroup-network-helper.sh [\#12711](https://github.com/netdata/netdata/pull/12711) ([ilyam8](https://github.com/ilyam8))
-- Add `-pipe` to CFLAGS in most cases for builds. [\#12709](https://github.com/netdata/netdata/pull/12709) ([Ferroin](https://github.com/Ferroin))
-- Tweak static build process to improve build speed and debuggability. [\#12708](https://github.com/netdata/netdata/pull/12708) ([Ferroin](https://github.com/Ferroin))
-- Check for chart obsoletion on children re-connections [\#12707](https://github.com/netdata/netdata/pull/12707) ([MrZammler](https://github.com/MrZammler))
-- feat\(apps.plugin\): add proxmox-ve processes to apps\_groups.conf [\#12704](https://github.com/netdata/netdata/pull/12704) ([ilyam8](https://github.com/ilyam8))
-- chore\(ebpf.plugin\): re-enable socket module by default [\#12702](https://github.com/netdata/netdata/pull/12702) ([ilyam8](https://github.com/ilyam8))
-- Disable automake dependency tracking in our various one-time builds. [\#12701](https://github.com/netdata/netdata/pull/12701) ([Ferroin](https://github.com/Ferroin))
-- Add missing values to algorithm vector \(eBPF\) [\#12698](https://github.com/netdata/netdata/pull/12698) ([thiagoftsm](https://github.com/thiagoftsm))
-- Allocate buffer memory for uv\_write and release in the callback function [\#12688](https://github.com/netdata/netdata/pull/12688) ([stelfrag](https://github.com/stelfrag))
-- \[Uninstall Netdata\] - Add description in the docs to use uninstaller script with force arg [\#12687](https://github.com/netdata/netdata/pull/12687) ([odynik](https://github.com/odynik))
-- Correctly propagate errors and warnings up to the kickstart script from scripts it calls. [\#12686](https://github.com/netdata/netdata/pull/12686) ([Ferroin](https://github.com/Ferroin))
-- Memory CO-RE [\#12684](https://github.com/netdata/netdata/pull/12684) ([thiagoftsm](https://github.com/thiagoftsm))
-- Docs: fix GitHub format [\#12682](https://github.com/netdata/netdata/pull/12682) ([eltociear](https://github.com/eltociear))
-- feat\(apps.plugin\): add caddy to apps\_groups.conf [\#12678](https://github.com/netdata/netdata/pull/12678) ([simon300000](https://github.com/simon300000))
-- fix: use NETDATA\_LISTENER\_PORT in docker healtcheck [\#12676](https://github.com/netdata/netdata/pull/12676) ([ilyam8](https://github.com/ilyam8))
-- Add a 2 minute timeout to stream receiver socket [\#12673](https://github.com/netdata/netdata/pull/12673) ([MrZammler](https://github.com/MrZammler))
-- Add options to kickstart.sh for explicitly passing options to installer code. [\#12658](https://github.com/netdata/netdata/pull/12658) ([Ferroin](https://github.com/Ferroin))
-- Improve agent cloud chart synchronization [\#12655](https://github.com/netdata/netdata/pull/12655) ([stelfrag](https://github.com/stelfrag))
-- Add the ability to perform a data query using an offline node id [\#12650](https://github.com/netdata/netdata/pull/12650) ([stelfrag](https://github.com/stelfrag))
-- Gotify notifications [\#12639](https://github.com/netdata/netdata/pull/12639) ([coffeegrind123](https://github.com/coffeegrind123))
-- Improve handling of release channel selection in kickstart.sh. [\#12635](https://github.com/netdata/netdata/pull/12635) ([Ferroin](https://github.com/Ferroin))
-- Fix Valgrind errors [\#12619](https://github.com/netdata/netdata/pull/12619) ([vlvkobal](https://github.com/vlvkobal))
-- Pass the child machine's guid to the goto\_url link [\#12609](https://github.com/netdata/netdata/pull/12609) ([MrZammler](https://github.com/MrZammler))
-- Implements new capability fields in aclk\_schemas [\#12602](https://github.com/netdata/netdata/pull/12602) ([underhood](https://github.com/underhood))
-- Metric correlations [\#12582](https://github.com/netdata/netdata/pull/12582) ([MrZammler](https://github.com/MrZammler))
## [v1.34.1](https://github.com/netdata/netdata/tree/v1.34.1) (2022-04-15)
@@ -321,47 +351,6 @@
[Full Changelog](https://github.com/netdata/netdata/compare/v1.33.1...v1.34.0)
-**Merged pull requests:**
-
-- Cancel anomaly detection threads before joining. [\#12681](https://github.com/netdata/netdata/pull/12681) ([vkalintiris](https://github.com/vkalintiris))
-- Update dashboard to version v2.25.0. [\#12680](https://github.com/netdata/netdata/pull/12680) ([netdatabot](https://github.com/netdatabot))
-- Delete ML-related data of a host in the proper order. [\#12672](https://github.com/netdata/netdata/pull/12672) ([vkalintiris](https://github.com/vkalintiris))
-- fix\(ebpf.plugin\): add missing chart context for cgroups charts [\#12671](https://github.com/netdata/netdata/pull/12671) ([ilyam8](https://github.com/ilyam8))
-- Remove on pull\_request trigger [\#12670](https://github.com/netdata/netdata/pull/12670) ([dimko](https://github.com/dimko))
-- \[Stream compression Docs\] - Enabled by default [\#12669](https://github.com/netdata/netdata/pull/12669) ([odynik](https://github.com/odynik))
-- Update dashboard to version v2.24.0. [\#12668](https://github.com/netdata/netdata/pull/12668) ([netdatabot](https://github.com/netdatabot))
-- Show error when clock synchronization state is unavailable [\#12667](https://github.com/netdata/netdata/pull/12667) ([vlvkobal](https://github.com/vlvkobal))
-- Dashboard network title [\#12665](https://github.com/netdata/netdata/pull/12665) ([thiagoftsm](https://github.com/thiagoftsm))
-- bump go.d.plugin version to v0.32.2 [\#12663](https://github.com/netdata/netdata/pull/12663) ([ilyam8](https://github.com/ilyam8))
-- Properly limit repository configuration dependencies. [\#12661](https://github.com/netdata/netdata/pull/12661) ([Ferroin](https://github.com/Ferroin))
-- Show --build-only instead of --only-build [\#12657](https://github.com/netdata/netdata/pull/12657) ([MrZammler](https://github.com/MrZammler))
-- Update dashboard to version v2.22.6. [\#12653](https://github.com/netdata/netdata/pull/12653) ([netdatabot](https://github.com/netdatabot))
-- Add a chart label filter parameter in context data queries [\#12652](https://github.com/netdata/netdata/pull/12652) ([stelfrag](https://github.com/stelfrag))
-- Add a timeout parameter to data queries [\#12649](https://github.com/netdata/netdata/pull/12649) ([stelfrag](https://github.com/stelfrag))
-- fix: remove instance-specific information from chart titles [\#12644](https://github.com/netdata/netdata/pull/12644) ([ilyam8](https://github.com/ilyam8))
-- feat: add k8s\_cluster\_name host tag \(GKE only\) [\#12638](https://github.com/netdata/netdata/pull/12638) ([ilyam8](https://github.com/ilyam8))
-- Summarize encountered errors and warnings at end of kickstart script run. [\#12636](https://github.com/netdata/netdata/pull/12636) ([Ferroin](https://github.com/Ferroin))
-- Add eBPF CO-RE version and checksum files to distfile list. [\#12627](https://github.com/netdata/netdata/pull/12627) ([Ferroin](https://github.com/Ferroin))
-- Fix ACLK shutdown [\#12625](https://github.com/netdata/netdata/pull/12625) ([underhood](https://github.com/underhood))
-- Don't do fatal on error writing the health api management key. [\#12623](https://github.com/netdata/netdata/pull/12623) ([MrZammler](https://github.com/MrZammler))
-- fix\(cgroups.plugin\): set CPU prev usage before first usage. [\#12622](https://github.com/netdata/netdata/pull/12622) ([ilyam8](https://github.com/ilyam8))
-- eBPF update dashboard [\#12617](https://github.com/netdata/netdata/pull/12617) ([thiagoftsm](https://github.com/thiagoftsm))
-- fix print: command not found issue [\#12615](https://github.com/netdata/netdata/pull/12615) ([maneamarius](https://github.com/maneamarius))
-- feat: add support for cloud providers info to /api/v1/info [\#12613](https://github.com/netdata/netdata/pull/12613) ([ilyam8](https://github.com/ilyam8))
-- Fix training/prediction stats charts context. [\#12610](https://github.com/netdata/netdata/pull/12610) ([vkalintiris](https://github.com/vkalintiris))
-- Fix a compilation warning [\#12608](https://github.com/netdata/netdata/pull/12608) ([vlvkobal](https://github.com/vlvkobal))
-- Update dashboard to version v2.22.3. [\#12607](https://github.com/netdata/netdata/pull/12607) ([netdatabot](https://github.com/netdatabot))
-- Enable streaming of anomaly\_detection.\* charts [\#12606](https://github.com/netdata/netdata/pull/12606) ([vkalintiris](https://github.com/vkalintiris))
-- Better check for IOMainPort on MacOS [\#12600](https://github.com/netdata/netdata/pull/12600) ([vlvkobal](https://github.com/vlvkobal))
-- Fix coverity issues [\#12598](https://github.com/netdata/netdata/pull/12598) ([vkalintiris](https://github.com/vkalintiris))
-- chore: make logs less noisy on child reconnect [\#12594](https://github.com/netdata/netdata/pull/12594) ([ilyam8](https://github.com/ilyam8))
-- feat\(cgroups.plugin\): add CPU throttling charts [\#12591](https://github.com/netdata/netdata/pull/12591) ([ilyam8](https://github.com/ilyam8))
-- Fix ebpf exit [\#12590](https://github.com/netdata/netdata/pull/12590) ([thiagoftsm](https://github.com/thiagoftsm))
-- feat\(collectors\): update go.d.plugin version to v0.32.1 [\#12586](https://github.com/netdata/netdata/pull/12586) ([ilyam8](https://github.com/ilyam8))
-- Check if libatomic can be linked [\#12583](https://github.com/netdata/netdata/pull/12583) ([MrZammler](https://github.com/MrZammler))
-- Update links to documentation \(eBPF\) [\#12581](https://github.com/netdata/netdata/pull/12581) ([thiagoftsm](https://github.com/thiagoftsm))
-- fix: re-add setuid bit to ioping after installing Debian package [\#12580](https://github.com/netdata/netdata/pull/12580) ([ilyam8](https://github.com/ilyam8))
-
## [v1.33.1](https://github.com/netdata/netdata/tree/v1.33.1) (2022-02-14)
[Full Changelog](https://github.com/netdata/netdata/compare/v1.33.0...v1.33.1)
diff --git a/docs/agent/collectors/collectors.md b/docs/agent/collectors/collectors.md
index 342422749..3865831aa 100644
--- a/docs/agent/collectors/collectors.md
+++ b/docs/agent/collectors/collectors.md
@@ -22,13 +22,18 @@ version](/docs/collect/enable-configure), and enable the Python version. Netdata
attempts to load the Python version and its accompanying configuration file.
If you don't see the app/service you'd like to monitor in this list:
-- Check out our [GitHub issues](https://github.com/netdata/netdata/issues). Use the search bar to look for previous discussions about that
-collector—we may be looking for assistance from users such as yourself!
-- If you don't see the collector there, you can make a [feature request](https://github.com/netdata/netdata/issues/new/choose) on GitHub.
-- If you have basic software development skills, you can add your own plugin in [Go](/docs/agent/collectors/go.d.plugin#how-to-develop-a-collector) or [Python](/guides/python-collector)
+
+- Check out our [GitHub issues](https://github.com/netdata/netdata/issues). Use the search bar to look for previous
+ discussions about that collector—we may be looking for assistance from users such as yourself!
+- If you don't see the collector there, you can make
+ a [feature request](https://github.com/netdata/netdata/issues/new/choose) on GitHub.
+- If you have basic software development skills, you can add your own plugin
+ in [Go](/docs/agent/collectors/go.d.plugin#how-to-develop-a-collector)
+ or [Python](/guides/python-collector)
Supported Collectors List:
- - [Service and application collectors](#service-and-application-collectors)
+
+- [Service and application collectors](#service-and-application-collectors)
- [Generic](#generic)
- [APM (application performance monitoring)](#apm-application-performance-monitoring)
- [Containers and VMs](#containers-and-vms)
@@ -44,7 +49,7 @@ Supported Collectors List:
- [Search](#search)
- [Storage](#storage)
- [Web](#web)
- - [System collectors](#system-collectors)
+- [System collectors](#system-collectors)
- [Applications](#applications)
- [Disks and filesystems](#disks-and-filesystems)
- [eBPF](#ebpf)
@@ -55,10 +60,10 @@ Supported Collectors List:
- [Processes](#processes)
- [Resources](#resources)
- [Users](#users)
- - [Netdata collectors](#netdata-collectors)
- - [Orchestrators](#orchestrators)
- - [Third-party collectors](#third-party-collectors)
- - [Etc](#etc)
+- [Netdata collectors](#netdata-collectors)
+- [Orchestrators](#orchestrators)
+- [Third-party collectors](#third-party-collectors)
+- [Etc](#etc)
## Service and application collectors
@@ -169,9 +174,8 @@ configure any of these collectors according to your setup and infrastructure.
plugins metrics from an endpoint provided by `in_monitor plugin`.
- [Logstash](/docs/agent/collectors/go.d.plugin/modules/logstash/): Monitor JVM threads,
memory usage, garbage collection statistics, and more.
-- [OpenVPN status logs](/docs/agent/collectors/python.d.plugin/ovpn_status_log): Parse server log files and provide
- summary
- (client, traffic) metrics.
+- [OpenVPN status logs](/docs/agent/collectors/go.d.plugin/modules/openvpn_status_log): Parse
+ server log files and provide summary (client, traffic) metrics.
- [Squid web server logs](/docs/agent/collectors/go.d.plugin/modules/squidlog/): Tail Squid
access logs to return the volume of requests, types of requests, bandwidth, and much more.
- [Web server logs (Go version for Apache,
@@ -200,8 +204,8 @@ configure any of these collectors according to your setup and infrastructure.
- [Bind 9](/docs/agent/collectors/go.d.plugin/modules/bind/): Collect nameserver summary
performance statistics via a web interface (`statistics-channels` feature).
-- [Chrony](/docs/agent/collectors/python.d.plugin/chrony): Monitor the precision and statistics of a local `chronyd`
- server.
+- [Chrony](/docs/agent/collectors/go.d.plugin/modules/chrony): Monitor the precision and
+ statistics of a local `chronyd` server.
- [CoreDNS](/docs/agent/collectors/go.d.plugin/modules/coredns/): Measure DNS query round
trip time.
- [Dnsmasq](/docs/agent/collectors/go.d.plugin/modules/dnsmasq_dhcp/): Automatically
@@ -251,13 +255,14 @@ configure any of these collectors according to your setup and infrastructure.
- [AM2320](/docs/agent/collectors/python.d.plugin/am2320): Monitor sensor temperature and humidity.
- [Access point](/docs/agent/collectors/charts.d.plugin/ap): Monitor client, traffic and signal metrics using the `aw`
- tool.
+ tool.
- [APC UPS](/docs/agent/collectors/charts.d.plugin/apcupsd): Capture status information using the `apcaccess` tool.
- [Energi Core](/docs/agent/collectors/go.d.plugin/modules/energid): Monitor
- blockchain indexes, memory usage, network usage, and transactions of wallet instances.
+ blockchain indexes, memory usage, network usage, and transactions of wallet instances.
- [UPS/PDU](/docs/agent/collectors/charts.d.plugin/nut): Read the status of UPS/PDU devices using the `upsc` tool.
-- [SNMP devices](/docs/agent/collectors/go.d.plugin/modules/snmp): Gather data using the SNMP protocol.
-- [1-Wire sensors](/docs/agent/collectors/python.d.plugin/w1sensor): Monitor sensor temperature.
+- [SNMP devices](/docs/agent/collectors/go.d.plugin/modules/snmp): Gather data using the SNMP
+ protocol.
+- [1-Wire sensors](/docs/agent/collectors/python.d.plugin/w1sensor): Monitor sensor temperature.
### Search
@@ -482,9 +487,9 @@ Plugin orchestrators organize and run many of the above collectors.
If you're interested in developing a new collector that you'd like to contribute to Netdata, we highly recommend using
the `go.d.plugin`.
-- [go.d.plugin](https://github.com/netdata/go.d.plugin): An orchestrator for data collection modules written in `go`.
-- [python.d.plugin](/docs/agent/collectors/python.d.plugin): An orchestrator for data collection modules written in `python` v2/v3.
-- [charts.d.plugin](/docs/agent/collectors/charts.d.plugin): An orchestrator for data collection modules written in `bash` v4+.
+- [go.d.plugin](https://github.com/netdata/go.d.plugin): An orchestrator for data collection modules written in `go`.
+- [python.d.plugin](/docs/agent/collectors/python.d.plugin): An orchestrator for data collection modules written in `python` v2/v3.
+- [charts.d.plugin](/docs/agent/collectors/charts.d.plugin): An orchestrator for data collection modules written in `bash` v4+.
## Third-party collectors
diff --git a/docs/agent/collectors/ebpf.plugin.md b/docs/agent/collectors/ebpf.plugin.md
index 82930d1ff..a3c12e1b4 100644
--- a/docs/agent/collectors/ebpf.plugin.md
+++ b/docs/agent/collectors/ebpf.plugin.md
@@ -8,7 +8,7 @@ sidebar_label: "eBPF"
-The Netdata Agent provides many [eBPF](https://ebpf.io/what-is-ebpf/) programs to help you troubleshoot and debug how applications interact with the Linux kernel. The `ebpf.plugin` uses [tracepoints, trampoline, and2 kprobes](#data-collection) to collect a wide array of high value data about the host that would otherwise be impossible to capture.
+The Netdata Agent provides many [eBPF](https://ebpf.io/what-is-ebpf/) programs to help you troubleshoot and debug how applications interact with the Linux kernel. The `ebpf.plugin` uses [tracepoints, trampoline, and2 kprobes](#how-netdata-collects-data-using-probes-and-tracepoints) to collect a wide array of high value data about the host that would otherwise be impossible to capture.
> ❗ eBPF monitoring only works on Linux systems and with specific Linux kernels, including all kernels newer than `4.11.0`, and all kernels on CentOS 7.6 or later. For kernels older than `4.11.0`, improved support is in active development.
@@ -20,8 +20,6 @@ For hands-on configuration and troubleshooting tips see our [tutorial on trouble
An example of virtual file system (VFS) charts made possible by the eBPF collector plugin.
-
-
## How Netdata collects data using probes and tracepoints
Netdata uses the following features from the Linux kernel to run eBPF programs:
diff --git a/docs/agent/collectors/go.d.plugin.md b/docs/agent/collectors/go.d.plugin.md
index d087c8100..ba0e59b61 100644
--- a/docs/agent/collectors/go.d.plugin.md
+++ b/docs/agent/collectors/go.d.plugin.md
@@ -6,8 +6,6 @@ custom_edit_url: https://github.com/netdata/go.d.plugin/edit/master/README.md
-[](https://circleci.com/gh/netdata/go.d.plugin)
-
`go.d.plugin` is a `Netdata` external plugin. It is an **orchestrator** for data collection modules written in `go`.
1. It runs as an independent process `ps fax` shows it.
@@ -17,78 +15,91 @@ custom_edit_url: https://github.com/netdata/go.d.plugin/edit/master/README.md
5. Allows each [module](https://github.com/netdata/go.d.plugin/tree/master/modules) to have any number of data
collection **jobs**.
+## Bug reports, feature requests, and questions
+
+Are welcome! We are using [netdata/netdata](https://github.com/netdata/netdata/) repository for bugs, feature requests,
+and questions.
+
+- [GitHub Issues](https://github.com/netdata/netdata/issues/new/choose): report bugs or open a new feature request.
+- [GitHub Discussions](https://github.com/netdata/netdata/discussions): ask a question or suggest a new idea.
+
## Install
Go.d.plugin is shipped with [`Netdata`](https://github.com/netdata/netdata).
## Available modules
-| Name | Monitors |
-|:--------------------------------------------------------------------------------------------------|:--------------------------------|
-| [activemq](https://github.com/netdata/go.d.plugin/tree/master/modules/activemq) | `ActiveMQ` |
-| [apache](https://github.com/netdata/go.d.plugin/tree/master/modules/apache) | `Apache` |
-| [bind](https://github.com/netdata/go.d.plugin/tree/master/modules/bind) | `ISC Bind` |
-| [cockroachdb](https://github.com/netdata/go.d.plugin/tree/master/modules/cockroachdb) | `CockroachDB` |
-| [consul](https://github.com/netdata/go.d.plugin/tree/master/modules/consul) | `Consul` |
-| [coredns](https://github.com/netdata/go.d.plugin/tree/master/modules/coredns) | `CoreDNS` |
-| [couchbase](https://github.com/netdata/go.d.plugin/tree/master/modules/couchbase) | `Couchbase` |
-| [couchdb](https://github.com/netdata/go.d.plugin/tree/master/modules/couchdb) | `CouchDB` |
-| [dnsdist](https://github.com/netdata/go.d.plugin/tree/master/modules/dnsdist) | `Dnsdist` |
-| [dnsmasq](https://github.com/netdata/go.d.plugin/tree/master/modules/dnsmasq) | `Dnsmasq DNS Forwarder` |
-| [dnsmasq_dhcp](https://github.com/netdata/go.d.plugin/tree/master/modules/dnsmasq_dhcp) | `Dnsmasq DHCP` |
-| [dns_query](https://github.com/netdata/go.d.plugin/tree/master/modules/dnsquery) | `DNS Query RTT` |
-| [docker_engine](https://github.com/netdata/go.d.plugin/tree/master/modules/docker_engine) | `Docker Engine` |
-| [dockerhub](https://github.com/netdata/go.d.plugin/tree/master/modules/dockerhub) | `Docker Hub` |
-| [elasticsearch](https://github.com/netdata/go.d.plugin/tree/master/modules/elasticsearch) | `Elasticsearch` |
-| [energid](https://github.com/netdata/go.d.plugin/tree/master/modules/energid) | `Energi Core` |
-| [example](https://github.com/netdata/go.d.plugin/tree/master/modules/example) | - |
-| [filecheck](https://github.com/netdata/go.d.plugin/tree/master/modules/filecheck) | `Files and Directories` |
-| [fluentd](https://github.com/netdata/go.d.plugin/tree/master/modules/fluentd) | `Fluentd` |
-| [freeradius](https://github.com/netdata/go.d.plugin/tree/master/modules/freeradius) | `FreeRADIUS` |
-| [haproxy](https://github.com/netdata/go.d.plugin/tree/master/modules/haproxy) | `HAProxy` |
-| [hdfs](https://github.com/netdata/go.d.plugin/tree/master/modules/hdfs) | `HDFS` |
-| [httpcheck](https://github.com/netdata/go.d.plugin/tree/master/modules/httpcheck) | `Any HTTP Endpoint` |
-| [isc_dhcpd](https://github.com/netdata/go.d.plugin/tree/master/modules/isc_dhcpd) | `ISC dhcpd` |
-| [k8s_kubelet](https://github.com/netdata/go.d.plugin/tree/master/modules/k8s_kubelet) | `Kubelet` |
-| [k8s_kubeproxy](https://github.com/netdata/go.d.plugin/tree/master/modules/k8s_kubeproxy) | `Kube-proxy` |
-| [k8s_state](https://github.com/netdata/go.d.plugin/tree/master/modules/k8s_state) | `Kubernetes cluster state` |
-| [lighttpd](https://github.com/netdata/go.d.plugin/tree/master/modules/lighttpd) | `Lighttpd` |
-| [lighttpd2](https://github.com/netdata/go.d.plugin/tree/master/modules/lighttpd2) | `Lighttpd2` |
-| [logstash](https://github.com/netdata/go.d.plugin/tree/master/modules/logstash) | `Logstash` |
-| [mongoDB](https://github.com/netdata/go.d.plugin/tree/master/modules/mongodb) | `MongoDB` |
-| [mysql](https://github.com/netdata/go.d.plugin/tree/master/modules/mysql) | `MySQL` |
-| [nginx](https://github.com/netdata/go.d.plugin/tree/master/modules/nginx) | `NGINX` |
-| [nginxvts](https://github.com/netdata/go.d.plugin/tree/master/modules/nginxvts) | `NGINX VTS` |
-| [openvpn](https://github.com/netdata/go.d.plugin/tree/master/modules/openvpn) | `OpenVPN` |
-| [phpdaemon](https://github.com/netdata/go.d.plugin/tree/master/modules/phpdaemon) | `phpDaemon` |
-| [phpfpm](https://github.com/netdata/go.d.plugin/tree/master/modules/phpfpm) | `PHP-FPM` |
-| [pihole](https://github.com/netdata/go.d.plugin/tree/master/modules/pihole) | `Pi-hole` |
-| [pika](https://github.com/netdata/go.d.plugin/tree/master/modules/pika) | `Pika` |
-| [prometheus](https://github.com/netdata/go.d.plugin/tree/master/modules/prometheus) | `Any Prometheus Endpoint` |
-| [portcheck](https://github.com/netdata/go.d.plugin/tree/master/modules/portcheck) | `Any TCP Endpoint` |
-| [powerdns](https://github.com/netdata/go.d.plugin/tree/master/modules/powerdns) | `PowerDNS Authoritative Server` |
-| [powerdns_recursor](https://github.com/netdata/go.d.plugin/tree/master/modules/powerdns_recursor) | `PowerDNS Recursor` |
-| [pulsar](https://github.com/netdata/go.d.plugin/tree/master/modules/portcheck) | `Apache Pulsar` |
-| [rabbitmq](https://github.com/netdata/go.d.plugin/tree/master/modules/rabbitmq) | `RabbitMQ` |
-| [redis](https://github.com/netdata/go.d.plugin/tree/master/modules/redis) | `Redis` |
-| [scaleio](https://github.com/netdata/go.d.plugin/tree/master/modules/scaleio) | `Dell EMC ScaleIO` |
-| [SNMP](https://github.com/netdata/go.d.plugin/blob/master/modules/snmp) | `SNMP` |
-| [solr](https://github.com/netdata/go.d.plugin/tree/master/modules/solr) | `Solr` |
-| [squidlog](https://github.com/netdata/go.d.plugin/tree/master/modules/squidlog) | `Squid` |
-| [springboot2](https://github.com/netdata/go.d.plugin/tree/master/modules/springboot2) | `Spring Boot2` |
-| [supervisord](https://github.com/netdata/go.d.plugin/tree/master/modules/supervisord) | `Supervisor` |
-| [systemdunits](https://github.com/netdata/go.d.plugin/tree/master/modules/systemdunits) | `Systemd unit state` |
-| [tengine](https://github.com/netdata/go.d.plugin/tree/master/modules/tengine) | `Tengine` |
-| [traefik](https://github.com/netdata/go.d.plugin/tree/master/modules/traefik) | `Traefik` |
-| [unbound](https://github.com/netdata/go.d.plugin/tree/master/modules/unbound) | `Unbound` |
-| [vcsa](https://github.com/netdata/go.d.plugin/tree/master/modules/vcsa) | `vCenter Server Appliance` |
-| [vernemq](https://github.com/netdata/go.d.plugin/tree/master/modules/vernemq) | `VerneMQ` |
-| [vsphere](https://github.com/netdata/go.d.plugin/tree/master/modules/vsphere) | `VMware vCenter Server` |
-| [web_log](https://github.com/netdata/go.d.plugin/tree/master/modules/weblog) | `Apache/NGINX` |
-| [whoisquery](https://github.com/netdata/go.d.plugin/tree/master/modules/whoisquery) | `Domain Expiry` |
-| [wmi](https://github.com/netdata/go.d.plugin/tree/master/modules/wmi) | `Windows Machines` |
-| [x509check](https://github.com/netdata/go.d.plugin/tree/master/modules/x509check) | `Digital Certificates` |
-| [zookeeper](https://github.com/netdata/go.d.plugin/tree/master/modules/zookeeper) | `ZooKeeper` |
+| Name | Monitors |
+|:----------------------------------------------------------------------------------------------------|:-----------------------------:|
+| [activemq](https://github.com/netdata/go.d.plugin/tree/master/modules/activemq) | ActiveMQ |
+| [apache](https://github.com/netdata/go.d.plugin/tree/master/modules/apache) | Apache |
+| [bind](https://github.com/netdata/go.d.plugin/tree/master/modules/bind) | ISC Bind |
+| [chrony](https://github.com/netdata/go.d.plugin/tree/master/modules/chrony) | Chrony |
+| [cockroachdb](https://github.com/netdata/go.d.plugin/tree/master/modules/cockroachdb) | CockroachDB |
+| [consul](https://github.com/netdata/go.d.plugin/tree/master/modules/consul) | Consul |
+| [coredns](https://github.com/netdata/go.d.plugin/tree/master/modules/coredns) | CoreDNS |
+| [couchbase](https://github.com/netdata/go.d.plugin/tree/master/modules/couchbase) | Couchbase |
+| [couchdb](https://github.com/netdata/go.d.plugin/tree/master/modules/couchdb) | CouchDB |
+| [dnsdist](https://github.com/netdata/go.d.plugin/tree/master/modules/dnsdist) | Dnsdist |
+| [dnsmasq](https://github.com/netdata/go.d.plugin/tree/master/modules/dnsmasq) | Dnsmasq DNS Forwarder |
+| [dnsmasq_dhcp](https://github.com/netdata/go.d.plugin/tree/master/modules/dnsmasq_dhcp) | Dnsmasq DHCP |
+| [dns_query](https://github.com/netdata/go.d.plugin/tree/master/modules/dnsquery) | DNS Query RTT |
+| [docker_engine](https://github.com/netdata/go.d.plugin/tree/master/modules/docker_engine) | Docker Engine |
+| [dockerhub](https://github.com/netdata/go.d.plugin/tree/master/modules/dockerhub) | Docker Hub |
+| [elasticsearch](https://github.com/netdata/go.d.plugin/tree/master/modules/elasticsearch) | Elasticsearch |
+| [energid](https://github.com/netdata/go.d.plugin/tree/master/modules/energid) | Energi Core |
+| [example](https://github.com/netdata/go.d.plugin/tree/master/modules/example) | - |
+| [filecheck](https://github.com/netdata/go.d.plugin/tree/master/modules/filecheck) | Files and Directories |
+| [fluentd](https://github.com/netdata/go.d.plugin/tree/master/modules/fluentd) | Fluentd |
+| [freeradius](https://github.com/netdata/go.d.plugin/tree/master/modules/freeradius) | FreeRADIUS |
+| [haproxy](https://github.com/netdata/go.d.plugin/tree/master/modules/haproxy) | HAProxy |
+| [hdfs](https://github.com/netdata/go.d.plugin/tree/master/modules/hdfs) | HDFS |
+| [httpcheck](https://github.com/netdata/go.d.plugin/tree/master/modules/httpcheck) | Any HTTP Endpoint |
+| [isc_dhcpd](https://github.com/netdata/go.d.plugin/tree/master/modules/isc_dhcpd) | ISC DHCP |
+| [k8s_kubelet](https://github.com/netdata/go.d.plugin/tree/master/modules/k8s_kubelet) | Kubelet |
+| [k8s_kubeproxy](https://github.com/netdata/go.d.plugin/tree/master/modules/k8s_kubeproxy) | Kube-proxy |
+| [k8s_state](https://github.com/netdata/go.d.plugin/tree/master/modules/k8s_state) | Kubernetes cluster state |
+| [lighttpd](https://github.com/netdata/go.d.plugin/tree/master/modules/lighttpd) | Lighttpd |
+| [lighttpd2](https://github.com/netdata/go.d.plugin/tree/master/modules/lighttpd2) | Lighttpd2 |
+| [logstash](https://github.com/netdata/go.d.plugin/tree/master/modules/logstash) | Logstash |
+| [mongoDB](https://github.com/netdata/go.d.plugin/tree/master/modules/mongodb) | MongoDB |
+| [mysql](https://github.com/netdata/go.d.plugin/tree/master/modules/mysql) | MySQL |
+| [nginx](https://github.com/netdata/go.d.plugin/tree/master/modules/nginx) | NGINX |
+| [nginxvts](https://github.com/netdata/go.d.plugin/tree/master/modules/nginxvts) | NGINX VTS |
+| [openvpn](https://github.com/netdata/go.d.plugin/tree/master/modules/openvpn) | OpenVPN |
+| [openvpn_status_log](https://github.com/netdata/go.d.plugin/tree/master/modules/openvpn_status_log) | OpenVPN |
+| [pgbouncer](https://github.com/netdata/go.d.plugin/tree/master/modules/pgbouncer) | PgBouncer |
+| [phpdaemon](https://github.com/netdata/go.d.plugin/tree/master/modules/phpdaemon) | phpDaemon |
+| [phpfpm](https://github.com/netdata/go.d.plugin/tree/master/modules/phpfpm) | PHP-FPM |
+| [pihole](https://github.com/netdata/go.d.plugin/tree/master/modules/pihole) | Pi-hole |
+| [pika](https://github.com/netdata/go.d.plugin/tree/master/modules/pika) | Pika |
+| [prometheus](https://github.com/netdata/go.d.plugin/tree/master/modules/prometheus) | Any Prometheus Endpoint |
+| [portcheck](https://github.com/netdata/go.d.plugin/tree/master/modules/portcheck) | Any TCP Endpoint |
+| [postgres](https://github.com/netdata/go.d.plugin/tree/master/modules/postgres) | PostgreSQL |
+| [powerdns](https://github.com/netdata/go.d.plugin/tree/master/modules/powerdns) | PowerDNS Authoritative Server |
+| [powerdns_recursor](https://github.com/netdata/go.d.plugin/tree/master/modules/powerdns_recursor) | PowerDNS Recursor |
+| [pulsar](https://github.com/netdata/go.d.plugin/tree/master/modules/portcheck) | Apache Pulsar |
+| [rabbitmq](https://github.com/netdata/go.d.plugin/tree/master/modules/rabbitmq) | RabbitMQ |
+| [redis](https://github.com/netdata/go.d.plugin/tree/master/modules/redis) | Redis |
+| [scaleio](https://github.com/netdata/go.d.plugin/tree/master/modules/scaleio) | Dell EMC ScaleIO |
+| [SNMP](https://github.com/netdata/go.d.plugin/blob/master/modules/snmp) | SNMP |
+| [solr](https://github.com/netdata/go.d.plugin/tree/master/modules/solr) | Solr |
+| [squidlog](https://github.com/netdata/go.d.plugin/tree/master/modules/squidlog) | Squid |
+| [springboot2](https://github.com/netdata/go.d.plugin/tree/master/modules/springboot2) | Spring Boot2 |
+| [supervisord](https://github.com/netdata/go.d.plugin/tree/master/modules/supervisord) | Supervisor |
+| [systemdunits](https://github.com/netdata/go.d.plugin/tree/master/modules/systemdunits) | Systemd unit state |
+| [tengine](https://github.com/netdata/go.d.plugin/tree/master/modules/tengine) | Tengine |
+| [traefik](https://github.com/netdata/go.d.plugin/tree/master/modules/traefik) | Traefik |
+| [unbound](https://github.com/netdata/go.d.plugin/tree/master/modules/unbound) | Unbound |
+| [vcsa](https://github.com/netdata/go.d.plugin/tree/master/modules/vcsa) | vCenter Server Appliance |
+| [vernemq](https://github.com/netdata/go.d.plugin/tree/master/modules/vernemq) | VerneMQ |
+| [vsphere](https://github.com/netdata/go.d.plugin/tree/master/modules/vsphere) | VMware vCenter Server |
+| [web_log](https://github.com/netdata/go.d.plugin/tree/master/modules/weblog) | Apache/NGINX |
+| [wireguard](https://github.com/netdata/go.d.plugin/tree/master/modules/wireguard) | WireGuard |
+| [whoisquery](https://github.com/netdata/go.d.plugin/tree/master/modules/whoisquery) | Domain Expiry |
+| [wmi](https://github.com/netdata/go.d.plugin/tree/master/modules/wmi) | Windows Machines |
+| [x509check](https://github.com/netdata/go.d.plugin/tree/master/modules/x509check) | Digital Certificates |
+| [zookeeper](https://github.com/netdata/go.d.plugin/tree/master/modules/zookeeper) | ZooKeeper |
## Configuration
diff --git a/docs/agent/collectors/go.d.plugin/agent.md b/docs/agent/collectors/go.d.plugin/agent.md
index 542fafe64..7f18c1273 100644
--- a/docs/agent/collectors/go.d.plugin/agent.md
+++ b/docs/agent/collectors/go.d.plugin/agent.md
@@ -2,12 +2,12 @@
This library is a tool for writing [netdata](https://github.com/netdata/netdata) plugins.
-We strongly believe that custom plugins are very important and they must be easy to write.
+We strongly believe that custom plugins are very important, and they must be easy to write.
Definitions:
- orchestrator
- > plugin orchestrators are external plugins that do not collect any data by themselves. Instead they support data collection modules written in the language of the orchestrator. Usually the orchestrator provides a higher level abstraction, making it ideal for writing new data collection modules with the minimum of code.
+ > plugin orchestrators are external plugins that do not collect any data by themselves. Instead, they support data collection modules written in the language of the orchestrator. Usually the orchestrator provides a higher level abstraction, making it ideal for writing new data collection modules with the minimum of code.
- plugin
> plugin is a set of data collection modules.
diff --git a/docs/agent/collectors/go.d.plugin/modules/activemq.md b/docs/agent/collectors/go.d.plugin/modules/activemq.md
index 69132462e..e63791a0c 100644
--- a/docs/agent/collectors/go.d.plugin/modules/activemq.md
+++ b/docs/agent/collectors/go.d.plugin/modules/activemq.md
@@ -55,7 +55,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `activemq` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/apache.md b/docs/agent/collectors/go.d.plugin/modules/apache.md
index e6812e3e7..31a6826dd 100644
--- a/docs/agent/collectors/go.d.plugin/modules/apache.md
+++ b/docs/agent/collectors/go.d.plugin/modules/apache.md
@@ -59,7 +59,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `apache` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/bind.md b/docs/agent/collectors/go.d.plugin/modules/bind.md
index 99f11ef39..e3078a660 100644
--- a/docs/agent/collectors/go.d.plugin/modules/bind.md
+++ b/docs/agent/collectors/go.d.plugin/modules/bind.md
@@ -92,7 +92,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `bind` collector, run the `go.d.plugin` with the debug option enabled. The output should
give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/chrony.md b/docs/agent/collectors/go.d.plugin/modules/chrony.md
index 229f4fc6b..42b1ec558 100644
--- a/docs/agent/collectors/go.d.plugin/modules/chrony.md
+++ b/docs/agent/collectors/go.d.plugin/modules/chrony.md
@@ -1,19 +1,77 @@
+---
+title: "Chrony monitoring with Netdata"
+custom_edit_url: https://github.com/netdata/go.d.plugin/edit/master/modules/chrony/README.md
+sidebar_label: "Chrony"
+---
-[`chrony`](https://chrony.tuxfamily.org/) is a versatile implementation of the Network Time Protocol (NTP).
-The modules will monitor local host `chrony` server.
+[chrony](https://chrony.tuxfamily.org/) is a versatile implementation of the Network Time Protocol (NTP).
-This module use golang to collect chrony and produces:
-* stratum
-* frequency
-* last offset
-* RMS offset
-* residual freq
-* root delay
-* root dispersion
-* skew
-* leap status
-* update interval
-* current correction
-* current source server address
\ No newline at end of file
+This module monitors the system's clock performance and peers activity status using Chrony communication protocol v6.
+
+## Charts
+
+It produces the following charts:
+
+- Distance to the reference clock
+- Current correction
+- Network path delay to stratum-1
+- Dispersion accumulated back to stratum-1
+- Offset on the last clock update
+- Long-term average of the offset value
+- Frequency
+- Residual frequency
+- Skew
+- Interval between the last two clock updates
+- Time since the last measurement
+- Leap status
+- Peers activity
+
+## Configuration
+
+Edit the `go.d/chrony.conf` configuration file using `edit-config` from the
+Netdata [config directory](/docs/configure/nodes), which is typically at `/etc/netdata`.
+
+```bash
+cd /etc/netdata # Replace this path with your Netdata config directory, if different
+sudo ./edit-config go.d/chrony.conf
+```
+
+Configuration example:
+
+```yaml
+jobs:
+ - name: local
+ address: '127.0.0.1:323'
+ timeout: 1
+
+ - name: remote
+ address: '203.0.113.0:323'
+ timeout: 3
+```
+
+For all available options please see
+module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/config/go.d/chrony.conf).
+
+---
+
+## Troubleshooting
+
+To troubleshoot issues with the `chrony` collector, run the `go.d.plugin` with the debug option enabled. The
+output should give you clues as to why the collector isn't working.
+
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
+to the `netdata` user.
+
+```bash
+cd /usr/libexec/netdata/plugins.d/
+sudo -u netdata -s
+```
+
+You can now run the `go.d.plugin` to debug the collector:
+
+```bash
+./go.d.plugin -d -m chrony
+```
diff --git a/docs/agent/collectors/go.d.plugin/modules/cockroachdb.md b/docs/agent/collectors/go.d.plugin/modules/cockroachdb.md
index f76afb7e0..c744d37b0 100644
--- a/docs/agent/collectors/go.d.plugin/modules/cockroachdb.md
+++ b/docs/agent/collectors/go.d.plugin/modules/cockroachdb.md
@@ -156,7 +156,7 @@ configurable. It doesn't make sense to decrease the value.
To troubleshoot issues with the `cockroachdb` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/consul.md b/docs/agent/collectors/go.d.plugin/modules/consul.md
index d51cea83e..f5dc36266 100644
--- a/docs/agent/collectors/go.d.plugin/modules/consul.md
+++ b/docs/agent/collectors/go.d.plugin/modules/consul.md
@@ -48,7 +48,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `consul` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/coredns.md b/docs/agent/collectors/go.d.plugin/modules/coredns.md
index 5437e7a98..5fd7f9991 100644
--- a/docs/agent/collectors/go.d.plugin/modules/coredns.md
+++ b/docs/agent/collectors/go.d.plugin/modules/coredns.md
@@ -73,7 +73,7 @@ module's [configuration file](https://github.com/netdata/go.d.plugin/blob/master
To troubleshoot issues with the `coredns` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/couchbase.md b/docs/agent/collectors/go.d.plugin/modules/couchbase.md
index ad0a5429a..ae398b12a 100644
--- a/docs/agent/collectors/go.d.plugin/modules/couchbase.md
+++ b/docs/agent/collectors/go.d.plugin/modules/couchbase.md
@@ -64,7 +64,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `couchbase`, run the `go.d.plugin` with the debug option enabled. The output should give
you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/couchdb.md b/docs/agent/collectors/go.d.plugin/modules/couchdb.md
index a0b136e08..148687909 100644
--- a/docs/agent/collectors/go.d.plugin/modules/couchdb.md
+++ b/docs/agent/collectors/go.d.plugin/modules/couchdb.md
@@ -62,7 +62,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `couchdb` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/dnsdist.md b/docs/agent/collectors/go.d.plugin/modules/dnsdist.md
index ad8d9fda6..f6fae1a3e 100644
--- a/docs/agent/collectors/go.d.plugin/modules/dnsdist.md
+++ b/docs/agent/collectors/go.d.plugin/modules/dnsdist.md
@@ -71,7 +71,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `dnsdist` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/dnsmasq.md b/docs/agent/collectors/go.d.plugin/modules/dnsmasq.md
index a3131b5b8..c11a504cc 100644
--- a/docs/agent/collectors/go.d.plugin/modules/dnsmasq.md
+++ b/docs/agent/collectors/go.d.plugin/modules/dnsmasq.md
@@ -65,7 +65,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `dnsmasq` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/dnsmasq_dhcp.md b/docs/agent/collectors/go.d.plugin/modules/dnsmasq_dhcp.md
index 56e164510..70943966f 100644
--- a/docs/agent/collectors/go.d.plugin/modules/dnsmasq_dhcp.md
+++ b/docs/agent/collectors/go.d.plugin/modules/dnsmasq_dhcp.md
@@ -57,7 +57,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `dnsmasq_dhcp` collector, run the `go.d.plugin` with the debug option enabled. The
output should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/dnsquery.md b/docs/agent/collectors/go.d.plugin/modules/dnsquery.md
index 373549e2a..8e2bb34ba 100644
--- a/docs/agent/collectors/go.d.plugin/modules/dnsquery.md
+++ b/docs/agent/collectors/go.d.plugin/modules/dnsquery.md
@@ -47,7 +47,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `dns_query` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/docker_engine.md b/docs/agent/collectors/go.d.plugin/modules/docker_engine.md
index e0ad9e572..1245ae8d1 100644
--- a/docs/agent/collectors/go.d.plugin/modules/docker_engine.md
+++ b/docs/agent/collectors/go.d.plugin/modules/docker_engine.md
@@ -25,7 +25,7 @@ It produces the following charts:
- Builder Builds Fails By Reason in `fails/s`
- Health Checks in `events/s`
-If Docker is running in in [Swarm mode](https://docs.docker.com/engine/swarm/) and the instance is a Swarm manager:
+If Docker is running in [Swarm mode](https://docs.docker.com/engine/swarm/) and the instance is a Swarm manager:
- Swarm Manager Leader in `bool`
- Swarm Manager Object Store in `count`
@@ -61,7 +61,7 @@ module's [configuration file](https://github.com/netdata/go.d.plugin/blob/master
To troubleshoot issues with the `docker_engine` collector, run the `go.d.plugin` with the debug option enabled. The
output should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/dockerhub.md b/docs/agent/collectors/go.d.plugin/modules/dockerhub.md
index f69a5675d..648220f3b 100644
--- a/docs/agent/collectors/go.d.plugin/modules/dockerhub.md
+++ b/docs/agent/collectors/go.d.plugin/modules/dockerhub.md
@@ -52,7 +52,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `dockerhub` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/elasticsearch.md b/docs/agent/collectors/go.d.plugin/modules/elasticsearch.md
index b5bf02604..0035591ab 100644
--- a/docs/agent/collectors/go.d.plugin/modules/elasticsearch.md
+++ b/docs/agent/collectors/go.d.plugin/modules/elasticsearch.md
@@ -122,7 +122,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `elasticsearch` collector, run the `go.d.plugin` with the debug option enabled. The
output should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/energid.md b/docs/agent/collectors/go.d.plugin/modules/energid.md
index 4d2499baa..a68d782fa 100644
--- a/docs/agent/collectors/go.d.plugin/modules/energid.md
+++ b/docs/agent/collectors/go.d.plugin/modules/energid.md
@@ -55,7 +55,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `energid` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/example.md b/docs/agent/collectors/go.d.plugin/modules/example.md
index a03822c33..b4c02ffd9 100644
--- a/docs/agent/collectors/go.d.plugin/modules/example.md
+++ b/docs/agent/collectors/go.d.plugin/modules/example.md
@@ -57,7 +57,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `example` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/filecheck.md b/docs/agent/collectors/go.d.plugin/modules/filecheck.md
index 591418ca9..08c4b824f 100644
--- a/docs/agent/collectors/go.d.plugin/modules/filecheck.md
+++ b/docs/agent/collectors/go.d.plugin/modules/filecheck.md
@@ -115,7 +115,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `filecheck` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/fluentd.md b/docs/agent/collectors/go.d.plugin/modules/fluentd.md
index 3d3b3cfa9..5536420b7 100644
--- a/docs/agent/collectors/go.d.plugin/modules/fluentd.md
+++ b/docs/agent/collectors/go.d.plugin/modules/fluentd.md
@@ -60,7 +60,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `fluentd` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/freeradius.md b/docs/agent/collectors/go.d.plugin/modules/freeradius.md
index cad85baa5..97e073d58 100644
--- a/docs/agent/collectors/go.d.plugin/modules/freeradius.md
+++ b/docs/agent/collectors/go.d.plugin/modules/freeradius.md
@@ -69,7 +69,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `freeradius` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/geth.md b/docs/agent/collectors/go.d.plugin/modules/geth.md
index d01b248b3..8ef4c80df 100644
--- a/docs/agent/collectors/go.d.plugin/modules/geth.md
+++ b/docs/agent/collectors/go.d.plugin/modules/geth.md
@@ -11,7 +11,7 @@ Go Ethereum, written in Google’s Go language, is one of the three original imp
alongside C++ and Python.
Go-Ethereum, and subsequently Geth, are built and maintained by the Ethereum community. It’s open source which means
-anyone can contribute to Geth through its [Github](https://github.com/ethereum/go-ethereum).
+anyone can contribute to Geth through its [GitHub](https://github.com/ethereum/go-ethereum).
With Netdata, you can effortlessly monitor your Geth node
@@ -51,13 +51,13 @@ We have started
a [topic](https://community.netdata.cloud/t/lets-build-a-golang-collector-for-monitoring-ethereum-full-nodes/1426) on
our community forums about this collector.
-**The best contribution you can make is to tell us what metrics you want to see and how they should be organized (e.g
+**The best contribution you can make is to tell us what metrics you want to see and how they should be organized (e.g.
what charts to make).**
As you can read in the topic, it's trivial to add more metrics from the prometheus endpoint and create the relevant
charts. The hard part is the domain expertise that we don't have, but you, as a user, have.
-The second best contribution you can make is to tell us what alerts we should be shipping as defaults for this
+The second-best contribution you can make is to tell us what alerts we should be shipping as defaults for this
collector. For example, we are shipping an alert about the node being in sync (or not). We simply compare the
chainhead `block` and `header` values.
@@ -93,7 +93,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `geth` collector, run the `go.d.plugin` with the debug option enabled. The output should
give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/haproxy.md b/docs/agent/collectors/go.d.plugin/modules/haproxy.md
index 3af26cf26..486d3db9c 100644
--- a/docs/agent/collectors/go.d.plugin/modules/haproxy.md
+++ b/docs/agent/collectors/go.d.plugin/modules/haproxy.md
@@ -66,7 +66,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `haproxy` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-- First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on
+- First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on
your system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory,
switch to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/hdfs.md b/docs/agent/collectors/go.d.plugin/modules/hdfs.md
index 4054fd8ca..eeac514af 100644
--- a/docs/agent/collectors/go.d.plugin/modules/hdfs.md
+++ b/docs/agent/collectors/go.d.plugin/modules/hdfs.md
@@ -90,7 +90,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `hdfs` collector, run the `go.d.plugin` with the debug option enabled. The output should
give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/httpcheck.md b/docs/agent/collectors/go.d.plugin/modules/httpcheck.md
index cba6fdc3e..2a6935ee7 100644
--- a/docs/agent/collectors/go.d.plugin/modules/httpcheck.md
+++ b/docs/agent/collectors/go.d.plugin/modules/httpcheck.md
@@ -62,7 +62,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `httpcheck` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/isc_dhcpd.md b/docs/agent/collectors/go.d.plugin/modules/isc_dhcpd.md
index 1faada147..90249faf7 100644
--- a/docs/agent/collectors/go.d.plugin/modules/isc_dhcpd.md
+++ b/docs/agent/collectors/go.d.plugin/modules/isc_dhcpd.md
@@ -69,7 +69,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `isc_dhcpd` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/k8s_kubelet.md b/docs/agent/collectors/go.d.plugin/modules/k8s_kubelet.md
index 3580736d1..3c02672c2 100644
--- a/docs/agent/collectors/go.d.plugin/modules/k8s_kubelet.md
+++ b/docs/agent/collectors/go.d.plugin/modules/k8s_kubelet.md
@@ -67,7 +67,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `k8s_kubelet` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/k8s_kubeproxy.md b/docs/agent/collectors/go.d.plugin/modules/k8s_kubeproxy.md
index df7a325e2..b59222bed 100644
--- a/docs/agent/collectors/go.d.plugin/modules/k8s_kubeproxy.md
+++ b/docs/agent/collectors/go.d.plugin/modules/k8s_kubeproxy.md
@@ -52,7 +52,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `k8s_kubeproxy` collector, run the `go.d.plugin` with the debug option enabled. The
output should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/k8s_state.md b/docs/agent/collectors/go.d.plugin/modules/k8s_state.md
index 3c6872b48..796102578 100644
--- a/docs/agent/collectors/go.d.plugin/modules/k8s_state.md
+++ b/docs/agent/collectors/go.d.plugin/modules/k8s_state.md
@@ -105,7 +105,7 @@ using [netdata/helmchart](https://github.com/netdata/helmchart#netdata-helm-char
To troubleshoot issues with the `k8s_state` collector, run the `go.d.plugin` with the debug option enabled. The
output should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/lighttpd.md b/docs/agent/collectors/go.d.plugin/modules/lighttpd.md
index 6dc7032fd..194b464f9 100644
--- a/docs/agent/collectors/go.d.plugin/modules/lighttpd.md
+++ b/docs/agent/collectors/go.d.plugin/modules/lighttpd.md
@@ -55,7 +55,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `lighttpd` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/lighttpd2.md b/docs/agent/collectors/go.d.plugin/modules/lighttpd2.md
index a4abdb8cb..84581524e 100644
--- a/docs/agent/collectors/go.d.plugin/modules/lighttpd2.md
+++ b/docs/agent/collectors/go.d.plugin/modules/lighttpd2.md
@@ -56,7 +56,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `lighttpd2` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/logstash.md b/docs/agent/collectors/go.d.plugin/modules/logstash.md
index e23ad972d..7f9c4a87b 100644
--- a/docs/agent/collectors/go.d.plugin/modules/logstash.md
+++ b/docs/agent/collectors/go.d.plugin/modules/logstash.md
@@ -55,7 +55,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `logstash` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/mongodb.md b/docs/agent/collectors/go.d.plugin/modules/mongodb.md
index 460b70ce2..94d390d51 100644
--- a/docs/agent/collectors/go.d.plugin/modules/mongodb.md
+++ b/docs/agent/collectors/go.d.plugin/modules/mongodb.md
@@ -38,8 +38,8 @@ Works with local and cloud hosted [`Atlas`](https://www.mongodb.com/cloud/atlas)
#### Operations Latency
-- ops reads in `milliseconds`
-- ops writes in `milliseconds`
+- reads in `milliseconds`
+- writes in `milliseconds`
- commands in `milliseconds`
#### Connections
@@ -334,7 +334,8 @@ Round trip time between members and local instance in `milliseconds`
### Sharding
-Charts are available on shards only for [mongos](https://docs.mongodb.com/manual/reference/command/serverStatus/#mongodb-serverstatus-serverstatus.process)
+Charts are available on shards only
+for [mongos](https://docs.mongodb.com/manual/reference/command/serverStatus/#mongodb-serverstatus-serverstatus.process)
#### Transaction Commit Types
@@ -360,14 +361,14 @@ Number of chucks per node in `chunks`
Create a read-only user for Netdata in the admin database.
-1. Authenticate as the admin user.
+- Authenticate as the admin user.
-```
-use admin
-db.auth("admin", "")
-```
+ ```
+ use admin
+ db.auth("admin", "")
+ ```
-2. Create a user.
+- Create a user.
```
# MongoDB 2.x.
@@ -413,7 +414,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `mongodb` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/mysql.md b/docs/agent/collectors/go.d.plugin/modules/mysql.md
index 68d535784..1242cf8dd 100644
--- a/docs/agent/collectors/go.d.plugin/modules/mysql.md
+++ b/docs/agent/collectors/go.d.plugin/modules/mysql.md
@@ -153,7 +153,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `mysql` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/nginx.md b/docs/agent/collectors/go.d.plugin/modules/nginx.md
index d6dc2a985..1a8197da9 100644
--- a/docs/agent/collectors/go.d.plugin/modules/nginx.md
+++ b/docs/agent/collectors/go.d.plugin/modules/nginx.md
@@ -55,7 +55,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `nginx` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/nginxvts.md b/docs/agent/collectors/go.d.plugin/modules/nginxvts.md
index 6f0ad1242..1a93a2f7e 100644
--- a/docs/agent/collectors/go.d.plugin/modules/nginxvts.md
+++ b/docs/agent/collectors/go.d.plugin/modules/nginxvts.md
@@ -34,8 +34,8 @@ Refer [`nginx-module-vts`](https://github.com/vozlt/nginx-module-vts#json) for m
## Configuration
-Edit the `go.d/nginxvts.conf` configuration file using `edit-config` from the your
-agent's [config directory](/docs/configure/nodes), which is typically at `/etc/netdata`.
+Edit the `go.d/nginxvts.conf` configuration file using `edit-config` from the
+Netdata [config directory](/docs/configure/nodes), which is typically at `/etc/netdata`.
```bash
cd /etc/netdata # Replace this path with your Netdata config directory
@@ -60,7 +60,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `nginxvts` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/openvpn.md b/docs/agent/collectors/go.d.plugin/modules/openvpn.md
index b6a0c4747..5ec100bd5 100644
--- a/docs/agent/collectors/go.d.plugin/modules/openvpn.md
+++ b/docs/agent/collectors/go.d.plugin/modules/openvpn.md
@@ -66,7 +66,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `openvpn` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/openvpn_status_log.md b/docs/agent/collectors/go.d.plugin/modules/openvpn_status_log.md
index bb7bea665..9c6c7de28 100644
--- a/docs/agent/collectors/go.d.plugin/modules/openvpn_status_log.md
+++ b/docs/agent/collectors/go.d.plugin/modules/openvpn_status_log.md
@@ -1,28 +1,27 @@
---
title: "OpenVPN monitoring with Netdata(based on status log)"
-custom_edit_url: https://github.com/netdata/go.d.plugin/edit/master/modules/openvpn_status/README.md
+custom_edit_url: https://github.com/netdata/go.d.plugin/edit/master/modules/openvpn_status_log/README.md
sidebar_label: "OpenVPN(StatusLog)"
---
-Parses server log files and provides summary (client, traffic) metrics. Please *note* that this collector is similar to another OpenVPN collector. However, this collector requires status logs from OpenVPN in contrast to another collector that requires Management Interface enabled.
+Parses server log files and provides summary (client, traffic) metrics. Please *note* that this collector is similar to
+another OpenVPN collector. However, this collector requires status logs from OpenVPN in contrast to another collector
+that requires Management Interface enabled.
## Requirements
-- If you are running multiple OpenVPN instances out of the same directory, MAKE SURE TO EDIT DIRECTIVES which create output files
- so that multiple instances do not overwrite each other's output files.
+- make sure `netdata` user can read `openvpn-status.log`.
-- Make sure NETDATA USER CAN READ openvpn-status.log
-
-- Update_every interval MUST MATCH interval on which OpenVPN writes operational status to log file.
+- `update_every` interval must match the interval on which OpenVPN writes the operational status to the log file.
## Charts
It produces the following charts:
-- Total Number Of Active Clients in `clients`
-- Total Traffic in `kilobits/s`
+- Active Clients in `clients`
+- Traffic in `kilobits/s`
Per user charts (disabled by default, see `per_user_stats` in the module config file):
@@ -31,20 +30,15 @@ Per user charts (disabled by default, see `per_user_stats` in the module config
## Configuration
-Edit the `go.d/openvpn_status.conf` configuration file using `edit-config` from the Netdata [config
-directory](/docs/configure/nodes), which is typically at `/etc/netdata`.
+Edit the `go.d/openvpn_status_log.conf` configuration file using `edit-config` from the
+Netdata [config directory](/docs/configure/nodes), which is typically at `/etc/netdata`.
```bash
cd /etc/netdata # Replace this path with your Netdata config directory, if different
-sudo ./edit-config go.d/openvpn_status.conf
+sudo ./edit-config go.d/openvpn_status_log.conf
```
-Samples:
-
-```yaml
-default
- log_path : '/var/log/openvpn-status.log'
-```
+Configuration example:
```yaml
jobs:
@@ -55,18 +49,17 @@ jobs:
- "* *"
```
-
For all available options please see
-module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/config/go.d/openvpn_status.conf).
+module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/config/go.d/openvpn_status_log.conf).
---
## Troubleshooting
-To troubleshoot issues with the `openvpn_status` collector, run the `go.d.plugin` with the debug option enabled. The output
-should give you clues as to why the collector isn't working.
+To troubleshoot issues with the `openvpn_status_log` collector, run the `go.d.plugin` with the debug option enabled. The
+output should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
@@ -78,5 +71,5 @@ sudo -u netdata -s
You can now run the `go.d.plugin` to debug the collector:
```bash
-./go.d.plugin -d -m openvpn_status
+./go.d.plugin -d -m openvpn_status_log
```
diff --git a/docs/agent/collectors/go.d.plugin/modules/pgbouncer.md b/docs/agent/collectors/go.d.plugin/modules/pgbouncer.md
new file mode 100644
index 000000000..03b4ad234
--- /dev/null
+++ b/docs/agent/collectors/go.d.plugin/modules/pgbouncer.md
@@ -0,0 +1,118 @@
+---
+title: "PgBouncer monitoring with Netdata"
+description: "Monitor client and server connections and databases statistics."
+custom_edit_url: https://github.com/netdata/go.d.plugin/edit/master/modules/pgbouncer/README.md
+sidebar_label: "PgBouncer"
+---
+
+
+
+[PgBouncer](https://www.pgbouncer.org/) is an open-source connection pooler
+for [PostgreSQL](https://www.postgresql.org/).
+
+This module monitors one or more PgBouncer servers, depending on your configuration.
+
+Executed queries:
+
+- `SHOW VERSION;`
+- `SHOW CONFIG;`
+- `SHOW DATABASES;`
+- `SHOW STATS;`
+- `SHOW POOLS;`
+
+Information about the queries can be found in the [PgBouncer Documentation](http://pgbouncer.org/usage.html).
+
+## Requirements
+
+- PgBouncer v1.8.0+.
+- A user with `stats_users` permissions to query your PgBouncer instance.
+
+To create the `netdata` user:
+
+- Add `netdata` user to the `pgbouncer.ini` file:
+
+ ```text
+ stats_users = netdata
+ ```
+
+- Add a password for the `netdata` user to the `userlist.txt` file:
+
+ ```text
+ "netdata" ""
+ ```
+
+- To verify the credentials, run the following command
+
+ ```bash
+ psql -h localhost -U netdata -p 6432 pgbouncer -c "SHOW VERSION;" >/dev/null 2>&1 && echo OK || echo FAIL
+ ```
+
+ When it prompts for a password, enter the password you added to `userlist.txt`.
+
+## Metrics
+
+All metrics have "pgbouncer." prefix.
+
+| Metric | Scope | Dimensions | Units |
+|-----------------------------------|:--------:|:---------------------------------:|:--------------:|
+| client_connections_utilization | global | used | percentage |
+| db_client_connections | database | active, waiting, cancel_req | connections |
+| db_server_connections | database | active, idle, used, tested, login | connections |
+| db_server_connections_utilization | database | used | percentage |
+| db_clients_wait_time | database | time | seconds |
+| db_client_max_wait_time | database | time | seconds |
+| db_transactions | database | transactions | transactions/s |
+| db_transactions_time | database | time | seconds |
+| db_transaction_avg_time | database | time | seconds |
+| db_queries | database | queries | queries/s |
+| db_queries_time | database | time | seconds |
+| db_query_avg_time | database | time | seconds |
+| db_network_io | database | received, sent | B/s |
+
+## Configuration
+
+Edit the `go.d/pgbouncer.conf` configuration file using `edit-config` from the
+Netdata [config directory](/docs/configure/nodes), which is typically at `/etc/netdata`.
+
+```bash
+cd /etc/netdata # Replace this path with your Netdata config directory
+sudo ./edit-config go.d/pgbouncer.conf
+```
+
+DSN (Data Source Name) may either be in URL format or key=word format.
+See [Connection Strings](https://www.postgresql.org/docs/current/libpq-connect.html#LIBPQ-CONNSTRING) for details.
+
+```yaml
+jobs:
+ - name: local
+ dsn: 'postgres://postgres:postgres@127.0.0.1:6432/pgbouncer'
+
+ - name: local
+ dsn: 'host=/tmp dbname=pgbouncer user=postgres port=6432'
+
+ - name: remote
+ dsn: 'postgres://postgres:postgres@203.0.113.10:6432/pgbouncer'
+```
+
+For all available options see
+module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/config/go.d/pgbouncer.conf).
+
+## Troubleshooting
+
+To troubleshoot issues with the `pgbouncer` collector, run the `go.d.plugin` with the debug option enabled. The output
+should give you clues as to why the collector isn't working.
+
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
+to the `netdata` user.
+
+```bash
+cd /usr/libexec/netdata/plugins.d/
+sudo -u netdata -s
+```
+
+You can now run the `go.d.plugin` to debug the collector:
+
+```bash
+./go.d.plugin -d -m pgbouncer
+```
diff --git a/docs/agent/collectors/go.d.plugin/modules/phpdaemon.md b/docs/agent/collectors/go.d.plugin/modules/phpdaemon.md
index fbb746b71..aec670fad 100644
--- a/docs/agent/collectors/go.d.plugin/modules/phpdaemon.md
+++ b/docs/agent/collectors/go.d.plugin/modules/phpdaemon.md
@@ -126,7 +126,7 @@ class FullStatusRequest extends Generic {
To troubleshoot issues with the `phpdaemon` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/phpfpm.md b/docs/agent/collectors/go.d.plugin/modules/phpfpm.md
index 134d761cf..64d80ac81 100644
--- a/docs/agent/collectors/go.d.plugin/modules/phpfpm.md
+++ b/docs/agent/collectors/go.d.plugin/modules/phpfpm.md
@@ -65,7 +65,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `phpfpm` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/pihole.md b/docs/agent/collectors/go.d.plugin/modules/pihole.md
index dcc147964..557e4ff02 100644
--- a/docs/agent/collectors/go.d.plugin/modules/pihole.md
+++ b/docs/agent/collectors/go.d.plugin/modules/pihole.md
@@ -12,7 +12,7 @@ acts as a DNS sinkhole, intended for use on a private network.
This module will monitor one or more `Pi-hole` instances using [PHP API](https://github.com/pi-hole/AdminLTE).
-The API exposed data time frame is `for the last 24 hr`. All collected values are for that time time frame, not for the
+The API exposed data time frame is `for the last 24 hr`. All collected values are for that time frame, not for the
module collection interval.
## Charts
@@ -77,7 +77,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `pihole` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/pika.md b/docs/agent/collectors/go.d.plugin/modules/pika.md
index 00df80059..2638b80a5 100644
--- a/docs/agent/collectors/go.d.plugin/modules/pika.md
+++ b/docs/agent/collectors/go.d.plugin/modules/pika.md
@@ -82,8 +82,8 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `pika` collector, run the `go.d.plugin` with the debug option enabled. The output should
give you clues as to why the collector isn't working.
-
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+'
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/portcheck.md b/docs/agent/collectors/go.d.plugin/modules/portcheck.md
index 296f7afa2..38b14927b 100644
--- a/docs/agent/collectors/go.d.plugin/modules/portcheck.md
+++ b/docs/agent/collectors/go.d.plugin/modules/portcheck.md
@@ -7,7 +7,7 @@ sidebar_label: "TCP endpoints"
-This module will monitors one or more TCP services availability and response time.
+This module monitors one or more TCP services availability and response time.
## Charts
@@ -53,7 +53,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `portcheck` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/postgres.md b/docs/agent/collectors/go.d.plugin/modules/postgres.md
new file mode 100644
index 000000000..8df326567
--- /dev/null
+++ b/docs/agent/collectors/go.d.plugin/modules/postgres.md
@@ -0,0 +1,112 @@
+---
+title: "PostgreSQL monitoring with Netdata"
+description: "Monitor connections, replication, databases, locks, and more with zero configuration and per-second metric granularity."
+custom_edit_url: https://github.com/netdata/go.d.plugin/edit/master/modules/postgres/README.md
+sidebar_label: "PostgresSQL"
+---
+
+
+
+[PostgreSQL](https://www.postgresql.org/), also known as Postgres, is a free and open-source relational database
+management system emphasizing extensibility and SQL compliance.
+
+This module monitors one or more Postgres servers, depending on your configuration.
+
+## Requirements
+
+- PostgreSQL v9.4+
+- User with granted `pg_monitor`
+ or `pg_read_all_stat` [built-in role](https://www.postgresql.org/docs/current/predefined-roles.html).
+
+## Metrics
+
+All metrics have "postgres." prefix.
+
+| Metric | Scope | Dimensions | Units |
+|--------------------------------------|:-------------------:|:------------------------------------------------------------------------------------------------------------------------------------------:|:--------------:|
+| connections_utilization | global | used | percentage |
+| connections_usage | global | available, used | connections |
+| checkpoints | global | scheduled, requested | checkpoints/s |
+| checkpoint_time | global | write, sync | milliseconds |
+| bgwriter_buffers_alloc | global | allocated | B/s |
+| bgwriter_buffers_written | global | checkpoint, backend, clean | B/s |
+| bgwriter_maxwritten_clean | global | maxwritten | events/s |
+| bgwriter_buffers_backend_fsync | global | fsync | operations/s |
+| wal_writes | global | writes | B/s |
+| wal_files | global | written, recycled | files |
+| wal_archive_files | global | ready, done | files/s |
+| autovacuum_workers | global | analyze, vacuum_analyze, vacuum, vacuum_freeze, brin_summarize | workers |
+| percent_towards_emergency_autovacuum | global | emergency_autovacuum | percentage |
+| percent_towards_txid_wraparound | global | txid_wraparound | percentage |
+| oldest_transaction_xid | global | xid | xid |
+| catalog_relation_count | global | ordinary_table, index, sequence, toast_table, view, materialized_view, composite_type, foreign_table, partitioned_table, partitioned_index | relations |
+| catalog_relation_size | global | ordinary_table, index, sequence, toast_table, view, materialized_view, composite_type, foreign_table, partitioned_table, partitioned_index | B |
+| uptime | global | uptime | seconds |
+| replication_standby_app_wal_delta | standby application | sent_delta, write_delta, flush_delta, replay_delta | B |
+| replication_standby_app_wal_lag | standby application | write_lag, flush_lag, replay_lag | seconds |
+| replication_standby_app_wal_lag | replication slot | wal_keep, pg_replslot_files | files |
+| db_transactions_ratio | database | committed, rollback | percentage |
+| db_transactions | database | committed, rollback | transactions/s |
+| db_connections_utilization | database | used | percentage |
+| db_connections | database | connections | connections |
+| db_buffer_cache_hit_ratio | database | hit, miss | percentage |
+| db_blocks_read | database | memory, disk | blocks/s |
+| db_rows_read_ratio | database | returned, fetched | percentage |
+| db_rows_read | database | returned, fetched | rows/s |
+| db_rows_written | database | inserted, deleted, updated | rows/s |
+| db_conflicts | database | conflicts | queries/s |
+| db_conflicts_stat | database | tablespace, lock, snapshot, bufferpin, deadlock | queries/s |
+| db_deadlocks | database | deadlocks | deadlocks/s |
+| db_locks_held | database | access_share, row_share, row_exclusive, share_update, share, share_row_exclusive, exclusive, access_exclusive | locks |
+| db_locks_awaited | database | access_share, row_share, row_exclusive, share_update, share, share_row_exclusive, exclusive, access_exclusive | locks |
+| db_temp_files | database | written | files/s |
+| db_temp_files_data | database | written | B/s |
+| db_size | database | size | B |
+
+## Configuration
+
+Edit the `go.d/postgres.conf` configuration file using `edit-config` from the
+Netdata [config directory](/docs/configure/nodes), which is typically at `/etc/netdata`.
+
+```bash
+cd /etc/netdata # Replace this path with your Netdata config directory
+sudo ./edit-config go.d/postgres.conf
+```
+
+DSN (Data Source Name) may either be in URL format or key=word format.
+See [Connection Strings](https://www.postgresql.org/docs/current/libpq-connect.html#LIBPQ-CONNSTRING) for details.
+
+```yaml
+jobs:
+ - name: local
+ dsn: 'postgres://postgres:postgres@127.0.0.1:5432/postgres'
+
+ - name: local
+ dsn: 'host=/var/run/postgresql dbname=postgres user=postgres'
+
+ - name: remote
+ dsn: 'postgres://postgres:postgres@203.0.113.10:5432/postgres'
+```
+
+For all available options see
+module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/config/go.d/postgres.conf).
+
+## Troubleshooting
+
+To troubleshoot issues with the `postgres` collector, run the `go.d.plugin` with the debug option enabled. The output
+should give you clues as to why the collector isn't working.
+
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
+to the `netdata` user.
+
+```bash
+cd /usr/libexec/netdata/plugins.d/
+sudo -u netdata -s
+```
+
+You can now run the `go.d.plugin` to debug the collector:
+
+```bash
+./go.d.plugin -d -m postgres
+```
diff --git a/docs/agent/collectors/go.d.plugin/modules/powerdns.md b/docs/agent/collectors/go.d.plugin/modules/powerdns.md
index b6306a9dd..da5d7c3c0 100644
--- a/docs/agent/collectors/go.d.plugin/modules/powerdns.md
+++ b/docs/agent/collectors/go.d.plugin/modules/powerdns.md
@@ -69,7 +69,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `powerdns` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/powerdns_recursor.md b/docs/agent/collectors/go.d.plugin/modules/powerdns_recursor.md
index 4d79a4dc5..8ad87c230 100644
--- a/docs/agent/collectors/go.d.plugin/modules/powerdns_recursor.md
+++ b/docs/agent/collectors/go.d.plugin/modules/powerdns_recursor.md
@@ -68,7 +68,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `powerdns_recursor` collector, run the `go.d.plugin` with the debug option enabled. The
output should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/prometheus.md b/docs/agent/collectors/go.d.plugin/modules/prometheus.md
index 299121a0d..d7188f2ca 100644
--- a/docs/agent/collectors/go.d.plugin/modules/prometheus.md
+++ b/docs/agent/collectors/go.d.plugin/modules/prometheus.md
@@ -214,7 +214,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `prometheus` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/pulsar.md b/docs/agent/collectors/go.d.plugin/modules/pulsar.md
index 525fc8d13..c164de3f3 100644
--- a/docs/agent/collectors/go.d.plugin/modules/pulsar.md
+++ b/docs/agent/collectors/go.d.plugin/modules/pulsar.md
@@ -121,7 +121,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
## Topic filtering
-By default module collects data for all topics but it supports topic filtering. Filtering doesnt exclude a topic stats
+By default, module collects data for all topics, but it supports topic filtering. Filtering doesn't exclude a topic stats
from the [summary](#summary)/[namespace](#namespace) stats, it only removes the topic from the [topic](#topic) charts.
To check matcher syntax
@@ -153,7 +153,7 @@ Module `update_every` should be equal to `statsUpdateFrequencyInSecs`.
To troubleshoot issues with the `pulsar` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/rabbitmq.md b/docs/agent/collectors/go.d.plugin/modules/rabbitmq.md
index af688db35..bebc04097 100644
--- a/docs/agent/collectors/go.d.plugin/modules/rabbitmq.md
+++ b/docs/agent/collectors/go.d.plugin/modules/rabbitmq.md
@@ -65,7 +65,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `rabbitmq` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/redis.md b/docs/agent/collectors/go.d.plugin/modules/redis.md
index 1dfab5182..d05268b92 100644
--- a/docs/agent/collectors/go.d.plugin/modules/redis.md
+++ b/docs/agent/collectors/go.d.plugin/modules/redis.md
@@ -41,7 +41,7 @@ It collects information and statistics about the server executing the following
### Persistence RDB
- Operations that produced changes since the last SAVE or BGSAVE in `operations`
-- Duration of the on-going RDB save operation if any in `seconds`
+- Duration of the ongoing RDB save operation if any in `seconds`
- Status of the last RDB save operation in `status`
### Persistence AOF
@@ -106,7 +106,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `redis` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/scaleio.md b/docs/agent/collectors/go.d.plugin/modules/scaleio.md
index 6cc4bd30f..51e5fb843 100644
--- a/docs/agent/collectors/go.d.plugin/modules/scaleio.md
+++ b/docs/agent/collectors/go.d.plugin/modules/scaleio.md
@@ -101,7 +101,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `scaleio` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/snmp.md b/docs/agent/collectors/go.d.plugin/modules/snmp.md
index 4657c4965..2c9a00b5e 100644
--- a/docs/agent/collectors/go.d.plugin/modules/snmp.md
+++ b/docs/agent/collectors/go.d.plugin/modules/snmp.md
@@ -311,7 +311,7 @@ snmpwalk -t 20 -O fn -v 2c -c public 192.0.2.1
To troubleshoot issues with the `snmp` collector, run the `go.d.plugin` with the debug option enabled. The output should
give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/solr.md b/docs/agent/collectors/go.d.plugin/modules/solr.md
index 4e2c70040..2ce369a2e 100644
--- a/docs/agent/collectors/go.d.plugin/modules/solr.md
+++ b/docs/agent/collectors/go.d.plugin/modules/solr.md
@@ -63,7 +63,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `solr` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/springboot2.md b/docs/agent/collectors/go.d.plugin/modules/springboot2.md
index 080a84912..e51581299 100644
--- a/docs/agent/collectors/go.d.plugin/modules/springboot2.md
+++ b/docs/agent/collectors/go.d.plugin/modules/springboot2.md
@@ -64,7 +64,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `springboot2` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/squidlog.md b/docs/agent/collectors/go.d.plugin/modules/squidlog.md
index e49ee54f8..33a88bcae 100644
--- a/docs/agent/collectors/go.d.plugin/modules/squidlog.md
+++ b/docs/agent/collectors/go.d.plugin/modules/squidlog.md
@@ -42,7 +42,7 @@ Squidlog supports 3 log parsers:
- LTSV
- RegExp
-RegExp is the slowest among them but it is very likely you will need to use it if your log format is not default.
+RegExp is the slowest among them, but it is very likely you will need to use it if your log format is not default.
## Known Fields
@@ -80,7 +80,7 @@ Custom log format is easy. Use [known fields](#known-fields) to construct your l
- If using CSV parser
**Note**: can be used only if all known squid format codes are separated by csv delimiter. For example, if you
-have `%Ss:%Sh`, csv parser cant extract `%Ss` and `%Sh` from it and you need to use RegExp parser.
+have `%Ss:%Sh`, csv parser cant extract `%Ss` and `%Sh` from it, and you need to use RegExp parser.
Copy your current log format. Replace all known squid format codes with corresponding [known](#known-fields) fields.
Replaces others with "-".
@@ -151,7 +151,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `squid_log` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/supervisord.md b/docs/agent/collectors/go.d.plugin/modules/supervisord.md
index 4225b4651..29a753fd9 100644
--- a/docs/agent/collectors/go.d.plugin/modules/supervisord.md
+++ b/docs/agent/collectors/go.d.plugin/modules/supervisord.md
@@ -67,7 +67,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `supervisord` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/systemdunits.md b/docs/agent/collectors/go.d.plugin/modules/systemdunits.md
index fe3b82a67..25e3c0400 100644
--- a/docs/agent/collectors/go.d.plugin/modules/systemdunits.md
+++ b/docs/agent/collectors/go.d.plugin/modules/systemdunits.md
@@ -56,7 +56,7 @@ cd /etc/netdata # Replace this path with your Netdata config directory
sudo ./edit-config go.d/systemdunits.conf
```
-Needs only `include` option. Syntax is [shell file name pattern](https://golang.org/pkg/path/filepath/#Match).
+Needs only `include` option. Syntax is the [shell file name pattern](https://golang.org/pkg/path/filepath/#Match).
Here are some examples:
@@ -83,7 +83,7 @@ collector's [configuration file](https://github.com/netdata/go.d.plugin/blob/mas
To troubleshoot issues with the `systemdunits` collector, run the `go.d.plugin` with the debug option enabled. The
output should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/tengine.md b/docs/agent/collectors/go.d.plugin/modules/tengine.md
index 12531d864..e40fbb3c1 100644
--- a/docs/agent/collectors/go.d.plugin/modules/tengine.md
+++ b/docs/agent/collectors/go.d.plugin/modules/tengine.md
@@ -59,7 +59,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `tengine` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/traefik.md b/docs/agent/collectors/go.d.plugin/modules/traefik.md
index 7f05b607b..1435ab5dc 100644
--- a/docs/agent/collectors/go.d.plugin/modules/traefik.md
+++ b/docs/agent/collectors/go.d.plugin/modules/traefik.md
@@ -55,7 +55,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `traefik` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-- First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on
+- First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on
your system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory,
switch to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/unbound.md b/docs/agent/collectors/go.d.plugin/modules/unbound.md
index 1f7325f14..5dab78d5a 100644
--- a/docs/agent/collectors/go.d.plugin/modules/unbound.md
+++ b/docs/agent/collectors/go.d.plugin/modules/unbound.md
@@ -30,7 +30,7 @@ If TLS is enabled, in addition:
- `control-key-file` should be readable by `netdata` user
- `control-cert-file` should be readable by `netdata` user
-For auto detection parameters from `unbound.conf`:
+For auto-detection parameters from `unbound.conf`:
- `unbound.conf` should be readable by `netdata` user
- if you have several configuration files (include feature) all of them should be readable by `netdata` user
@@ -93,7 +93,7 @@ sudo ./edit-config go.d/unbound.conf
```
This Unbound collector only needs the `address` to a server's `remote-control` interface if TLS is disabled or `address`
-of unix socket. Otherwise you need to set path to the `control-key-file` and `control-cert-file` files.
+of unix socket. Otherwise, you need to set path to the `control-key-file` and `control-cert-file` files.
The module tries to auto-detect following parameters reading `unbound.conf`:
@@ -104,7 +104,7 @@ The module tries to auto-detect following parameters reading `unbound.conf`:
- tls_key
Module supports both cumulative and non-cumulative modes. Default is non-cumulative. If your server has enabled
-`statistics-cumulative`, but the module fails to auto-detect it (`unbound.conf` is not readable or it is a remote
+`statistics-cumulative`, but the module fails to auto-detect it (`unbound.conf` is not readable, or it is a remote
server), you need to set it manually in the configuration file.
Here is an example for several servers:
@@ -148,7 +148,7 @@ have the control protocol set up correctly.
To troubleshoot issues with the `unbound` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/vcsa.md b/docs/agent/collectors/go.d.plugin/modules/vcsa.md
index 17adec7b4..f6b04a322 100644
--- a/docs/agent/collectors/go.d.plugin/modules/vcsa.md
+++ b/docs/agent/collectors/go.d.plugin/modules/vcsa.md
@@ -91,7 +91,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `vcsa` collector, run the `go.d.plugin` with the debug option enabled. The output should
give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/vernemq.md b/docs/agent/collectors/go.d.plugin/modules/vernemq.md
index 05126ff4c..37524554f 100644
--- a/docs/agent/collectors/go.d.plugin/modules/vernemq.md
+++ b/docs/agent/collectors/go.d.plugin/modules/vernemq.md
@@ -48,15 +48,15 @@ It produces the following charts:
- Erlang Processes in `processes`
- Reductions in `ops/s`
- Context Switches in `ops/s`
-- Received and Sent Traffic through Ports in `KiB/s`
-- Processes that are Ready to Run on All Run-Queues in `KiB/s`
+- Received and Sent Traffic through Ports in `kilobits/s`
+- Processes that are Ready to Run on All Run-Queues in `processes`
- GC Count in `KiB/s`
- GC Words Reclaimed in `KiB/s`
- Memory Allocated by the Erlang Processes and by the Emulator in `KiB`
#### Bandwidth
-- Bandwidth in `KiB/s`
+- Bandwidth in `kilobits/s`
#### Retain
@@ -65,8 +65,8 @@ It produces the following charts:
#### Cluster
-- Communication with Other Cluster Nodes in `KiB/s`
-- Traffic Dropped During Communication with Other Cluster Nodes in `KiB/s`
+- Communication with Other Cluster Nodes in `kilobits/s`
+- Traffic Dropped During Communication with Other Cluster Nodes in `kilobits/s`
- Unresolved Netsplits in `netsplits`
- Netsplits in `netsplits/s`
@@ -156,7 +156,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `vernemq` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/vsphere.md b/docs/agent/collectors/go.d.plugin/modules/vsphere.md
index 9aa91c817..46caee00f 100644
--- a/docs/agent/collectors/go.d.plugin/modules/vsphere.md
+++ b/docs/agent/collectors/go.d.plugin/modules/vsphere.md
@@ -12,6 +12,9 @@ that provides a centralized platform for controlling your VMware vSphere environ
This module collects hosts and vms performance statistics from one or more `vCenter` servers depending on configuration.
+> **Warning**: The `vsphere` collector cannot re-login and continue collecting metrics after a vCenter reboot.
+> go.d.plugin needs to be restarted.
+
## Charts
It produces the following charts:
@@ -65,15 +68,15 @@ jobs:
url: https://203.0.113.0
username: admin@vsphere.local
password: somepassword
- host_include: [ '/*' ]
- vm_include: [ '/*' ]
+ host_include: ['/*']
+ vm_include: ['/*']
- name: vcenter2
url: https://203.0.113.10
username: admin@vsphere.local
password: somepassword
- host_include: [ '/*' ]
- vm_include: [ '/*' ]
+ host_include: ['/*']
+ vm_include: ['/*']
```
For all available options please see
@@ -109,7 +112,7 @@ vm_include: # allow all vms from datacenters whose names starts with DC1 and fro
## Update every
-Default `update_every` is 20 seconds and it doesnt make sense to decrease the value. **VMware real-time statistics are
+Default `update_every` is 20 seconds, and it doesn't make sense to decrease the value. **VMware real-time statistics are
generated at the 20-seconds specificity**.
It is likely that 20 seconds is not enough for big installations and the value should be tuned.
@@ -148,7 +151,7 @@ Example (all not related debug lines were removed):
```
There you can see that discovering took `525.614041ms`, collecting metrics took `154.77997ms`. Discovering is a separate
-thread, it doesnt affect collecting.
+thread, it doesn't affect collecting.
`update_every` and `timeout` parameters should be adjusted based on these numbers.
@@ -157,7 +160,7 @@ thread, it doesnt affect collecting.
To troubleshoot issues with the `vsphere` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/weblog.md b/docs/agent/collectors/go.d.plugin/modules/weblog.md
index 4ae794f17..843fd5d69 100644
--- a/docs/agent/collectors/go.d.plugin/modules/weblog.md
+++ b/docs/agent/collectors/go.d.plugin/modules/weblog.md
@@ -159,7 +159,7 @@ Notes:
is Off. The web log collector counts hostnames as IPv4 addresses. We recommend either to disable HostnameLookups or
use `%a` instead of `%h`.
- Since httpd 2.0, unlike 1.3, the `%b` and `%B` format strings do not represent the number of bytes sent to the client,
- but simply the size in bytes of the HTTP response. It will will differ, for instance, if the connection is aborted, or
+ but simply the size in bytes of the HTTP response. It will differ, for instance, if the connection is aborted, or
if SSL is used. The `%O` format provided by [`mod_logio`](https://httpd.apache.org/docs/2.4/mod/mod_logio.html)
will log the actual number of bytes sent over the network.
- To get `%I` and `%O` working you need to enable `mod_logio` on Apache.
@@ -198,7 +198,7 @@ Special case:
Both `%t` and `$time_local` fields represent time
in [Common Log Format](https://www.w3.org/Daemon/User/Config/Logging.html#common-logfile-format). It is a special case
-because it's in fact 2 fields after csv parse (ex.: `[22/Mar/2009:09:30:31 +0100]`). Weblog understands it and you don't
+because it's in fact 2 fields after csv parse (ex.: `[22/Mar/2009:09:30:31 +0100]`). Weblog understands it, and you don't
need to replace it with `-` (if we want to do it we need to make it `- -`).
```yaml
@@ -328,7 +328,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `web_log` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/whoisquery.md b/docs/agent/collectors/go.d.plugin/modules/whoisquery.md
index 7863513e8..3606f78de 100644
--- a/docs/agent/collectors/go.d.plugin/modules/whoisquery.md
+++ b/docs/agent/collectors/go.d.plugin/modules/whoisquery.md
@@ -53,7 +53,7 @@ module's [configuration file](https://github.com/netdata/go.d.plugin/blob/master
To troubleshoot issues with the `whoisquery` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/wireguard.md b/docs/agent/collectors/go.d.plugin/modules/wireguard.md
new file mode 100644
index 000000000..e8edb3d6d
--- /dev/null
+++ b/docs/agent/collectors/go.d.plugin/modules/wireguard.md
@@ -0,0 +1,56 @@
+---
+title: "WireGuard monitoring with Netdata"
+description: "Monitor WireGuard VPN network interfaces and peers traffic."
+custom_edit_url: https://github.com/netdata/go.d.plugin/edit/master/modules/wireguard/README.md
+sidebar_label: "WireGuard"
+---
+
+
+
+[WireGuard](https://www.wireguard.com/) is an extremely simple yet fast and modern VPN that utilizes state-of-the-art
+cryptography.
+
+This module monitors WireGuard VPN network interfaces and peers traffic.
+
+## Requirements
+
+- Grant `CAP_NET_ADMIN` capability to `go.d.plugin`.
+
+ ```bash
+ sudo setcap CAP_NET_ADMIN+epi /usr/libexec/netdata/plugins.d/go.d.plugin
+ ```
+
+## Metrics
+
+All metrics have "wireguard." prefix.
+
+| Metric | Scope | Dimensions | Units |
+|---------------------------|:------:|:-----------------:|:-------:|
+| device_peers | device | peers | peers |
+| device_network_io | device | receive, transmit | B/s |
+| peer_network_io | peer | receive, transmit | B/s |
+| peer_latest_handshake_ago | peer | time | seconds |
+
+## Configuration
+
+No configuration needed.
+
+## Troubleshooting
+
+To troubleshoot issues with the `wireguard` collector, run the `go.d.plugin` with the debug option enabled. The output
+should give you clues as to why the collector isn't working.
+
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
+to the `netdata` user.
+
+```bash
+cd /usr/libexec/netdata/plugins.d/
+sudo -u netdata -s
+```
+
+You can now run the `go.d.plugin` to debug the collector:
+
+```bash
+./go.d.plugin -d -m wireguard
+```
diff --git a/docs/agent/collectors/go.d.plugin/modules/wmi.md b/docs/agent/collectors/go.d.plugin/modules/wmi.md
index 5dac58849..bfc1384e8 100644
--- a/docs/agent/collectors/go.d.plugin/modules/wmi.md
+++ b/docs/agent/collectors/go.d.plugin/modules/wmi.md
@@ -116,7 +116,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `wmi` collector, run the `go.d.plugin` with the debug option enabled. The output should
give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/x509check.md b/docs/agent/collectors/go.d.plugin/modules/x509check.md
index 7f1346db4..d47eb40aa 100644
--- a/docs/agent/collectors/go.d.plugin/modules/x509check.md
+++ b/docs/agent/collectors/go.d.plugin/modules/x509check.md
@@ -66,7 +66,7 @@ jobs:
To troubleshoot issues with the `x509check` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/go.d.plugin/modules/zookeeper.md b/docs/agent/collectors/go.d.plugin/modules/zookeeper.md
index b474c057f..d8103c6c6 100644
--- a/docs/agent/collectors/go.d.plugin/modules/zookeeper.md
+++ b/docs/agent/collectors/go.d.plugin/modules/zookeeper.md
@@ -60,7 +60,7 @@ module [configuration file](https://github.com/netdata/go.d.plugin/blob/master/c
To troubleshoot issues with the `zookeeper` collector, run the `go.d.plugin` with the debug option enabled. The output
should give you clues as to why the collector isn't working.
-First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+First, navigate to your plugins' directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
to the `netdata` user.
diff --git a/docs/agent/collectors/plugins.d.md b/docs/agent/collectors/plugins.d.md
index 10d2e0d6e..8561722ef 100644
--- a/docs/agent/collectors/plugins.d.md
+++ b/docs/agent/collectors/plugins.d.md
@@ -116,15 +116,17 @@ For example, if your plugin wants to monitor `squid`, you can search for it on p
Any program that can print a few values to its standard output can become a Netdata external plugin.
-Netdata parses 7 lines starting with:
-
-- `CHART` - create or update a chart
-- `DIMENSION` - add or update a dimension to the chart just created
-- `BEGIN` - initialize data collection for a chart
-- `SET` - set the value of a dimension for the initialized chart
-- `END` - complete data collection for the initialized chart
-- `FLUSH` - ignore the last collected values
-- `DISABLE` - disable this plugin
+Netdata parses 9 lines starting with:
+
+- `CHART` - create or update a chart
+- `DIMENSION` - add or update a dimension to the chart just created
+- `BEGIN` - initialize data collection for a chart
+- `SET` - set the value of a dimension for the initialized chart
+- `END` - complete data collection for the initialized chart
+- `FLUSH` - ignore the last collected values
+- `DISABLE` - disable this plugin
+- `CLABEL` - add a label to a chart
+- `CLABEL_COMMIT` - commit added labels to the chart.
a single program can produce any number of charts with any number of dimensions each.
@@ -320,6 +322,46 @@ The `value` is floating point (Netdata used `long double`).
Variables are transferred to upstream Netdata servers (streaming and database replication).
+#### CLABEL
+
+> CLABEL name value source
+
+`CLABEL` defines a label used to organize and identify a chart.
+
+Name and value accept characters according to the following table:
+
+| Character | Symbol | Label Name | Label Value |
+|---------------------|:------:|:----------:|:-----------:|
+| UTF-8 character | UTF-8 | _ | keep |
+| Lower case letter | [a-z] | keep | keep |
+| Upper case letter | [A-Z] | keep | [a-z] |
+| Digit | [0-9] | keep | keep |
+| Underscore | _ | keep | keep |
+| Minus | - | keep | keep |
+| Plus | + | _ | keep |
+| Colon | : | _ | keep |
+| Semicolon | ; | _ | : |
+| Equal | = | _ | : |
+| Period | . | keep | keep |
+| Comma | , | . | . |
+| Slash | / | keep | keep |
+| Backslash | \ | / | / |
+| At | @ | _ | keep |
+| Space | ' ' | _ | keep |
+| Opening parenthesis | ( | _ | keep |
+| Closing parenthesis | ) | _ | keep |
+| Anything else | | _ | _ |
+
+The `source` is an integer field that can have the following values:
+- `1`: The value was set automatically.
+- `2`: The value was set manually.
+- `4`: This is a K8 label.
+- `8`: This is a label defined using `netdata` agent cloud link.
+
+#### CLABEL_COMMIT
+
+`CLABEL_COMMIT` indicates that all labels were defined and the chart can be updated.
+
## Data collection
data collection is defined as a series of `BEGIN` -> `SET` -> `END` lines
diff --git a/docs/agent/collectors/python.d.plugin/chrony.md b/docs/agent/collectors/python.d.plugin/chrony.md
deleted file mode 100644
index db26f483c..000000000
--- a/docs/agent/collectors/python.d.plugin/chrony.md
+++ /dev/null
@@ -1,61 +0,0 @@
----
-title: "Chrony monitoring with Netdata"
-custom_edit_url: https://github.com/netdata/netdata/edit/master/collectors/python.d.plugin/chrony/README.md
-sidebar_label: "Chrony"
----
-
-
-
-Monitors the precision and statistics of a local chronyd server, and produces:
-
-- frequency
-- last offset
-- RMS offset
-- residual freq
-- root delay
-- root dispersion
-- skew
-- system time
-
-## Requirements
-
-Verify that user Netdata can execute `chronyc tracking`. If necessary, update `/etc/chrony.conf`, `cmdallow`.
-
-## Enable the collector
-
-The `chrony` collector is disabled by default. To enable it, use `edit-config` from the Netdata [config
-directory](/docs/configure/nodes), which is typically at `/etc/netdata`, to edit the `python.d.conf` file.
-
-```bash
-cd /etc/netdata # Replace this path with your Netdata config directory, if different
-sudo ./edit-config python.d.conf
-```
-
-Change the value of the `chrony` setting to `yes`. Save the file and restart the Netdata Agent with `sudo systemctl
-restart netdata`, or the appropriate method for your system, to finish enabling the `chrony` collector.
-
-## Configuration
-
-Edit the `python.d/chrony.conf` configuration file using `edit-config` from the Netdata [config
-directory](/docs/configure/nodes), which is typically at `/etc/netdata`.
-
-```bash
-cd /etc/netdata # Replace this path with your Netdata config directory, if different
-sudo ./edit-config python.d/chrony.conf
-```
-
-Sample:
-
-```yaml
-# data collection frequency:
-update_every: 1
-
-# chrony query command:
-local:
- command: 'chronyc -n tracking'
-```
-
-Save the file and restart the Netdata Agent with `sudo systemctl restart netdata`, or the [appropriate
-method](/docs/configure/start-stop-restart) for your system, to finish configuring the `chrony` collector.
-
-
diff --git a/docs/agent/collectors/python.d.plugin/haproxy.md b/docs/agent/collectors/python.d.plugin/haproxy.md
index 31f631f46..95213f6cd 100644
--- a/docs/agent/collectors/python.d.plugin/haproxy.md
+++ b/docs/agent/collectors/python.d.plugin/haproxy.md
@@ -9,30 +9,32 @@ sidebar_label: "HAProxy"
Monitors frontend and backend metrics such as bytes in, bytes out, sessions current, sessions in queue current.
And health metrics such as backend servers status (server check should be used).
-Plugin can obtain data from url **OR** unix socket.
+Plugin can obtain data from URL or Unix socket.
-**Requirement:**
-Socket MUST be readable AND writable by the `netdata` user.
+Requirement:
+
+- Socket must be readable and writable by the `netdata` user.
+- URL must have `stats uri ` present in the haproxy config, otherwise you will get HTTP 503 in the haproxy logs.
It produces:
-1. **Frontend** family charts
+1. **Frontend** family charts
- - Kilobytes in/s
- - Kilobytes out/s
- - Sessions current
- - Sessions in queue current
+ - Kilobytes in/s
+ - Kilobytes out/s
+ - Sessions current
+ - Sessions in queue current
-2. **Backend** family charts
+2. **Backend** family charts
- - Kilobytes in/s
- - Kilobytes out/s
- - Sessions current
- - Sessions in queue current
+ - Kilobytes in/s
+ - Kilobytes out/s
+ - Sessions current
+ - Sessions in queue current
-3. **Health** chart
+3. **Health** chart
- - number of failed servers for every backend (in DOWN state)
+ - number of failed servers for every backend (in DOWN state)
## Configuration
@@ -48,20 +50,18 @@ Sample:
```yaml
via_url:
- user : 'username' # ONLY IF stats auth is used
- pass : 'password' # # ONLY IF stats auth is used
- url : 'http://ip.address:port/url;csv;norefresh'
+ user: 'username' # ONLY IF stats auth is used
+ pass: 'password' # # ONLY IF stats auth is used
+ url: 'http://ip.address:port/url;csv;norefresh'
```
OR
```yaml
via_socket:
- socket : 'path/to/haproxy/sock'
+ socket: 'path/to/haproxy/sock'
```
If no configuration is given, module will fail to run.
---
-
-
diff --git a/docs/agent/collectors/python.d.plugin/ovpn_status_log.md b/docs/agent/collectors/python.d.plugin/ovpn_status_log.md
deleted file mode 100644
index 5abdf7008..000000000
--- a/docs/agent/collectors/python.d.plugin/ovpn_status_log.md
+++ /dev/null
@@ -1,50 +0,0 @@
----
-title: "OpenVPN monitoring with Netdata"
-custom_edit_url: https://github.com/netdata/netdata/edit/master/collectors/python.d.plugin/ovpn_status_log/README.md
-sidebar_label: "OpenVPN"
----
-
-
-
-Parses server log files and provides summary (client, traffic) metrics.
-
-## Requirements
-
-- If you are running multiple OpenVPN instances out of the same directory, MAKE SURE TO EDIT DIRECTIVES which create output files
- so that multiple instances do not overwrite each other's output files.
-
-- Make sure NETDATA USER CAN READ openvpn-status.log
-
-- Update_every interval MUST MATCH interval on which OpenVPN writes operational status to log file.
-
-It produces:
-
-1. **Users** OpenVPN active users
-
- - users
-
-2. **Traffic** OpenVPN overall bandwidth usage in kilobit/s
-
- - in
- - out
-
-## Configuration
-
-Edit the `python.d/ovpn_status_log.conf` configuration file using `edit-config` from the Netdata [config
-directory](/docs/configure/nodes), which is typically at `/etc/netdata`.
-
-```bash
-cd /etc/netdata # Replace this path with your Netdata config directory, if different
-sudo ./edit-config python.d/ovpn_status_log.conf
-```
-
-Sample:
-
-```yaml
-default
- log_path : '/var/log/openvpn-status.log'
-```
-
----
-
-
diff --git a/docs/agent/collectors/python.d.plugin/postgres.md b/docs/agent/collectors/python.d.plugin/postgres.md
index 8f47492b1..d521c8a32 100644
--- a/docs/agent/collectors/python.d.plugin/postgres.md
+++ b/docs/agent/collectors/python.d.plugin/postgres.md
@@ -97,7 +97,8 @@ cd /etc/netdata # Replace this path with your Netdata config directory, if dif
sudo ./edit-config python.d/postgres.conf
```
-When no configuration file is found, the module tries to connect to TCP/IP socket: `localhost:5432`.
+When no configuration file is found, the module tries to connect to TCP/IP socket: `localhost:5432` with the
+following collection jobs.
```yaml
socket:
@@ -113,6 +114,29 @@ tcp:
port : 5432
```
+**Note**: Every job collection must have a unique identifier. In cases that you monitor multiple DBs, every
+job must have it's own name. Use a mnemonic of your preference (e.g us_east_db, us_east_tcp)
+
+## Troubleshooting
+
+To troubleshoot issues with the `postgres` collector, run the `python.d.plugin` with the debug option enabled. The output
+should give you clues as to why the collector isn't working.
+
+First, navigate to your plugins directory, usually at `/usr/libexec/netdata/plugins.d/`. If that's not the case on your
+system, open `netdata.conf` and look for the setting `plugins directory`. Once you're in the plugin's directory, switch
+to the `netdata` user.
+
+```bash
+cd /usr/libexec/netdata/plugins.d/
+sudo su -s /bin/bash netdata
+```
+
+You can now run the `python.d.plugin` to debug the collector:
+
+```bash
+./python.d.plugin postgres debug trace
+```
+
---
diff --git a/docs/agent/collectors/python.d.plugin/zscores.md b/docs/agent/collectors/python.d.plugin/zscores.md
index ce5470cdf..b71e14995 100644
--- a/docs/agent/collectors/python.d.plugin/zscores.md
+++ b/docs/agent/collectors/python.d.plugin/zscores.md
@@ -141,4 +141,4 @@ per_chart_agg: 'mean' # 'absmax' will take the max absolute value across all dim
- About ~50mb of ram (`apps.mem`) being continually used by the `python.d.plugin`.
- If you activate this collector on a fresh node, it might take a little while to build up enough data to calculate a
proper zscore. So until you actually have `train_secs` of available data the mean and stddev calculated will be subject
- to more noise.
\ No newline at end of file
+ to more noise.
diff --git a/docs/agent/daemon/config.md b/docs/agent/daemon/config.md
index d2db692e3..6b55cbe97 100644
--- a/docs/agent/daemon/config.md
+++ b/docs/agent/daemon/config.md
@@ -82,21 +82,33 @@ Please note that your data history will be lost if you have modified `history` p
### [db] section options
-| setting | default | info |
-|:----------------------------------:|:----------:|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
-| mode | `dbengine` | `dbengine`: The default for long-term metrics storage with efficient RAM and disk usage. Can be extended with `page cache size MB` and `dbengine disk space MB`.
`save`: Netdata will save its round robin database on exit and load it on startup.
`map`: Cache files will be updated in real-time. Not ideal for systems with high load or slow disks (check `man mmap`).
`ram`: The round-robin database will be temporary and it will be lost when Netdata exits.
`none`: Disables the database at this host, and disables health monitoring entirely, as that requires a database of metrics. |
-| retention | `3600` | Used with `mode = save/map/ram/alloc`, not the default `mode = dbengine`. This number reflects the number of entries the `netdata` daemon will by default keep in memory for each chart dimension. Check [Memory Requirements](/docs/agent/database) for more information. |
-| update every | `1` | The frequency in seconds, for data collection. For more information see the [performance guide](/guides/configure/performance). |
-| page cache size MB | 32 | Determines the amount of RAM in MiB that is dedicated to caching Netdata metric values. |
-| dbengine disk space MB | 256 | Determines the amount of disk space in MiB that is dedicated to storing Netdata metric values and all related metadata describing them. |
-| dbengine multihost disk space MB | 256 | Same functionality as `dbengine disk space MB`, but includes support for storing metrics streamed to a parent node by its children. Can be used in single-node environments as well. |
-| memory deduplication (ksm) | `yes` | When set to `yes`, Netdata will offer its in-memory round robin database and the dbengine page cache to kernel same page merging (KSM) for deduplication. For more information check [Memory Deduplication - Kernel Same Page Merging - KSM](/docs/agent/database#ksm) |
-| cleanup obsolete charts after secs | `3600` | See [monitoring ephemeral containers](/docs/agent/collectors/cgroups.plugin#monitoring-ephemeral-containers), also sets the timeout for cleaning up obsolete dimensions |
-| gap when lost iterations above | `1` | |
-| cleanup orphan hosts after secs | `3600` | How long to wait until automatically removing from the DB a remote Netdata host (child) that is no longer sending data. |
-| delete obsolete charts files | `yes` | See [monitoring ephemeral containers](/docs/agent/collectors/cgroups.plugin#monitoring-ephemeral-containers), also affects the deletion of files for obsolete dimensions |
-| delete orphan hosts files | `yes` | Set to `no` to disable non-responsive host removal. |
-| enable zero metrics | `no` | Set to `yes` to show charts when all their metrics are zero. |
+| setting | default | info |
+|:---------------------------------------------:|:----------:|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
+| mode | `dbengine` | `dbengine`: The default for long-term metrics storage with efficient RAM and disk usage. Can be extended with `dbengine page cache size MB` and `dbengine disk space MB`.
`save`: Netdata will save its round robin database on exit and load it on startup.
`map`: Cache files will be updated in real-time. Not ideal for systems with high load or slow disks (check `man mmap`).
`ram`: The round-robin database will be temporary and it will be lost when Netdata exits.
`none`: Disables the database at this host, and disables health monitoring entirely, as that requires a database of metrics. |
+| retention | `3600` | Used with `mode = save/map/ram/alloc`, not the default `mode = dbengine`. This number reflects the number of entries the `netdata` daemon will by default keep in memory for each chart dimension. Check [Memory Requirements](/docs/agent/database) for more information. |
+| storage tiers | `1` | The number of storage tiers you want to have in your dbengine. Check the tiering mechanism in the [dbengine's reference](/docs/agent/database/engine#tiering). You can have up to 5 tiers of data (including the _Tier 0_). This number ranges between 1 and 5. |
+| dbengine page cache size MB | `32` | Determines the amount of RAM in MiB that is dedicated to caching for _Tier 0_ Netdata metric values. |
+| dbengine tier **`N`** page cache size MB | `32` | Determines the amount of RAM in MiB that is dedicated for caching Netdata metric values of the **`N`** tier.
`N belongs to [1..4]` ||
+ | dbengine disk space MB | `256` | Determines the amount of disk space in MiB that is dedicated to storing _Tier 0_ Netdata metric values and all related metadata describing them. This option is available **only for legacy configuration** (`Agent v1.23.2 and prior`). |
+| dbengine multihost disk space MB | `256` | Same functionality as `dbengine disk space MB`, but includes support for storing metrics streamed to a parent node by its children. Can be used in single-node environments as well. This setting is only for _Tier 0_ metrics. |
+| dbengine tier **`N`** multihost disk space MB | `256` | Same functionality as `dbengine multihost disk space MB`, but stores metrics of the **`N`** tier (both parent node and its children). Can be used in single-node environments as well.
`N belongs to [1..4]` |
+| update every | `1` | The frequency in seconds, for data collection. For more information see the [performance guide](/guides/configure/performance). These metrics stored as _Tier 0_ data. Explore the tiering mechanism in the [dbengine's reference](/docs/agent/database/engine#tiering). |
+| dbengine tier **`N`** update every iterations | `60` | The down sampling value of each tier from the previous one. For each Tier, the greater by one Tier has N (equal to 60 by default) less data points of any metric it collects. This setting can take values from `2` up to `255`.
`N belongs to [1..4]` |
+| dbengine tier **`N`** back fill | `New` | Specifies the strategy of recreating missing data on each Tier from the exact lower Tier.
`New`: Sees the latest point on each Tier and save new points to it only if the exact lower Tier has available points for it's observation window (`dbengine tier N update every iterations` window).
`none`: No back filling is applied.
`N belongs to [1..4]` |
+| memory deduplication (ksm) | `yes` | When set to `yes`, Netdata will offer its in-memory round robin database and the dbengine page cache to kernel same page merging (KSM) for deduplication. For more information check [Memory Deduplication - Kernel Same Page Merging - KSM](/docs/agent/database#ksm) |
+| cleanup obsolete charts after secs | `3600` | See [monitoring ephemeral containers](/docs/agent/collectors/cgroups.plugin#monitoring-ephemeral-containers), also sets the timeout for cleaning up obsolete dimensions |
+| gap when lost iterations above | `1` | |
+| cleanup orphan hosts after secs | `3600` | How long to wait until automatically removing from the DB a remote Netdata host (child) that is no longer sending data. |
+| delete obsolete charts files | `yes` | See [monitoring ephemeral containers](/docs/agent/collectors/cgroups.plugin#monitoring-ephemeral-containers), also affects the deletion of files for obsolete dimensions |
+| delete orphan hosts files | `yes` | Set to `no` to disable non-responsive host removal. |
+| enable zero metrics | `no` | Set to `yes` to show charts when all their metrics are zero. |
+
+:::info
+
+The multiplication of all the **enabled** tiers `dbengine tier N update every iterations` values must be less than `65535`.
+
+:::
+
### [directories] section options
diff --git a/docs/agent/database.md b/docs/agent/database.md
index 3a98ce168..e99f95bc6 100644
--- a/docs/agent/database.md
+++ b/docs/agent/database.md
@@ -7,199 +7,138 @@ custom_edit_url: https://github.com/netdata/netdata/edit/master/database/README.
Netdata is fully capable of long-term metrics storage, at per-second granularity, via its default database engine
-(`dbengine`). But to remain as flexible as possible, Netdata supports a number of types of metrics storage:
+(`dbengine`). But to remain as flexible as possible, Netdata supports several storage options:
1. `dbengine`, (the default) data are in database files. The [Database Engine](/docs/agent/database/engine) works like a
- traditional database. There is some amount of RAM dedicated to data caching and indexing and the rest of the data
- reside compressed on disk. The number of history entries is not fixed in this case, but depends on the configured
- disk space and the effective compression ratio of the data stored. This is the **only mode** that supports changing
- the data collection update frequency (`update every`) **without losing** the previously stored metrics. For more
- details see [here](/docs/agent/database/engine).
+ traditional database. There is some amount of RAM dedicated to data caching and indexing and the rest of the data
+ reside compressed on disk. The number of history entries is not fixed in this case, but depends on the configured
+ disk space and the effective compression ratio of the data stored. This is the **only mode** that supports changing
+ the data collection update frequency (`update every`) **without losing** the previously stored metrics. For more
+ details see [here](/docs/agent/database/engine).
-2. `ram`, data are purely in memory. Data are never saved on disk. This mode uses `mmap()` and supports [KSM](#ksm).
+2. `ram`, data are purely in memory. Data are never saved on disk. This mode uses `mmap()` and supports [KSM](#ksm).
-3. `save`, data are only in RAM while Netdata runs and are saved to / loaded from disk on Netdata
- restart. It also uses `mmap()` and supports [KSM](#ksm).
+3. `save`, data are only in RAM while Netdata runs and are saved to / loaded from disk on Netdata restart. It also
+ uses `mmap()` and supports [KSM](#ksm).
-4. `map`, data are in memory mapped files. This works like the swap. Keep in mind though, this will have a constant
- write on your disk. When Netdata writes data on its memory, the Linux kernel marks the related memory pages as dirty
- and automatically starts updating them on disk. Unfortunately we cannot control how frequently this works. The Linux
- kernel uses exactly the same algorithm it uses for its swap memory. Check below for additional information on
- running a dedicated central Netdata server. This mode uses `mmap()` but does not support [KSM](#ksm).
+4. `map`, data are in memory mapped files. This works like the swap. When Netdata writes data on its memory, the Linux
+ kernel marks the related memory pages as dirty and automatically starts updating them on disk. Unfortunately we
+ cannot control how frequently this works. The Linux kernel uses exactly the same algorithm it uses for its swap
+ memory. This mode uses `mmap()` but does not support [KSM](#ksm). _Keep in mind though, this option will have a
+ constant write on your disk._
-5. `none`, without a database (collected metrics can only be streamed to another Netdata).
+5. `alloc`, like `ram` but it uses `calloc()` and does not support [KSM](#ksm). This mode is the fallback for all others
+ except `none`.
-6. `alloc`, like `ram` but it uses `calloc()` and does not support [KSM](#ksm). This mode is the fallback for all
- others except `none`.
+6. `none`, without a database (collected metrics can only be streamed to another Netdata).
-You can select the database mode by editing `netdata.conf` and setting:
-
-```conf
-[db]
- # dbengine (default), ram, save (the default if dbengine not available), map (swap like), none, alloc
- mode = dbengine
-```
-
-## Running Netdata in embedded devices
-
-Embedded devices usually have very limited RAM resources available.
-
-There are 2 settings for you to tweak:
-
-1. `[db].update every`, which controls the data collection frequency
-2. `[db].retention`, which controls the size of the database in memory (except for `[db].mode = dbengine`)
-
-By default `[db].update every = 1` and `[db].retention = 3600`. This gives you an hour of data with per second updates.
-
-If you set `[db].update every = 2` and `[db].retention = 1800`, you will still have an hour of data, but collected once every 2
-seconds. This will **cut in half** both CPU and RAM resources consumed by Netdata. Of course experiment a bit. On very
-weak devices you might have to use `[db].update every = 5` and `[db].retention = 720` (still 1 hour of data, but 1/5 of the CPU and
-RAM resources).
-
-You can also disable [data collection plugins](/docs/agent/collectors) you don't need. Disabling such plugins will also free both
-CPU and RAM resources.
-
-## Running a dedicated parent Netdata server
-
-Netdata allows streaming data between Netdata nodes in real-time. This allows having one or more parent Netdata servers that will maintain
-the entire database for all the nodes that connect to them (their children), and will also run health checks/alarms for all these nodes.
-
-### map
+## Which database mode to use
-In this mode, the database of Netdata is stored in memory mapped files. Netdata continues to read and write the database
-in memory, but the kernel automatically loads and saves memory pages from/to disk.
+The default mode `[db].mode = dbengine` has been designed to scale for longer retentions and is the only mode suitable
+for parent Agents in the _Parent - Child_ setups
-**We suggest _not_ to use this mode on nodes that run other applications.** There will always be dirty memory to be
-synced and this syncing process may influence the way other applications work. This mode however is useful when we need
-a parent Netdata server that would normally need huge amounts of memory.
+The other available database modes are designed to minimize resource utilization and should only be considered on
+[Parent - Child](/docs/metrics-storage-management/how-streaming-works) setups at the children side and only when the
+resource constraints are very strict.
-There are a few kernel options that provide finer control on the way this syncing works. But before explaining them, a
-brief introduction of how Netdata database works is needed.
+So,
-For each chart, Netdata maps the following files:
+- On a single node setup, use `[db].mode = dbengine`.
+- On a [Parent - Child](/docs/metrics-storage-management/how-streaming-works) setup, use `[db].mode = dbengine` on the
+ parent to increase retention, a more resource efficient mode like, `dbengine` with light retention settings, and
+ `save`, `ram` or `none` modes for the children to minimize resource utilization.
-1. `chart/main.db`, this is the file that maintains chart information. Every time data are collected for a chart, this
- is updated.
-2. `chart/dimension_name.db`, this is the file for each dimension. At its beginning there is a header, followed by the
- round robin database where metrics are stored.
+## Choose your database mode
-So, every time Netdata collects data, the following pages will become dirty:
-
-1. the chart file
-2. the header part of all dimension files
-3. if the collected metrics are stored far enough in the dimension file, another page will become dirty, for each
- dimension
-
-Each page in Linux is 4KB. So, with 200 charts and 1000 dimensions, there will be 1200 to 2200 4KB pages dirty pages
-every second. Of course 1200 of them will always be dirty (the chart header and the dimensions headers) and 1000 will be
-dirty for about 1000 seconds (4 bytes per metric, 4KB per page, so 1000 seconds, or 16 minutes per page).
-
-Hopefully, the Linux kernel does not sync all these data every second. The frequency they are synced is controlled by
-`/proc/sys/vm/dirty_expire_centisecs` or the `sysctl` `vm.dirty_expire_centisecs`. The default on most systems is 3000
-(30 seconds).
-
-On a busy server centralizing metrics from 20+ servers you will experience this:
-
-
-
-As you can see, there is quite some stress (this is `iowait`) every 30 seconds.
-
-A simple solution is to increase this time to 10 minutes (60000). This is the same system with this setting in 10
-minutes:
-
-
-
-Of course, setting this to 10 minutes means that data on disk might be up to 10 minutes old if you get an abnormal
-shutdown.
+You can select the database mode by editing `netdata.conf` and setting:
-There are 2 more options to tweak:
+```conf
+[db]
+ # dbengine (default), ram, save (the default if dbengine not available), map (swap like), none, alloc
+ mode = dbengine
+```
-1. `dirty_background_ratio`, by default `10`.
-2. `dirty_ratio`, by default `20`.
+## Netdata Longer Metrics Retention
-These control the amount of memory that should be dirty for disk syncing to be triggered. On dedicated Netdata servers,
-you can use: `80` and `90` respectively, so that all RAM is given to Netdata.
+Metrics retention is controlled only by the disk space allocated to storing metrics. But it also affects the memory and
+CPU required by the agent to query longer timeframes.
-With these settings, you can expect a little `iowait` spike once every 10 minutes and in case of system crash, data on
-disk will be up to 10 minutes old.
+Since Netdata Agents usually run on the edge, on production systems, Netdata Agent **parents** should be considered.
+When having a [**parent - child**](/docs/metrics-storage-management/how-streaming-works) setup, the child (the
+Netdata Agent running on a production system) delegates all of its functions, including longer metrics retention and
+querying, to the parent node that can dedicate more resources to this task. A single Netdata Agent parent can centralize
+multiple children Netdata Agents (dozens, hundreds, or even thousands depending on its available resources).
-
+## Running Netdata on embedded devices
-To have these settings automatically applied on boot, create the file `/etc/sysctl.d/netdata-memory.conf` with these
-contents:
+Embedded devices typically have very limited RAM resources available.
-```conf
-vm.dirty_expire_centisecs = 60000
-vm.dirty_background_ratio = 80
-vm.dirty_ratio = 90
-vm.dirty_writeback_centisecs = 0
-```
+There are two settings for you to configure:
-There is another mode to help overcome the memory size problem. What is **most interesting for this setup** is
-`[db].mode = dbengine`.
+1. `[db].update every`, which controls the data collection frequency
+2. `[db].retention`, which controls the size of the database in memory (except for `[db].mode = dbengine`)
-### dbengine
+By default `[db].update every = 1` and `[db].retention = 3600`. This gives you an hour of data with per second updates.
-In this mode, the database of Netdata is stored in database files. The [Database Engine](/docs/agent/database/engine)
-works like a traditional database. There is some amount of RAM dedicated to data caching and indexing and the rest of
-the data reside compressed on disk. The number of history entries is not fixed in this case, but depends on the
-configured disk space and the effective compression ratio of the data stored.
+If you set `[db].update every = 2` and `[db].retention = 1800`, you will still have an hour of data, but collected once
+every 2 seconds. This will **cut in half** both CPU and RAM resources consumed by Netdata. Of course experiment a bit to find the right setting.
+On very weak devices you might have to use `[db].update every = 5` and `[db].retention = 720` (still 1 hour of data, but
+1/5 of the CPU and RAM resources).
-We suggest to use **this** mode on nodes that also run other applications. The Database Engine uses direct I/O to avoid
-polluting the OS filesystem caches and does not generate excessive I/O traffic so as to create the minimum possible
-interference with other applications. Using mode `dbengine` we can overcome most memory restrictions. For more
-details see [here](/docs/agent/database/engine).
+You can also disable [data collection plugins](/docs/agent/collectors) that you don't need. Disabling such plugins will also
+free both CPU and RAM resources.
-## KSM
+## Memory optimizations
-Netdata offers all its in-memory database to kernel for deduplication.
+### KSM
-In the past KSM has been criticized for consuming a lot of CPU resources. Although this is true when KSM is used for
-deduplicating certain applications, it is not true with netdata, since the Netdata memory is written very infrequently
-(if you have 24 hours of metrics in netdata, each byte at the in-memory database will be updated just once per day).
+KSM performs memory deduplication by scanning through main memory for physical pages that have identical content, and
+identifies the virtual pages that are mapped to those physical pages. It leaves one page unchanged, and re-maps each
+duplicate page to point to the same physical page. Netdata offers all of its in-memory database to kernel for
+deduplication.
-KSM is a solution that will provide 60+% memory savings to Netdata.
+In the past, KSM has been criticized for consuming a lot of CPU resources. This is true when KSM is used for
+deduplicating certain applications, but it is not true for Netdata. Agent's memory is written very infrequently
+(if you have 24 hours of metrics in Netdata, each byte at the in-memory database will be updated just once per day). KSM
+is a solution that will provide 60+% memory savings to Netdata.
### Enable KSM in kernel
-You need to run a kernel compiled with:
+To enable KSM in kernel, you need to run a kernel compiled with the following:
```sh
CONFIG_KSM=y
```
-When KSM is enabled at the kernel is just available for the user to enable it.
+When KSM is enabled at the kernel, it is just available for the user to enable it.
-So, if you build a kernel with `CONFIG_KSM=y` you will just get a few files in `/sys/kernel/mm/ksm`. Nothing else
-happens. There is no performance penalty (apart I guess from the memory this code occupies into the kernel).
+If you build a kernel with `CONFIG_KSM=y`, you will just get a few files in `/sys/kernel/mm/ksm`. Nothing else
+happens. There is no performance penalty (apart from the memory this code occupies into the kernel).
The files that `CONFIG_KSM=y` offers include:
-- `/sys/kernel/mm/ksm/run` by default `0`. You have to set this to `1` for the
- kernel to spawn `ksmd`.
-- `/sys/kernel/mm/ksm/sleep_millisecs`, by default `20`. The frequency ksmd
- should evaluate memory for deduplication.
-- `/sys/kernel/mm/ksm/pages_to_scan`, by default `100`. The amount of pages
- ksmd will evaluate on each run.
+- `/sys/kernel/mm/ksm/run` by default `0`. You have to set this to `1` for the kernel to spawn `ksmd`.
+- `/sys/kernel/mm/ksm/sleep_millisecs`, by default `20`. The frequency ksmd should evaluate memory for deduplication.
+- `/sys/kernel/mm/ksm/pages_to_scan`, by default `100`. The amount of pages ksmd will evaluate on each run.
So, by default `ksmd` is just disabled. It will not harm performance and the user/admin can control the CPU resources
-he/she is willing `ksmd` to use.
+they are willing to have used by `ksmd`.
### Run `ksmd` kernel daemon
-To activate / run `ksmd` you need to run:
+To activate / run `ksmd,` you need to run the following:
```sh
echo 1 >/sys/kernel/mm/ksm/run
echo 1000 >/sys/kernel/mm/ksm/sleep_millisecs
```
-With these settings ksmd does not even appear in the running process list (it will run once per second and evaluate 100
+With these settings, ksmd does not even appear in the running process list (it will run once per second and evaluate 100
pages for de-duplication).
Put the above lines in your boot sequence (`/etc/rc.local` or equivalent) to have `ksmd` run at boot.
-## Monitoring Kernel Memory de-duplication performance
+### Monitoring Kernel Memory de-duplication performance
Netdata will create charts for kernel memory de-duplication performance, like this:
diff --git a/docs/agent/database/engine.md b/docs/agent/database/engine.md
index 2901a99c3..593b4637b 100644
--- a/docs/agent/database/engine.md
+++ b/docs/agent/database/engine.md
@@ -6,74 +6,114 @@ custom_edit_url: https://github.com/netdata/netdata/edit/master/database/engine/
-The Database Engine works like a traditional database. It dedicates a certain amount of RAM to data caching and
-indexing, while the rest of the data resides compressed on disk. Unlike other [database modes](/docs/agent/database), the
-amount of historical metrics stored is based on the amount of disk space you allocate and the effective compression
+The Database Engine works like a traditional time series database. Unlike other [database modes](/docs/agent/database),
+the amount of historical metrics stored is based on the amount of disk space you allocate and the effective compression
ratio, not a fixed number of metrics collected.
-By using both RAM and disk space, the database engine allows for long-term storage of per-second metrics inside of the
-Agent itself.
+## Tiering
-In addition, the dbengine is the only mode that supports changing the data collection update frequency
-(`update every`) without losing the metrics your Agent already gathered and stored.
+Tiering is a mechanism of providing multiple tiers of data with
+different [granularity on metrics](/docs/store/distributed-data-architecture#granularity-of-metrics).
-## Configuration
+For Netdata Agents with version `netdata-1.35.0.138.nightly` and greater, `dbengine` supports Tiering, allowing almost
+unlimited retention of data.
-To use the database engine, open `netdata.conf` and set `[db].mode` to `dbengine`.
-```conf
+### Metric size
+
+Every Tier down samples the exact lower tier (lower tiers have greater resolution). You can have up to 5
+Tiers **[0. . 4]** of data (including the Tier 0, which has the highest resolution)
+
+Tier 0 is the default that was always available in `dbengine` mode. Tier 1 is the first level of aggregation, Tier 2 is
+the second, and so on.
+
+Metrics on all tiers except of the _Tier 0_ also store the following five additional values for every point for accurate
+representation:
+
+1. The `sum` of the points aggregated
+2. The `min` of the points aggregated
+3. The `max` of the points aggregated
+4. The `count` of the points aggregated (could be constant, but it may not be due to gaps in data collection)
+5. The `anomaly_count` of the points aggregated (how many of the aggregated points found anomalous)
+
+Among `min`, `max` and `sum`, the correct value is chosen based on the user query. `average` is calculated on the fly at
+query time.
+
+### Tiering in a nutshell
+
+The `dbengine` is capable of retaining metrics for years. To further understand the `dbengine` tiering mechanism let's
+explore the following configuration.
+
+```
[db]
mode = dbengine
+
+ # per second data collection
+ update every = 1
+
+ # enables Tier 1 and Tier 2, Tier 0 is always enabled in dbengine mode
+ storage tiers = 3
+
+ # Tier 0, per second data for a week
+ dbengine multihost disk space MB = 1100
+
+ # Tier 1, per minute data for a month
+ dbengine tier 1 multihost disk space MB = 330
+
+ # Tier 2, per hour data for a year
+ dbengine tier 2 multihost disk space MB = 67
```
-To configure the database engine, look for the `page cache size MB` and `dbengine multihost disk space MB` settings in the
-`[db]` section of your `netdata.conf`. The Agent ignores the `[db].retention` setting when using the dbengine.
+For 2000 metrics, collected every second and retained for a week, Tier 0 needs: 1 byte x 2000 metrics x 3600 secs per
+hour x 24 hours per day x 7 days per week = 1100MB.
-```conf
-[db]
- page cache size MB = 32
- dbengine multihost disk space MB = 256
-```
+By setting `dbengine multihost disk space MB` to `1100`, this node will start maintaining about a week of data. But pay
+attention to the number of metrics. If you have more than 2000 metrics on a node, or you need more that a week of high
+resolution metrics, you may need to adjust this setting accordingly.
+
+Tier 1 is by default sampling the data every **60 points of Tier 0**. In our case, Tier 0 is per second, if we want to
+transform this information in terms of time then the Tier 1 "resolution" is per minute.
+
+Tier 1 needs four times more storage per point compared to Tier 0. So, for 2000 metrics, with per minute resolution,
+retained for a month, Tier 1 needs: 4 bytes x 2000 metrics x 60 minutes per hour x 24 hours per day x 30 days per month
+= 330MB.
+
+Tier 2 is by default sampling data every 3600 points of Tier 0 (60 of Tier 1, which is the previous exact Tier). Again
+in term of "time" (Tier 0 is per second), then Tier 2 is per hour.
+
+The storage requirements are the same to Tier 1.
-The above values are the default values for Page Cache size and DB engine disk space quota.
+For 2000 metrics, with per hour resolution, retained for a year, Tier 2 needs: 4 bytes x 2000 metrics x 24 hours per day
+x 365 days per year = 67MB.
-The `page cache size MB` option determines the amount of RAM dedicated to caching Netdata metric values. The
-actual page cache size will be slightly larger than this figure—see the [memory requirements](#memory-requirements)
-section for details.
+## Legacy configuration
-The `dbengine multihost disk space MB` option determines the amount of disk space that is dedicated to storing
-Netdata metric values and all related metadata describing them. You can use the [**database engine
-calculator**](/docs/store/change-metrics-storage#calculate-the-system-resources-ram-disk-space-needed-to-store-metrics)
-to correctly set `dbengine multihost disk space MB` based on your metrics retention policy. The calculator gives an
-accurate estimate based on how many child nodes you have, how many metrics your Agent collects, and more.
+### v1.35.1 and prior
-### Legacy configuration
+These versions of the Agent do not support [Tiering](#tiering). You could change the metric retention for the parent and
+all of its children only with the `dbengine multihost disk space MB` setting. This setting accounts the space allocation
+for the parent node and all of its children.
-The deprecated `dbengine disk space MB` option determines the amount of disk space that is dedicated to storing
-Netdata metric values per legacy database engine instance (see [details on the legacy mode](#legacy-mode) below).
+To configure the database engine, look for the `page cache size MB` and `dbengine multihost disk space MB` settings in
+the `[db]` section of your `netdata.conf`.
```conf
[db]
- dbengine disk space MB = 256
+ dbengine page cache size MB = 32
+ dbengine multihost disk space MB = 256
```
-### Streaming metrics to the database engine
-
-When using the multihost database engine, all parent and child nodes share the same `page cache size MB` and `dbengine
-multihost disk space MB` in a single dbengine instance. The [**database engine
-calculator**](/docs/store/change-metrics-storage#calculate-the-system-resources-ram-disk-space-needed-to-store-metrics)
-helps you properly set `page cache size MB` and `dbengine multihost disk space MB` on your parent node to allocate enough
-resources based on your metrics retention policy and how many child nodes you have.
-
-#### Legacy mode
+### v1.23.2 and prior
_For Netdata Agents earlier than v1.23.2_, the Agent on the parent node uses one dbengine instance for itself, and
another instance for every child node it receives metrics from. If you had four streaming nodes, you would have five
instances in total (`1 parent + 4 child nodes = 5 instances`).
-The Agent allocates resources for each instance separately using the `dbengine disk space MB` (**deprecated**) setting. If
-`dbengine disk space MB`(**deprecated**) is set to the default `256`, each instance is given 256 MiB in disk space, which
-means the total disk space required to store all instances is, roughly, `256 MiB * 1 parent * 4 child nodes = 1280 MiB`.
+The Agent allocates resources for each instance separately using the `dbengine disk space MB` (**deprecated**) setting.
+If
+`dbengine disk space MB`(**deprecated**) is set to the default `256`, each instance is given 256 MiB in disk space,
+which means the total disk space required to store all instances is,
+roughly, `256 MiB * 1 parent * 4 child nodes = 1280 MiB`.
#### Backward compatibility
@@ -90,41 +130,44 @@ Agent.
For more information about setting `[db].mode` on your nodes, in addition to other streaming configurations, see
[streaming](/docs/agent/streaming).
-### Memory requirements
+## Requirements & limitations
+
+### Memory
Using database mode `dbengine` we can overcome most memory restrictions and store a dataset that is much larger than the
available memory.
There are explicit memory requirements **per** DB engine **instance**:
-- The total page cache memory footprint will be an additional `#dimensions-being-collected x 4096 x 2` bytes over what
- the user configured with `page cache size MB`.
+- The total page cache memory footprint will be an additional `#dimensions-being-collected x 4096 x 2` bytes over what
+ the user configured with `dbengine page cache size MB`.
+
-- an additional `#pages-on-disk x 4096 x 0.03` bytes of RAM are allocated for metadata.
+- an additional `#pages-on-disk x 4096 x 0.03` bytes of RAM are allocated for metadata.
- - roughly speaking this is 3% of the uncompressed disk space taken by the DB files.
+ - roughly speaking this is 3% of the uncompressed disk space taken by the DB files.
- - for very highly compressible data (compression ratio > 90%) this RAM overhead is comparable to the disk space
- footprint.
+ - for very highly compressible data (compression ratio > 90%) this RAM overhead is comparable to the disk space
+ footprint.
An important observation is that RAM usage depends on both the `page cache size` and the `dbengine multihost disk space`
options.
-You can use our [database engine
-calculator](/docs/store/change-metrics-storage#calculate-the-system-resources-ram-disk-space-needed-to-store-metrics)
+You can use
+our [database engine calculator](/docs/store/change-metrics-storage#calculate-the-system-resources-ram-disk-space-needed-to-store-metrics)
to validate the memory requirements for your particular system(s) and configuration (**out-of-date**).
-### Disk space requirements
+### Disk space
There are explicit disk space requirements **per** DB engine **instance**:
-- The total disk space footprint will be the maximum between `#dimensions-being-collected x 4096 x 2` bytes or what
- the user configured with `dbengine multihost disk space` or `dbengine disk space`.
+- The total disk space footprint will be the maximum between `#dimensions-being-collected x 4096 x 2` bytes or what the
+ user configured with `dbengine multihost disk space` or `dbengine disk space`.
-### File descriptor requirements
+### File descriptor
-The Database Engine may keep a **significant** amount of files open per instance (e.g. per streaming child or
-parent server). When configuring your system you should make sure there are at least 50 file descriptors available per
+The Database Engine may keep a **significant** amount of files open per instance (e.g. per streaming child or parent
+server). When configuring your system you should make sure there are at least 50 file descriptors available per
`dbengine` instance.
Netdata allocates 25% of the available file descriptors to its Database Engine instances. This means that only 25% of
@@ -148,7 +191,7 @@ ulimit -n 65536
```
at the beginning of the service file. Alternatively you can change the system-wide limits of the kernel by changing
- `/etc/sysctl.conf`. For linux that would be:
+`/etc/sysctl.conf`. For linux that would be:
```conf
fs.file-max = 65536
@@ -165,8 +208,8 @@ You can apply the settings by running `sysctl -p` or by rebooting.
## Files
-With the DB engine mode the metric data are stored in database files. These files are organized in pairs, the
-datafiles and their corresponding journalfiles, e.g.:
+With the DB engine mode the metric data are stored in database files. These files are organized in pairs, the datafiles
+and their corresponding journalfiles, e.g.:
```sh
datafile-1-0000000001.ndf
@@ -191,15 +234,16 @@ storage at lower granularity.
The DB engine stores chart metric values in 4096-byte pages in memory. Each chart dimension gets its own page to store
consecutive values generated from the data collectors. Those pages comprise the **Page Cache**.
-When those pages fill up they are slowly compressed and flushed to disk. It can take `4096 / 4 = 1024 seconds = 17
-minutes`, for a chart dimension that is being collected every 1 second, to fill a page. Pages can be cut short when we
-stop Netdata or the DB engine instance so as to not lose the data. When we query the DB engine for data we trigger disk
-read I/O requests that fill the Page Cache with the requested pages and potentially evict cold (not recently used)
-pages.
+When those pages fill up, they are slowly compressed and flushed to disk. It can
+take `4096 / 4 = 1024 seconds = 17 minutes`, for a chart dimension that is being collected every 1 second, to fill a
+page. Pages can be cut short when we stop Netdata or the DB engine instance so as to not lose the data. When we query
+the DB engine for data we trigger disk read I/O requests that fill the Page Cache with the requested pages and
+potentially evict cold (not recently used)
+pages.
When the disk quota is exceeded the oldest values are removed from the DB engine at real time, by automatically deleting
the oldest datafile and journalfile pair. Any corresponding pages residing in the Page Cache will also be invalidated
-and removed. The DB engine logic will try to maintain between 10 and 20 file pairs at any point in time.
+and removed. The DB engine logic will try to maintain between 10 and 20 file pairs at any point in time.
The Database Engine uses direct I/O to avoid polluting the OS filesystem caches and does not generate excessive I/O
traffic so as to create the minimum possible interference with other applications.
@@ -214,19 +258,19 @@ Constellation ES.3 2TB magnetic HDD and a SAMSUNG MZQLB960HAJR-00007 960GB NAND
For our workload, we defined 32 charts with 128 metrics each, giving us a total of 4096 metrics. We defined 1 worker
thread per chart (32 threads) that generates new data points with a data generation interval of 1 second. The time axis
of the time-series is emulated and accelerated so that the worker threads can generate as many data points as possible
-without delays.
+without delays.
-We also defined 32 worker threads that perform queries on random metrics with semi-random time ranges. The
-starting time of the query is randomly selected between the beginning of the time-series and the time of the latest data
-point. The ending time is randomly selected between 1 second and 1 hour after the starting time. The pseudo-random
-numbers are generated with a uniform distribution.
+We also defined 32 worker threads that perform queries on random metrics with semi-random time ranges. The starting time
+of the query is randomly selected between the beginning of the time-series and the time of the latest data point. The
+ending time is randomly selected between 1 second and 1 hour after the starting time. The pseudo-random numbers are
+generated with a uniform distribution.
The data are written to the database at the same time as they are read from it. This is a concurrent read/write mixed
-workload with a duration of 60 seconds. The faster `dbengine` runs, the bigger the dataset size becomes since more
-data points will be generated. We set a page cache size of 64MiB for the two disk-bound scenarios. This way, the dataset
-size of the metric data is much bigger than the RAM that is being used for caching so as to trigger I/O requests most
-of the time. In our final scenario, we set the page cache size to 16 GiB. That way, the dataset fits in the page cache
-so as to avoid all disk bottlenecks.
+workload with a duration of 60 seconds. The faster `dbengine` runs, the bigger the dataset size becomes since more data
+points will be generated. We set a page cache size of 64MiB for the two disk-bound scenarios. This way, the dataset size
+of the metric data is much bigger than the RAM that is being used for caching so as to trigger I/O requests most of the
+time. In our final scenario, we set the page cache size to 16 GiB. That way, the dataset fits in the page cache so as to
+avoid all disk bottlenecks.
The reported numbers are the following:
@@ -237,15 +281,15 @@ The reported numbers are the following:
| N/A | 16 GiB | 6.8 GiB | 118.2M | 30.2M |
where "reads/sec" is the number of metric data points being read from the database via its API per second and
-"writes/sec" is the number of metric data points being written to the database per second.
+"writes/sec" is the number of metric data points being written to the database per second.
Notice that the HDD numbers are pretty high and not much slower than the SSD numbers. This is thanks to the database
engine design being optimized for rotating media. In the database engine disk I/O requests are:
-- asynchronous to mask the high I/O latency of HDDs.
-- mostly large to reduce the amount of HDD seeking time.
-- mostly sequential to reduce the amount of HDD seeking time.
-- compressed to reduce the amount of required throughput.
+- asynchronous to mask the high I/O latency of HDDs.
+- mostly large to reduce the amount of HDD seeking time.
+- mostly sequential to reduce the amount of HDD seeking time.
+- compressed to reduce the amount of required throughput.
As a result, the HDD is not thousands of times slower than the SSD, which is typical for other workloads.
diff --git a/docs/agent/database/ram.md b/docs/agent/database/ram.md
new file mode 100644
index 000000000..963cc4e56
--- /dev/null
+++ b/docs/agent/database/ram.md
@@ -0,0 +1,6 @@
+---
+title: "RAM database modes"
+description: "Netdata's RAM database modes."
+custom_edit_url: https://github.com/netdata/netdata/edit/master/database/ram/README.md
+---
+
diff --git a/docs/agent/demo-sites.md b/docs/agent/demo-sites.md
index b97fc51cc..ee8323346 100644
--- a/docs/agent/demo-sites.md
+++ b/docs/agent/demo-sites.md
@@ -12,7 +12,6 @@ You can also view live demos of Netdata at **[https://www.netdata.cloud](https:/
| :------------------ | :-------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| :------------------------------------------------- |
| London (UK) | **[london3.my-netdata.io](https://london3.my-netdata.io)**
(this is the global Netdata **registry** and has **named** and **mysql** charts) | [](https://london3.my-netdata.io) | [DigitalOcean.com](https://m.do.co/c/83dc9f941745) |
| Atlanta (USA) | **[cdn77.my-netdata.io](https://cdn77.my-netdata.io)**
(with **named** and **mysql** charts) | [](https://cdn77.my-netdata.io) | [CDN77.com](https://www.cdn77.com/) |
-| Israel | **[octopuscs.my-netdata.io](https://octopuscs.my-netdata.io)** | [](https://octopuscs.my-netdata.io) | [OctopusCS.com](https://www.octopuscs.com) |
| Bangalore (India) | **[bangalore.my-netdata.io](https://bangalore.my-netdata.io)** | [](https://bangalore.my-netdata.io) | [DigitalOcean.com](https://m.do.co/c/83dc9f941745) |
| Frankfurt (Germany) | **[frankfurt.my-netdata.io](https://frankfurt.my-netdata.io)** | [](https://frankfurt.my-netdata.io) | [DigitalOcean.com](https://m.do.co/c/83dc9f941745) |
| New York (USA) | **[newyork.my-netdata.io](https://newyork.my-netdata.io)** | [](https://newyork.my-netdata.io) | [DigitalOcean.com](https://m.do.co/c/83dc9f941745) |
diff --git a/docs/agent/libnetdata/arrayalloc.md b/docs/agent/libnetdata/arrayalloc.md
new file mode 100644
index 000000000..1116ff6b4
--- /dev/null
+++ b/docs/agent/libnetdata/arrayalloc.md
@@ -0,0 +1,7 @@
+---
+title: "Array Allocator"
+custom_edit_url: https://github.com/netdata/netdata/edit/master/libnetdata/arrayalloc/README.md
+---
+
+
+
diff --git a/docs/agent/libnetdata/dictionary.md b/docs/agent/libnetdata/dictionary.md
index b6232fd56..ff6e0e6b2 100644
--- a/docs/agent/libnetdata/dictionary.md
+++ b/docs/agent/libnetdata/dictionary.md
@@ -97,7 +97,7 @@ This call is used to get the value of an item, given its name. It utilizes the `
For **multi-threaded** operation, the `dictionary_get()` call gets a shared read lock on the dictionary.
-In clone mode, the value returned is not guaranteed to be valid, as any other thread may delete the item from the dictionary at any time. To ensure the value will be available, use `dictionary_acquire_item()`, which uses a reference counter to defer deletes until the item is released.
+In clone mode, the value returned is not guaranteed to be valid, as any other thread may delete the item from the dictionary at any time. To ensure the value will be available, use `dictionary_get_and_acquire_item()`, which uses a reference counter to defer deletes until the item is released.
The format is:
@@ -133,7 +133,7 @@ Where:
> **IMPORTANT**
There is also an **unsafe** version (without locks) of this call. This is to be used when traversing the dictionary, to delete the current item. It should never be called without an active lock on the dictionary, which can only be acquired while traversing.
-### dictionary_acquire_item()
+### dictionary_get_and_acquire_item()
This call can be used the search and get a dictionary item, while ensuring that it will be available for use, until `dictionary_acquired_item_release()` is called.
@@ -149,7 +149,7 @@ DICTIONARY *dict = dictionary_create(DICTIONARY_FLAGS_NONE);
dictionary_set(dict, "name", "value", 6);
// find the item we added and acquire it
-void *item = dictionary_acquire_item(dict, "name");
+void *item = dictionary_get_and_acquire_item(dict, "name");
// extract its value
char *value = (char *)dictionary_acquired_item_value(dict, item);
diff --git a/docs/agent/ml.md b/docs/agent/ml.md
index 9fb2491c7..b750a13c7 100644
--- a/docs/agent/ml.md
+++ b/docs/agent/ml.md
@@ -1,5 +1,5 @@
---
-title: Machine learning (ML) powered anomaly detection
+title: Configure machine learning (ML) powered anomaly detection
custom_edit_url: https://github.com/netdata/netdata/edit/master/ml/README.md
description: This is an in-depth look at how Netdata uses ML to detect anomalies.
keywords: [machine learning, anomaly detection, Netdata ML]
diff --git a/docs/agent/packaging/docker.md b/docs/agent/packaging/docker.md
index 8c593c61b..415b1a210 100644
--- a/docs/agent/packaging/docker.md
+++ b/docs/agent/packaging/docker.md
@@ -11,7 +11,7 @@ you get set up quickly, and doesn't install anything permanent on the system, wh
See our full list of Docker images at [Docker Hub](https://hub.docker.com/r/netdata/netdata).
-Starting with v1.30, Netdata collects anonymous usage information by default and sends it to a self hosted PostHog instance within the Netdata infrastructure. Read
+Starting with v1.30, Netdata collects anonymous usage information by default and sends it to a self-hosted PostHog instance within the Netdata infrastructure. Read
about the information collected, and learn how to-opt, on our [anonymous statistics](/docs/agent/anonymous-statistics)
page.
@@ -133,12 +133,12 @@ You can control how the health checks run by using the environment variable `NET
In most cases, the default behavior of checking the `/api/v1/info`
endpoint will be sufficient. If you are using a configuration which
-disables the web server or restricts access to certain API's, you will
+disables the web server or restricts access to certain APIs, you will
need to use a non-default configuration for health checks to work.
## Configure Agent containers
-If you started an Agent container using one of the [recommended methods](#create-a-new-netdata-agent-container) and you
+If you started an Agent container using one of the [recommended methods](#create-a-new-netdata-agent-container), and you
want to edit Netdata's configuration, you must first use `docker exec` to attach to the container. Replace `netdata`
with the name of your container.
@@ -153,6 +153,9 @@ to restart the container: `docker restart netdata`.
### Host-editable configuration
+> **Warning**: [edit-config](/docs/configure/nodes#the-netdata-config-directory) script doesn't work when executed on
+> the host system.
+
If you want to make your container's configuration directory accessible from the host system, you need to use a
[volume](https://docs.docker.com/storage/bind-mounts/) rather than a bind mount. The following commands create a
temporary `netdata_tmp` container, which is used to populate a `netdataconfig` directory, which is then mounted inside
@@ -222,7 +225,7 @@ volumes:
You can change the hostname of a Docker container, and thus the name that appears in the local dashboard and in Netdata
Cloud, when creating a new container. If you want to change the hostname of a Netdata container _after_ you started it,
-you can safely stop and remove it. You configuration and metrics data reside in persistent volumes and are reattached to
+you can safely stop and remove it. Your configuration and metrics data reside in persistent volumes and are reattached to
the recreated container.
If you use `docker-run`, use the `--hostname` option with `docker run`.
@@ -251,7 +254,7 @@ how you created the container.
### Add or remove other volumes
-Some of the volumes are optional depending on how you use Netdata:
+Some volumes are optional depending on how you use Netdata:
- If you don't want to use the apps.plugin functionality, you can remove the mounts of `/etc/passwd` and `/etc/group`
(they are used to get proper user and group names for the monitored host) to get slightly better security.
@@ -367,6 +370,42 @@ services:
- DOCKER_USR=root
```
+### Docker container network interfaces monitoring
+
+Netdata can map a virtual interface in the system namespace to an interface inside a Docker container
+when using network [bridge](https://docs.docker.com/network/bridge/) driver. To do this, the Netdata container needs
+additional privileges:
+
+- the host PID mode. This turns on sharing between container and the host operating system the PID
+ address space (needed to get list of PIDs from `cgroup.procs` file).
+
+- `SYS_ADMIN` capability (needed to execute `setns()`).
+
+**docker run**:
+
+```bash
+docker run -d --name=netdata \
+ ...
+ --pid=host \
+ --cap-add SYS_ADMIN \
+ ...
+ netdata/netdata
+```
+
+**docker compose**:
+
+```yaml
+version: '3'
+services:
+ netdata:
+ image: netdata/netdata
+ container_name: netdata
+ pid: host
+ cap_add:
+ - SYS_ADMIN
+ ...
+```
+
### Pass command line options to Netdata
Since we use an [ENTRYPOINT](https://docs.docker.com/engine/reference/builder/#entrypoint) directive, you can provide
@@ -384,7 +423,7 @@ email address for [Let's Encrypt](https://letsencrypt.org/) before starting.
### Caddyfile
-This file needs to be placed in `/opt` with name `Caddyfile`. Here you customize your domain and you need to provide
+This file needs to be placed in `/opt` with name `Caddyfile`. Here you customize your domain, and you need to provide
your email address to obtain a Let's Encrypt certificate. Certificate renewal will happen automatically and will be
executed internally by the caddy server.
@@ -450,10 +489,10 @@ You may either use the command line tools available or take advantage of our Tra
### Inside Netdata organization, using Travis CI
-To enable Travis CI integration on your own repositories (Docker and Github), you need to be part of the Netdata
+To enable Travis CI integration on your own repositories (Docker and GitHub), you need to be part of the Netdata
organization.
-Once you have contacted the Netdata owners to setup you up on Github and Travis, execute the following steps
+Once you have contacted the Netdata owners to setup you up on GitHub and Travis, execute the following steps
- Preparation
- Have Netdata forked on your personal GitHub account
@@ -478,7 +517,7 @@ Once you have contacted the Netdata owners to setup you up on Github and Travis,
- While in Travis settings, under Netdata repository settings in the Environment Variables section, you need to add
the following:
- - `DOCKER_USERNAME` and `DOCKER_PWD` variables so that Travis can login to your Docker Hub account and publish
+ - `DOCKER_USERNAME` and `DOCKER_PWD` variables so that Travis can log in to your Docker Hub account and publish
Docker images there.
- `REPOSITORY` variable to `NETDATA_DEVELOPER/netdata`, where `NETDATA_DEVELOPER` is your GitHub handle again.
- `GITHUB_TOKEN` variable with the token generated on the preparation step, for Travis workflows to function
diff --git a/docs/agent/packaging/installer/methods/freebsd.md b/docs/agent/packaging/installer/methods/freebsd.md
index 42dce74c8..3f76a2711 100644
--- a/docs/agent/packaging/installer/methods/freebsd.md
+++ b/docs/agent/packaging/installer/methods/freebsd.md
@@ -20,7 +20,7 @@ This is how to install the latest Netdata version on FreeBSD:
Install required packages (**need root permission**):
```sh
-pkg install bash e2fsprogs-libuuid git curl autoconf automake pkgconf pidof Judy liblz4 libuv json-c cmake gmake
+pkg install bash e2fsprogs-libuuid git curl autoconf automake pkgconf pidof liblz4 libuv json-c cmake gmake
```
Download Netdata:
diff --git a/docs/agent/packaging/installer/methods/manual.md b/docs/agent/packaging/installer/methods/manual.md
index db9759e87..25c5f83a5 100644
--- a/docs/agent/packaging/installer/methods/manual.md
+++ b/docs/agent/packaging/installer/methods/manual.md
@@ -25,9 +25,6 @@ and other operating systems and is regularly tested. You can find this tool [her
- **Alpine** Linux and its derivatives
- You have to install `bash` yourself, before using the installer.
-- **Arch** Linux and its derivatives
- - You need arch/aur for package Judy.
-
- **Gentoo** Linux and its derivatives
- **Debian** Linux and its derivatives (including **Ubuntu**, **Mint**)
@@ -67,16 +64,16 @@ This is how to do it by hand:
```sh
# Debian / Ubuntu
-apt-get install zlib1g-dev uuid-dev libuv1-dev liblz4-dev libjudy-dev libssl-dev libelf-dev libmnl-dev libprotobuf-dev protobuf-compiler gcc g++ make git autoconf autoconf-archive autogen automake pkg-config curl python cmake
+apt-get install zlib1g-dev uuid-dev libuv1-dev liblz4-dev libssl-dev libelf-dev libmnl-dev libprotobuf-dev protobuf-compiler gcc g++ make git autoconf autoconf-archive autogen automake pkg-config curl python cmake
# Fedora
-dnf install zlib-devel libuuid-devel libuv-devel lz4-devel Judy-devel openssl-devel elfutils-libelf-devel libmnl-devel protobuf-devel protobuf-compiler gcc gcc-c++ make git autoconf autoconf-archive autogen automake pkgconfig curl findutils python cmake
+dnf install zlib-devel libuuid-devel libuv-devel lz4-devel openssl-devel elfutils-libelf-devel libmnl-devel protobuf-devel protobuf-compiler gcc gcc-c++ make git autoconf autoconf-archive autogen automake pkgconfig curl findutils python cmake
# CentOS / Red Hat Enterprise Linux
-yum install autoconf automake curl gcc gcc-c++ git libmnl-devel libuuid-devel openssl-devel libuv-devel lz4-devel Judy-devel elfutils-libelf-devel protobuf protobuf-devel protobuf-compiler make nc pkgconfig python zlib-devel cmake
+yum install autoconf automake curl gcc gcc-c++ git libmnl-devel libuuid-devel openssl-devel libuv-devel lz4-devel elfutils-libelf-devel protobuf protobuf-devel protobuf-compiler make nc pkgconfig python zlib-devel cmake
# openSUSE
-zypper install zlib-devel libuuid-devel libuv-devel liblz4-devel judy-devel libopenssl-devel libelf-devel libmnl-devel protobuf-devel gcc gcc-c++ make git autoconf autoconf-archive autogen automake pkgconfig curl findutils python cmake
+zypper install zlib-devel libuuid-devel libuv-devel liblz4-devel libopenssl-devel libelf-devel libmnl-devel protobuf-devel gcc gcc-c++ make git autoconf autoconf-archive autogen automake pkgconfig curl findutils python cmake
```
Once Netdata is compiled, to run it the following packages are required (already installed using the above commands):
@@ -117,7 +114,6 @@ Netdata DB engine can be enabled when these are installed (they are optional):
| package | description|
|:-----:|-----------|
| `liblz4` | Extremely fast compression algorithm, version r129 or greater|
-| `Judy` | General purpose dynamic array|
| `openssl`| Cryptography and SSL/TLS toolkit|
*Netdata will greatly benefit if you have the above packages installed, but it will still work without them.*
@@ -175,8 +171,6 @@ yum install -y http://repo.okay.com.mx/centos/8/x86_64/release/okay-release-1-3.
# Install Devel Packages
yum install autoconf automake curl gcc git cmake libuuid-devel openssl-devel libuv-devel lz4-devel make nc pkgconfig python3 zlib-devel
-# Install Judy-Devel directly
-yum install -y http://mirror.centos.org/centos/8/PowerTools/x86_64/os/Packages/Judy-devel-1.0.5-18.module_el8.1.0+217+4d875839.x86_64.rpm
```
## Install Netdata
diff --git a/docs/agent/packaging/installer/methods/pfsense.md b/docs/agent/packaging/installer/methods/pfsense.md
index 0a06209fa..607f0ddc6 100644
--- a/docs/agent/packaging/installer/methods/pfsense.md
+++ b/docs/agent/packaging/installer/methods/pfsense.md
@@ -25,7 +25,6 @@ pkg install -y pkgconf bash e2fsprogs-libuuid libuv nano
Then run the following commands to download various dependencies from the FreeBSD repository.
```sh
-pkg add http://pkg.freebsd.org/FreeBSD:12:amd64/latest/All/Judy-1.0.5_3.txz
pkg add http://pkg.freebsd.org/FreeBSD:12:amd64/latest/All/json-c-0.15_1.txz
pkg add http://pkg.freebsd.org/FreeBSD:12:amd64/latest/All/py38-certifi-2021.10.8.txz
pkg add http://pkg.freebsd.org/FreeBSD:12:amd64/latest/All/py38-asn1crypto-1.4.0.txz
diff --git a/docs/agent/packaging/installer/methods/source.md b/docs/agent/packaging/installer/methods/source.md
index 6d15ccfb2..56f81ddf4 100644
--- a/docs/agent/packaging/installer/methods/source.md
+++ b/docs/agent/packaging/installer/methods/source.md
@@ -32,7 +32,6 @@ Additionally, the following build time features require additional dependencies:
- dbengine metric storage:
- liblz4 r129 or newer
- OpenSSL 1.0 or newer (LibreSSL _amy_ work, but is largely untested).
- - [libJudy](http://judy.sourceforge.net/)
- Netdata Cloud support:
- A working internet connection
- A recent version of CMake
diff --git a/docs/agent/packaging/platform_support.md b/docs/agent/packaging/platform_support.md
index 78411d75c..c79afcdf8 100644
--- a/docs/agent/packaging/platform_support.md
+++ b/docs/agent/packaging/platform_support.md
@@ -57,16 +57,16 @@ to work on these platforms with minimal user effort.
| Docker | 19.03 or newer | x86\_64, i386, ARMv7, AArch64, POWER8+ | See our [Docker documentation](/docs/agent/packaging/docker) for more info on using Netdata on Docker |
| Debian | 11.x | x86\_64, i386, ARMv7, AArch64 | |
| Debian | 10.x | x86\_64, i386, ARMv7, AArch64 | |
-| Debian | 9.x | x86\_64, i386, ARMv7, AArch64 | |
| Fedora | 36 | x86\_64, ARMv7, AArch64 | |
| Fedora | 35 | x86\_64, ARMv7, AArch64 | |
+| openSUSE | Leap 15.4 | x86\_64, AArch64 | |
| openSUSE | Leap 15.3 | x86\_64, AArch64 | |
+| Oracle Linux | 9.x | x86\_64, AArch64 | |
| Oracle Linux | 8.x | x86\_64, AArch64 | |
| Red Hat Enterprise Linux | 9.x | x86\_64, AArch64 | |
| Red Hat Enterprise Linux | 8.x | x86\_64, AArch64 | |
| Red Hat Enterprise Linux | 7.x | x86\_64 | |
| Ubuntu | 22.04 | x86\_64, ARMv7, AArch64 | |
-| Ubuntu | 21.10 | x86\_64, i386, ARMv7, AArch64 | |
| Ubuntu | 20.04 | x86\_64, i386, ARMv7, AArch64 | |
| Ubuntu | 18.04 | x86\_64, i386, ARMv7, AArch64 | |
@@ -146,14 +146,13 @@ This is a list of platforms that we have supported in the recent past but no lon
| -------- | ------- | ----- |
| Alpine Linux | 3.12 | EOL as of 2022-05-01 |
| Alpine Linux | 3.11 | EOL as of 2021-11-01 |
-| Fedora 34 | EOL as of 2022-06-07 |
+| Debian | 9.x | EOL as of 2022-06-30 |
+| Fedora | 34 | EOL as of 2022-06-07 |
| Fedora | 33 | EOL as of 2021-11-30 |
-| Fedora | 32 | EOL as of 2021-05-25 |
| FreeBSD | 11-STABLE | EOL as of 2021-10-30 |
| openSUSE | Leap 15.2 | EOL as of 2021-12-01 |
+| Ubuntu | 21.10 | EOL as of 2022-07-31 |
| Ubuntu | 21.04 | EOL as of 2022-01-01 |
-| Ubuntu | 20.10 | EOL as of 2021-07-22 |
-| Ubuntu | 16.04 | EOL as of 2021-04-02 |
## Static builds
diff --git a/docs/agent/running-behind-h2o.md b/docs/agent/running-behind-h2o.md
new file mode 100644
index 000000000..d16b8ba03
--- /dev/null
+++ b/docs/agent/running-behind-h2o.md
@@ -0,0 +1,183 @@
+---
+title: "Running Netdata behind H2O"
+custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/Running-behind-h2o.md
+---
+
+
+
+[H2O](https://h2o.examp1e.net/) is a new generation HTTP server that provides quicker response to users with less CPU utilization when compared to older generation of web servers.
+
+It is notable for having much simpler configuration than many popular HTTP servers, low resource requirements, and integrated native support for many things that other HTTP servers may need special setup to use.
+
+## Why H2O
+
+- Sane configuration defaults mean that typical configurations are very minimalistic and easy to work with.
+
+- Native support for HTTP/2 provides improved performance when accessing the Netdata dashboard remotely.
+
+- Password protect access to the Netdata dashboard without requiring Netdata Cloud.
+
+## H2O configuration file.
+
+On most systems, the H2O configuration is found under `/etc/h2o`. H2O uses [YAML 1.1](https://yaml.org/spec/1.1/), with a few special extensions, for it’s configuration files, with the main configuration file being `/etc/h2o/h2o.conf`.
+
+You can edit the H2O configuration file with Nano, Vim or any other text editors with which you are comfortable.
+
+After making changes to the configuration files, perform the following:
+
+- Test the configuration with `h2o -m test -c /etc/h2o/h2o.conf`
+
+- Restart H2O to apply tha changes with `/etc/init.d/h2o restart` or `service h2o restart`
+
+## Ways to access Netdata via H2O
+
+### As a virtual host
+
+With this method instead of `SERVER_IP_ADDRESS:19999`, the Netdata dashboard can be accessed via a human-readable URL such as `netdata.example.com` used in the configuration below.
+
+```yaml
+hosts:
+ netdata.example.com:
+ listen:
+ port: 80
+ paths:
+ /:
+ proxy.preserve-host: ON
+ proxy.reverse.url: http://127.0.0.1:19999
+```
+
+### As a subfolder of an existing virtual host
+
+This method is recommended when Netdata is to be served from a subfolder (or directory).
+In this case, the virtual host `netdata.example.com` already exists and Netdata has to be accessed via `netdata.example.com/netdata/`.
+
+```yaml
+hosts:
+ netdata.example.com:
+ listen:
+ port: 80
+ paths:
+ /netdata:
+ redirect:
+ status: 301
+ url: /netdata/
+ /netdata/:
+ proxy.preserve-host: ON
+ proxy.reverse.url: http://127.0.0.1:19999
+```
+
+### As a subfolder for multiple Netdata servers, via one H2O instance
+
+This is the recommended configuration when one H2O instance will be used to manage multiple Netdata servers via subfolders.
+
+```yaml
+hosts:
+ netdata.example.com:
+ listen:
+ port: 80
+ paths:
+ /netdata/server1:
+ redirect:
+ status: 301
+ url: /netdata/server1/
+ /netdata/server1/:
+ proxy.preserve-host: ON
+ proxy.reverse.url: http://198.51.100.1:19999
+ /netdata/server2:
+ redirect:
+ status: 301
+ url: /netdata/server2/
+ /netdata/server2/:
+ proxy.preserve-host: ON
+ proxy.reverse.url: http://198.51.100.2:19999
+```
+
+Of course you can add as many backend servers as you like.
+
+Using the above, you access Netdata on the backend servers, like this:
+
+- `http://netdata.example.com/netdata/server1/` to reach Netdata on `198.51.100.1:19999`
+- `http://netdata.example.com/netdata/server2/` to reach Netdata on `198.51.100.2:19999`
+
+### Encrypt the communication between H2O and Netdata
+
+In case Netdata's web server has been [configured to use TLS](/docs/agent/web/server#enabling-tls-support), it is
+necessary to specify inside the H2O configuration that the final destination is using TLS. To do this, change the
+`http://` on the `proxy.reverse.url` line in your H2O configuration with `https://`
+
+### Enable authentication
+
+Create an authentication file to enable basic authentication via H2O, this secures your Netdata dashboard.
+
+If you don't have an authentication file, you can use the following command:
+
+```sh
+printf "yourusername:$(openssl passwd -apr1)" > /etc/h2o/passwords
+```
+
+And then add a basic authentication handler to each path definition:
+
+```yaml
+hosts:
+ netdata.example.com:
+ listen:
+ port: 80
+ paths:
+ /:
+ mruby.handler: |
+ require "htpasswd.rb"
+ Htpasswd.new("/etc/h2o/passwords", "netdata.example.com")
+ proxy.preserve-host: ON
+ proxy.reverse.url: http://127.0.0.1:19999
+```
+
+For more information on using basic authentication with H2O, see [their official documentation](https://h2o.examp1e.net/configure/basic_auth.html).
+
+## Limit direct access to Netdata
+
+If your H2O server is on `localhost`, you can use this to ensure external access is only possible through H2O:
+
+```
+[web]
+ bind to = 127.0.0.1 ::1
+```
+
+---
+
+You can also use a unix domain socket. This will provide faster communication between H2O and Netdata as well:
+
+```
+[web]
+ bind to = unix:/run/netdata/netdata.sock
+```
+
+In the H2O configuration, use a line like the following to connect to Netdata via the unix socket:
+
+```yaml
+proxy.reverse.url http://[unix:/run/netdata/netdata.sock]
+```
+
+---
+
+If your H2O server is not on localhost, you can set:
+
+```
+[web]
+ bind to = *
+ allow connections from = IP_OF_H2O_SERVER
+```
+
+*note: Netdata v1.9+ support `allow connections from`*
+
+`allow connections from` accepts [Netdata simple patterns](/docs/agent/libnetdata/simple_pattern) to match against
+the connection IP address.
+
+## Prevent the double access.log
+
+H2O logs accesses and Netdata logs them too. You can prevent Netdata from generating its access log, by setting
+this in `/etc/netdata/netdata.conf`:
+
+```
+[global]
+ access log = none
+```
diff --git a/docs/agent/web/api.md b/docs/agent/web/api.md
index 23c994625..31baac51f 100644
--- a/docs/agent/web/api.md
+++ b/docs/agent/web/api.md
@@ -7,8 +7,6 @@ custom_edit_url: https://github.com/netdata/netdata/edit/master/web/api/README.m
## Netdata REST API
-The complete documentation of the Netdata API is available at the **[Swagger Editor](https://editor.swagger.io/?url=https://raw.githubusercontent.com/netdata/netdata/master/web/api/netdata-swagger.yaml)**.
-
-If your prefer it over the Swagger Editor, you can also use **[Swagger UI](https://registry.my-netdata.io/swagger/#!/default/get_data)**. This however does not provide all the information available.
-
+The complete documentation of the Netdata API is available as a Swagger API document [in our GitHub repository](https://raw.githubusercontent.com/netdata/netdata/master/web/api/netdata-swagger.yaml). You can view it online using the **[Swagger Editor](https://editor.swagger.io/?url=https://raw.githubusercontent.com/netdata/netdata/master/web/api/netdata-swagger.yaml)**.
+If your prefer it over the Swagger Editor, you can also use [Swagger UI](https://github.com/swagger-api/swagger-ui) by pointing at `web/api/netdata-swagger.yaml` in the Netdata source tree (or at https://raw.githubusercontent.com/netdata/netdata/master/web/api/netdata-swagger.yaml if you want to use the Swagger API definitions directly from our GitHub repository). This however does not provide all the information available.
diff --git a/docs/agent/web/api/queries/median.md b/docs/agent/web/api/queries/median.md
index 961b2e5ec..70bba1ebd 100644
--- a/docs/agent/web/api/queries/median.md
+++ b/docs/agent/web/api/queries/median.md
@@ -13,6 +13,20 @@ The median is the value separating the higher half from the lower half of a data
`median` is not an accurate average. However, it eliminates all spikes, by sorting
all the values in a period, and selecting the value in the middle of the sorted array.
+Netdata also supports `trimmed-median`, which trims a percentage of the smaller and bigger values prior to finding the
+median. The following `trimmed-median` functions are defined:
+
+- `trimmed-median1`
+- `trimmed-median2`
+- `trimmed-median3`
+- `trimmed-median5`
+- `trimmed-median10`
+- `trimmed-median15`
+- `trimmed-median20`
+- `trimmed-median25`
+
+The function `trimmed-median` is an alias for `trimmed-median5`.
+
## how to use
Use it in alarms like this:
@@ -27,7 +41,8 @@ lookup: median -1m unaligned of my_dimension
`median` does not change the units. For example, if the chart units is `requests/sec`, the result
will be again expressed in the same units.
-It can also be used in APIs and badges as `&group=median` in the URL.
+It can also be used in APIs and badges as `&group=median` in the URL. Additionally, a percentage may be given with
+`&group_options=` to trim all small and big values before finding the median.
## Examples
diff --git a/docs/agent/web/api/queries/percentile.md b/docs/agent/web/api/queries/percentile.md
new file mode 100644
index 000000000..94ff13c60
--- /dev/null
+++ b/docs/agent/web/api/queries/percentile.md
@@ -0,0 +1,58 @@
+---
+title: "Percentile"
+description: "Use percentile in API queries and health entities to find the 'percentile' value from a sample, eliminating any unwanted spikes in the returned metrics."
+custom_edit_url: https://github.com/netdata/netdata/edit/master/web/api/queries/percentile/README.md
+---
+
+
+
+The percentile is the average value of a series using only the smaller N percentile of the values.
+(a population or a probability distribution).
+
+Netdata applies linear interpolation on the last point, if the percentile requested does not give a round number of
+points.
+
+The following percentile aliases are defined:
+
+- `percentile25`
+- `percentile50`
+- `percentile75`
+- `percentile80`
+- `percentile90`
+- `percentile95`
+- `percentile97`
+- `percentile98`
+- `percentile99`
+
+The default `percentile` is an alias for `percentile95`.
+Any percentile may be requested using the `group_options` query parameter.
+
+## how to use
+
+Use it in alarms like this:
+
+```
+ alarm: my_alarm
+ on: my_chart
+lookup: percentile95 -1m unaligned of my_dimension
+ warn: $this > 1000
+```
+
+`percentile` does not change the units. For example, if the chart units is `requests/sec`, the result
+will be again expressed in the same units.
+
+It can also be used in APIs and badges as `&group=percentile` in the URL and the additional parameter `group_options`
+may be used to request any percentile (e.g. `&group=percentile&group_options=96`).
+
+## Examples
+
+Examining last 1 minute `successful` web server responses:
+
+- 
+- 
+- 
+- 
+
+## References
+
+- .
diff --git a/docs/agent/web/api/queries/trimmed_mean.md b/docs/agent/web/api/queries/trimmed_mean.md
new file mode 100644
index 000000000..fc9865cbe
--- /dev/null
+++ b/docs/agent/web/api/queries/trimmed_mean.md
@@ -0,0 +1,56 @@
+---
+title: "Trimmed Mean"
+description: "Use trimmed-mean in API queries and health entities to find the average value from a sample, eliminating any unwanted spikes in the returned metrics."
+custom_edit_url: https://github.com/netdata/netdata/edit/master/web/api/queries/trimmed_mean/README.md
+---
+
+
+
+The trimmed mean is the average value of a series excluding the smallest and biggest points.
+
+Netdata applies linear interpolation on the last point, if the percentage requested to be excluded does not give a
+round number of points.
+
+The following percentile aliases are defined:
+
+- `trimmed-mean1`
+- `trimmed-mean2`
+- `trimmed-mean3`
+- `trimmed-mean5`
+- `trimmed-mean10`
+- `trimmed-mean15`
+- `trimmed-mean20`
+- `trimmed-mean25`
+
+The default `trimmed-mean` is an alias for `trimmed-mean5`.
+Any percentage may be requested using the `group_options` query parameter.
+
+## how to use
+
+Use it in alarms like this:
+
+```
+ alarm: my_alarm
+ on: my_chart
+lookup: trimmed-mean5 -1m unaligned of my_dimension
+ warn: $this > 1000
+```
+
+`trimmed-mean` does not change the units. For example, if the chart units is `requests/sec`, the result
+will be again expressed in the same units.
+
+It can also be used in APIs and badges as `&group=trimmed-mean` in the URL and the additional parameter `group_options`
+may be used to request any percentage (e.g. `&group=trimmed-mean&group_options=29`).
+
+## Examples
+
+Examining last 1 minute `successful` web server responses:
+
+- 
+- 
+- 
+- 
+
+## References
+
+- .
diff --git a/docs/configure/nodes.md b/docs/configure/nodes.md
index 6f6f74cdd..cb1a3e2ad 100644
--- a/docs/configure/nodes.md
+++ b/docs/configure/nodes.md
@@ -61,6 +61,10 @@ The Netdata config directory also contains one symlink:
versions are copied into the config directory when opened with `edit-config`. _Do not edit the files in
`/usr/lib/netdata/conf.d`, as they are overwritten by updates to the Netdata Agent._
+## Configure a Netdata docker container
+
+See [configure agent containers](/docs/agent/packaging/docker#configure-agent-containers).
+
## Use `edit-config` to edit configuration files
The **recommended way to easily and safely edit Netdata's configuration** is with the `edit-config` script. This script
diff --git a/docs/store/change-metrics-storage.md b/docs/store/change-metrics-storage.md
index 74066f8e5..db97d9ece 100644
--- a/docs/store/change-metrics-storage.md
+++ b/docs/store/change-metrics-storage.md
@@ -6,72 +6,95 @@ custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/store/chang
-import { Calculator } from '../../src/components/agent/dbCalc/'
+The Netdata Agent uses a custom made time-series database (TSDB), named the [`dbengine`](/docs/agent/database/engine), to store metrics.
-The Netdata Agent uses a time-series database (TSDB), named the [database engine
-(`dbengine`)](/docs/agent/database/engine), to store metrics data. The most recently-collected metrics are stored in RAM,
-and when metrics reach a certain age, and based on how much system RAM you allocate toward storing metrics in memory,
-they are compressed and "spilled" to disk for long-term storage.
+The default settings retain approximately two day's worth of metrics on a system collecting 2,000 metrics every second,
+but the Netdata Agent is highly configurable if you want your nodes to store days, weeks, or months worth of per-second
+data.
-The default settings retain about two day's worth of metrics on a system collecting 2,000 metrics every second, but the
-Netdata Agent is highly configurable if you want your nodes to store days, weeks, or months worth of per-second data.
-
-The Netdata Agent uses two settings in `netdata.conf` to change the behavior of the database engine:
+The Netdata Agent uses the following three fundamental settings in `netdata.conf` to change the behavior of the database engine:
```conf
[global]
- page cache size = 32
+ dbengine page cache size = 32
dbengine multihost disk space = 256
+ storage tiers = 1
```
-`page cache size` sets the maximum amount of RAM (in MiB) the database engine uses to cache and index recent metrics.
+`dbengine page cache size` sets the maximum amount of RAM (in MiB) the database engine uses to cache and index recent
+metrics.
`dbengine multihost disk space` sets the maximum disk space (again, in MiB) the database engine uses to store
-historical, compressed metrics. When the size of stored metrics exceeds the allocated disk space, the database engine
-removes the oldest metrics on a rolling basis.
+historical, compressed metrics and `storage tiers` specifies the number of storage tiers you want to have in
+your `dbengine`. When the size of stored metrics exceeds the allocated disk space, the database engine removes the
+oldest metrics on a rolling basis.
## Calculate the system resources (RAM, disk space) needed to store metrics
You can store more or less metrics using the database engine by changing the allocated disk space. Use the calculator
-below to find an appropriate value for `dbengine multihost disk space` based on how many metrics your node(s) collect,
-whether you are streaming metrics to a parent node, and more.
+below to find the appropriate value for the `dbengine` based on how many metrics your node(s) collect, whether you are
+streaming metrics to a parent node, and more.
+
+You do not need to edit the `dbengine page cache size` setting to store more metrics using the database engine. However,
+if you want to store more metrics _specifically in memory_, you can increase the cache size.
+
+:::tip
+
+We advise you to visit the [tiering mechanism](/docs/agent/database/engine#tiering) reference. This will help you
+configure the Agent to retain metrics for longer periods.
-You do not need to edit the `page cache size` setting to store more metrics using the database engine. However, if you
-want to store more metrics _specifically in memory_, you can increase the cache size.
+:::
-> ⚠️ This calculator provides an estimate of disk and RAM usage for **metrics storage**, along with its best
-> recommendation for the `dbengine multihost disk space` setting. Real-life usage may vary based on the accuracy of the
-> values you enter below, changes in the compression ratio, and the types of metrics stored.
+:::caution
-
+This calculator provides an estimation of disk and RAM usage for **metrics usage**. Real-life usage may vary based on
+the accuracy of the values you enter below, changes in the compression ratio, and the types of metrics stored.
+
+:::
+
+Download
+the [calculator](https://docs.google.com/spreadsheets/d/e/2PACX-1vTYMhUU90aOnIQ7qF6iIk6tXps57wmY9lxS6qDXznNJrzCKMDzxU3zkgh8Uv0xj_XqwFl3U6aHDZ6ag/pub?output=xlsx)
+to optimize the data retention to your preferences. Utilize the "Front" spreadsheet. Experiment with the variables which
+are padded with yellow to come up with the best settings for your use case.
## Edit `netdata.conf` with recommended database engine settings
-Now that you have a recommended setting for `dbengine multihost disk space`, open `netdata.conf` with
-[`edit-config`](/docs/configure/nodes#use-edit-config-to-edit-configuration-files) and look for the `dbengine
-multihost disk space` setting. Change it to the value recommended above. For example:
+Now that you have a recommended setting for your Agent's `dbengine`, open `netdata.conf` with
+[`edit-config`](/docs/configure/nodes#use-edit-config-to-edit-configuration-files) and look for the `[db]`
+subsection. Change it to the recommended values you calculated from the calculator. For example:
```conf
-[global]
- dbengine multihost disk space = 1024
+[db]
+ mode = dbengine
+ storage tiers = 3
+ update every = 1
+ dbengine multihost disk space MB = 1024
+ dbengine page cache size MB = 32
+ dbengine tier 1 update every iterations = 60
+ dbengine tier 1 multihost disk space MB = 384
+ dbengine tier 1 page cache size MB = 32
+ dbengine tier 2 update every iterations = 60
+ dbengine tier 2 multihost disk space MB = 16
+ dbengine tier 2 page cache size MB = 32
```
-Save the file and restart the Agent with `sudo systemctl restart netdata`, or the [appropriate
-method](/docs/configure/start-stop-restart) for your system, to change the database engine's size.
+Save the file and restart the Agent with `sudo systemctl restart netdata`, or
+the [appropriate method](/docs/configure/start-stop-restart) for your system, to change the database engine's size.
## What's next?
-If you have multiple nodes with the Netdata Agent installed, you can [stream
-metrics](/docs/metrics-storage-management/how-streaming-works) from any number of _child_ nodes to a _parent_ node
-and store metrics using a centralized time-series database. Streaming allows you to centralize your data, run Agents as
-headless collectors, replicate data, and more.
+If you have multiple nodes with the Netdata Agent installed, you
+can [stream metrics](/docs/metrics-storage-management/how-streaming-works) from any number of _child_ nodes to a _
+parent_ node and store metrics using a centralized time-series database. Streaming allows you to centralize your data,
+run Agents as headless collectors, replicate data, and more.
-Storing metrics with the database engine is completely interoperable with [exporting to other time-series
-databases](/docs/export/external-databases). With exporting, you can use the node's resources to surface metrics
-when [viewing dashboards](/docs/visualize/interact-dashboards-charts), while also archiving metrics elsewhere for
-further analysis, visualization, or correlation with other tools.
+Storing metrics with the database engine is completely interoperable
+with [exporting to other time-series databases](/docs/export/external-databases). With exporting, you can use the
+node's resources to surface metrics when [viewing dashboards](/docs/visualize/interact-dashboards-charts), while also
+archiving metrics elsewhere for further analysis, visualization, or correlation with other tools.
### Related reference documentation
- [Netdata Agent · Database engine](/docs/agent/database/engine)
+- [Netdata Agent · Database engine configuration option](/docs/agent/daemon/config#[db]-section-options)
diff --git a/docs/store/distributed-data-architecture.md b/docs/store/distributed-data-architecture.md
index 23dcf000e..68236e195 100644
--- a/docs/store/distributed-data-architecture.md
+++ b/docs/store/distributed-data-architecture.md
@@ -10,34 +10,43 @@ Netdata uses a distributed data architecture to help you collect and store per-s
Every node in your infrastructure, whether it's one or a thousand, stores the metrics it collects.
Netdata Cloud bridges the gap between many distributed databases by _centralizing the interface_ you use to query and
-visualize your nodes' metrics. When you [look at charts in Netdata
-Cloud](/docs/visualize/interact-dashboards-charts), the metrics values are queried directly from that node's database
-and securely streamed to Netdata Cloud, which proxies them to your browser.
+visualize your nodes' metrics. When you [look at charts in Netdata Cloud](/docs/visualize/interact-dashboards-charts)
+, the metrics values are queried directly from that node's database and securely streamed to Netdata Cloud, which
+proxies them to your browser.
Netdata's distributed data architecture has a number of benefits:
-- **Performance**: Every query to a node's database takes only a few milliseconds to complete for responsiveness when
- viewing dashboards or using features like [Metric
- Correlations](/docs/cloud/insights/metric-correlations).
-- **Scalability**: As your infrastructure scales, install the Netdata Agent on every new node to immediately add it to
- your monitoring solution without adding cost or complexity.
-- **1-second granularity**: Without an expensive centralized data lake, you can store all of your nodes' per-second
- metrics, for any period of time, while keeping costs down.
-- **No filtering or selecting of metrics**: Because Netdata's distributed data architecture allows you to store all
- metrics, you don't have to configure which metrics you retain. Keep everything for full visibility during
- troubleshooting and root cause analysis.
-- **Easy maintenance**: There is no centralized data lake to purchase, allocate, monitor, and update, removing
- complexity from your monitoring infrastructure.
+- **Performance**: Every query to a node's database takes only a few milliseconds to complete for responsiveness when
+ viewing dashboards or using features
+ like [Metric Correlations](/docs/cloud/insights/metric-correlations).
+- **Scalability**: As your infrastructure scales, install the Netdata Agent on every new node to immediately add it to
+ your monitoring solution without adding cost or complexity.
+- **1-second granularity**: Without an expensive centralized data lake, you can store all of your nodes' per-second
+ metrics, for any period of time, while keeping costs down.
+- **No filtering or selecting of metrics**: Because Netdata's distributed data architecture allows you to store all
+ metrics, you don't have to configure which metrics you retain. Keep everything for full visibility during
+ troubleshooting and root cause analysis.
+- **Easy maintenance**: There is no centralized data lake to purchase, allocate, monitor, and update, removing
+ complexity from your monitoring infrastructure.
-## Does Netdata Cloud store my metrics?
+## Ephemerality of metrics
-Netdata Cloud does not store metric values.
+The ephemerality of metrics plays an important role in retention. In environments where metrics collection is dynamic and
+new metrics are constantly being generated, we are interested about 2 parameters:
-To enable certain features, such as [viewing active alarms](/docs/monitor/view-active-alarms) or [filtering by
-hostname/service](/docs/cloud/war-rooms#node-filter), Netdata Cloud does store configured
-alarms, their status, and a list of active collectors.
+1. The **expected concurrent number of metrics** as an average for the lifetime of the database. This affects mainly the
+ storage requirements.
-Netdata does not and never will sell your personal data or data about your deployment.
+2. The **expected total number of unique metrics** for the lifetime of the database. This affects mainly the memory
+ requirements for having all these metrics indexed and available to be queried.
+
+## Granularity of metrics
+
+The granularity of metrics (the frequency they are collected and stored, i.e. their resolution) is significantly
+affecting retention.
+
+Lowering the granularity from per second to every two seconds, will double their retention and half the CPU requirements
+of the Netdata Agent, without affecting disk space or memory requirements.
## Long-term metrics storage with Netdata
@@ -47,7 +56,8 @@ appropriate amount of RAM and disk space.
Read our document on changing [how long Netdata stores metrics](/docs/store/change-metrics-storage) on your nodes for
details.
-## Other options for your metrics data
+You can also stream between nodes using [streaming](/docs/agent/streaming), allowing to replicate databases and create
+your own centralized data lake of metrics, if you choose to do so.
While a distributed data architecture is the default when monitoring infrastructure with Netdata, you can also configure
its behavior based on your needs or the type of infrastructure you manage.
@@ -55,12 +65,19 @@ its behavior based on your needs or the type of infrastructure you manage.
To archive metrics to an external time-series database, such as InfluxDB, Graphite, OpenTSDB, Elasticsearch,
TimescaleDB, and many others, see details on [integrating Netdata via exporting](/docs/export/external-databases).
-You can also stream between nodes using [streaming](/docs/agent/streaming), allowing to replicate databases and create
-your own centralized data lake of metrics, if you choose to do so.
-
When you use the database engine to store your metrics, you can always perform a quick backup of a node's
`/var/cache/netdata/dbengine/` folder using the tool of your choice.
+## Does Netdata Cloud store my metrics?
+
+Netdata Cloud does not store metric values.
+
+To enable certain features, such as [viewing active alarms](/docs/monitor/view-active-alarms)
+or [filtering by hostname/service](/docs/cloud/war-rooms#node-filter), Netdata Cloud does
+store configured alarms, their status, and a list of active collectors.
+
+Netdata does not and never will sell your personal data or data about your deployment.
+
## What's next?
You can configure the Netdata Agent to store days, weeks, or months worth of distributed, per-second data by
diff --git a/guides/deploy/ansible.md b/guides/deploy/ansible.md
index f079af3b9..400213b31 100644
--- a/guides/deploy/ansible.md
+++ b/guides/deploy/ansible.md
@@ -56,6 +56,8 @@ mv community/netdata-agent-deployment/ansible-quickstart .
rm -rf community
```
+Or if you don't want to clone the entire repository, use the [gitzip browser extension](https://gitzip.org/) to get the netdata-agent-deployment directory as a zip file.
+
Next, `cd` into the Ansible directory.
```bash
diff --git a/guides/longer-metrics-storage.md b/guides/longer-metrics-storage.md
index 1a6f03a0e..eeb54b18f 100644
--- a/guides/longer-metrics-storage.md
+++ b/guides/longer-metrics-storage.md
@@ -1,150 +1,158 @@
---
-title: "Change how long Netdata stores metrics"
-description: "With a single configuration change, the Netdata Agent can store days, weeks, or months of metrics at its famous per-second granularity."
+title: "Netdata Longer Metrics Retention"
+description: ""
custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/longer-metrics-storage.md
---
-Netdata helps you collect thousands of system and application metrics every second, but what about storing them for the
-long term?
+Metrics retention affects 3 parameters on the operation of a Netdata Agent:
-Many people think Netdata can only store about an hour's worth of real-time metrics, but that's simply not true any
-more. With the right settings, Netdata is quite capable of efficiently storing hours or days worth of historical,
-per-second metrics without having to rely on an [exporting engine](/docs/export/external-databases).
+1. The disk space required to store the metrics.
+2. The memory the Netdata Agent will require to have that retention available for queries.
+3. The CPU resources that will be required to query longer time-frames.
-This guide gives two options for configuring Netdata to store more metrics. **We recommend the default [database
-engine](#using-the-database-engine)**, but you can stick with or switch to the round-robin database if you prefer.
+As retention increases, the resources required to support that retention increase too.
-Let's get started.
+Since Netdata Agents usually run at the edge, inside production systems, Netdata Agent **parents** should be considered. When having a **parent - child** setup, the child (the Netdata Agent running on a production system) delegates all its functions, including longer metrics retention and querying, to the parent node that can dedicate more resources to this task. A single Netdata Agent parent can centralize multiple children Netdata Agents (dozens, hundreds, or even thousands depending on its available resources).
-## Using the database engine
-The database engine uses RAM to store recent metrics while also using a "spill to disk" feature that takes advantage of
-available disk space for long-term metrics storage. This feature of the database engine allows you to store a much
-larger dataset than your system's available RAM.
+## Ephemerality of metrics
-The database engine is currently the default method of storing metrics, but if you're not sure which database you're
-using, check out your `netdata.conf` file and look for the `[db].mode` setting:
+The ephemerality of metrics plays an important role in retention. In environments where metrics stop being collected and new metrics are constantly being generated, we are interested about 2 parameters:
-```conf
-[db]
- mode = dbengine
-```
-
-If `[db].mode` is set to anything but `dbengine`, change it and restart Netdata using the standard command for
-restarting services on your system. You're now using the database engine!
+1. The **expected concurrent number of metrics** as an average for the lifetime of the database.
+ This affects mainly the storage requirements.
-What makes the database engine efficient? While it's structured like a traditional database, the database engine splits
-data between RAM and disk. The database engine caches and indexes data on RAM to keep memory usage low, and then
-compresses older metrics onto disk for long-term storage.
+2. The **expected total number of unique metrics** for the lifetime of the database.
+ This affects mainly the memory requirements for having all these metrics indexed and available to be queried.
-When the Netdata dashboard queries for historical metrics, the database engine will use its cache, stored in RAM, to
-return relevant metrics for visualization in charts.
+## Granularity of metrics
-Now, given that the database engine uses _both_ RAM and disk, there are two other settings to consider: `page cache
-size MB` and `dbengine multihost disk space MB`.
+The granularity of metrics (the frequency they are collected and stored, i.e. their resolution) is significantly affecting retention.
-```conf
-[db]
- page cache size MB = 32
- dbengine multihost disk space MB = 256
-```
+Lowering the granularity from per second to every two seconds, will double their retention and half the CPU requirements of the Netdata Agent, without affecting disk space or memory requirements.
-`[db].page cache size MB` sets the maximum amount of RAM the database engine will use for caching and indexing.
-`[db].dbengine multihost disk space MB` sets the maximum disk space the database engine will use for storing
-compressed metrics. The default settings retain about four day's worth of metrics on a system collecting 2,000 metrics
-every second.
+## Which database mode to use
-[**See our database engine
-calculator**](/docs/store/change-metrics-storage#calculate-the-system-resources-ram-disk-space-needed-to-store-metrics)
-to help you correctly set `[db].dbengine multihost disk space MB` based on your needs. The calculator gives an accurate estimate
-based on how many child nodes you have, how many metrics your Agent collects, and more.
+Netdata Agents support multiple database modes.
-With the database engine active, you can back up your `/var/cache/netdata/dbengine/` folder to another location for
-redundancy.
+The default mode `[db].mode = dbengine` has been designed to scale for longer retentions.
-Now that you know how to switch to the database engine, let's cover the default round-robin database for those who
-aren't ready to make the move.
+The other available database modes are designed to minimize resource utilization and should usually be considered on **parent - child** setups at the children side.
-## Using the round-robin database
+So,
-In previous versions, Netdata used a round-robin database to store 1 hour of per-second metrics.
+* On a single node setup, use `[db].mode = dbengine` to increase retention.
+* On a **parent - child** setup, use `[db].mode = dbengine` on the parent to increase retention and a more resource efficient mode (like `save`, `ram` or `none`) for the child to minimize resources utilization.
-To see if you're still using this database, or if you would like to switch to it, open your `netdata.conf` file and see
-if `[db].mode` option is set to `save`.
+To use `dbengine`, set this in `netdata.conf` (it is the default):
-```conf
+```
[db]
- mode = save
+ mode = dbengine
```
-If `[db].mode` is set to `save`, then you're using the round-robin database. If so, the `[db].retention` option is set to
-`3600`, which is the equivalent to 3,600 seconds, or one hour.
+## Tiering
-To increase your historical metrics, you can increase `[db].retention` to the number of seconds you'd like to store:
+`dbengine` supports tiering. Tiering allows having up to 3 versions of the data:
-```conf
+1. Tier 0 is the high resolution data.
+2. Tier 1 is the first tier that samples data every 60 data collections of Tier 0.
+3. Tier 2 is the second tier that samples data every 3600 data collections of Tier 0 (60 of Tier 1).
+
+To enable tiering set `[db].storage tiers` in `netdata.conf` (the default is 1, to enable only Tier 0):
+
+```
[db]
- # 2 hours = 2 * 60 * 60 = 7200 seconds
- retention = 7200
- # 4 hours = 4 * 60 * 60 = 14440 seconds
- retention = 14440
- # 24 hours = 24 * 60 * 60 = 86400 seconds
- retention = 86400
+ mode = dbengine
+ storage tiers = 3
```
-And so on.
+## Disk space requirements
-Next, check to see how many metrics Netdata collects on your system, and how much RAM that uses. Visit the Netdata
-dashboard and look at the bottom-right corner of the interface. You'll find a sentence similar to the following:
+Netdata Agents require about 1 bytes on disk per database point on Tier 0 and 4 times more on higher tiers (Tier 1 and 2). They require 4 times more storage per point compared to Tier 0, because for every point higher tiers store `min`, `max`, `sum`, `count` and `anomaly rate` (the values are 5, but they require 4 times the storage because `count` and `anomaly rate` are 16-bit integers). The `average` is calculated on the fly at query time using `sum / count`.
-> Every second, Netdata collects 1,938 metrics, presents them in 299 charts and monitors them with 81 alarms. Netdata is
-> using 25 MB of memory on **netdata-linux** for 1 hour, 6 minutes and 36 seconds of real-time history.
+### Tier 0 - per second for a week
-On this desktop system, using a Ryzen 5 1600 and 16GB of RAM, the round-robin databases uses 25 MB of RAM to store just
-over an hour's worth of data for nearly 2,000 metrics.
+For 2000 metrics, collected every second and retained for a week, Tier 0 needs: 1 byte x 2000 metrics x 3600 secs per hour x 24 hours per day x 7 days per week = 1100MB.
-You should base this number on two things: How much history you need for your use case, and how much RAM you're willing
-to dedicate to Netdata.
+The setting to control this is in `netdata.conf`:
-How much RAM will a longer retention use? Let's use a little math.
+```
+[db]
+ mode = dbengine
+
+ # per second data collection
+ update every = 1
+
+ # enable only Tier 0
+ storage tiers = 1
+
+ # Tier 0, per second data for a week
+ dbengine multihost disk space MB = 1100
+```
-The round-robin database needs 4 bytes for every value Netdata collects. If Netdata collects metrics every second,
-that's 4 bytes, per second, per metric.
+By setting it to `1100` and restarting the Netdata Agent, this node will start maintaining about a week of data. But pay attention to the number of metrics. If you have more than 2000 metrics on a node, or you need more that a week of high resolution metrics, you may need to adjust this setting accordingly.
-```text
-4 bytes * X seconds * Y metrics = RAM usage in bytes
-```
+### Tier 1 - per minute for a month
-Let's assume your system collects 1,000 metrics per second.
+Tier 1 is by default sampling the data every 60 points of Tier 0. If Tier 0 is per second, then Tier 1 is per minute.
-```text
-4 bytes * 3600 seconds * 1,000 metrics = 14400000 bytes = 14.4 MB RAM
-```
+Tier 1 needs 4 times more storage per point compared to Tier 0. So, for 2000 metrics, with per minute resolution, retained for a month, Tier 1 needs: 4 bytes x 2000 metrics x 60 minutes per hour x 24 hours per day x 30 days per month = 330MB.
-With that formula, you can calculate the RAM usage for much larger history settings.
-
-```conf
-# 2 hours at 1,000 metrics per second
-4 bytes * 7200 seconds * 1,000 metrics = 28800000 bytes = 28.8 MB RAM
-# 2 hours at 2,000 metrics per second
-4 bytes * 7200 seconds * 2,000 metrics = 57600000 bytes = 57.6 MB RAM
-# 4 hours at 2,000 metrics per second
-4 bytes * 14440 seconds * 2,000 metrics = 115520000 bytes = 115.52 MB RAM
-# 24 hours at 1,000 metrics per second
-4 bytes * 86400 seconds * 1,000 metrics = 345600000 bytes = 345.6 MB RAM
+Do this in `netdata.conf`:
+
+```
+[db]
+ mode = dbengine
+
+ # per second data collection
+ update every = 1
+
+ # enable only Tier 0 and Tier 1
+ storage tiers = 2
+
+ # Tier 0, per second data for a week
+ dbengine multihost disk space MB = 1100
+
+ # Tier 1, per minute data for a month
+ dbengine tier 1 multihost disk space MB = 330
```
-## What's next?
+Once `netdata.conf` is edited, the Netdata Agent needs to be restarted for the changes to take effect.
+
+### Tier 2 - per hour for a year
+
+Tier 2 is by default sampling data every 3600 points of Tier 0 (60 of Tier 1). If Tier 0 is per second, then Tier 2 is per hour.
-Now that you have either configured database engine or round-robin database engine to store more metrics, you'll
-probably want to see it in action!
+The storage requirements are the same to Tier 1.
+
+For 2000 metrics, with per hour resolution, retained for a year, Tier 2 needs: 4 bytes x 2000 metrics x 24 hours per day x 365 days per year = 67MB.
+
+Do this in `netdata.conf`:
+
+```
+[db]
+ mode = dbengine
+
+ # per second data collection
+ update every = 1
+
+ # enable only Tier 0 and Tier 1
+ storage tiers = 3
+
+ # Tier 0, per second data for a week
+ dbengine multihost disk space MB = 1100
+
+ # Tier 1, per minute data for a month
+ dbengine tier 1 multihost disk space MB = 330
+
+ # Tier 2, per hour data for a year
+ dbengine tier 2 multihost disk space MB = 67
+```
-For more information about how to pan charts to view historical metrics, see our documentation on [using
-charts](/docs/agent/web#using-charts).
+Once `netdata.conf` is edited, the Netdata Agent needs to be restarted for the changes to take effect.
-And if you'd now like to reduce Netdata's resource usage, view our [performance
-guide](/guides/configure/performance) for our best practices on optimization.
diff --git a/guides/monitor/anomaly-detection.md b/guides/monitor/anomaly-detection.md
index 84fe54206..4a27f671a 100644
--- a/guides/monitor/anomaly-detection.md
+++ b/guides/monitor/anomaly-detection.md
@@ -5,270 +5,71 @@ image: /img/seo/guides/monitor/anomaly-detection.png
author: "Andrew Maguire"
author_title: "Analytics & ML Lead"
author_img: "/img/authors/andy-maguire.jpg"
-custom_edit_url: https://github.com/netdata/netdata/edit/master/ml/README.md
+custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/anomaly-detection.md
---
## Overview
-As of [`v1.32.0`](https://github.com/netdata/netdata/releases/tag/v1.32.0), Netdata comes with some ML powered [anomaly detection](https://en.wikipedia.org/wiki/Anomaly_detection) capabilities built into it and available to use out of the box, with minimal configuration required.
+As of [`v1.32.0`](https://github.com/netdata/netdata/releases/tag/v1.32.0), Netdata comes with some ML powered [anomaly detection](https://en.wikipedia.org/wiki/Anomaly_detection) capabilities built into it and available to use out of the box, with zero configuration required (ML was enabled by default in `v1.35.0-29-nightly` in [this PR](https://github.com/netdata/netdata/pull/13158), previously it required a one line config change).
-🚧 **Note**: This functionality is still under active development and considered experimental. Changes might cause the feature to break. We dogfood it internally and among early adopters within the Netdata community to build the feature. If you would like to get involved and help us with some feedback, email us at analytics-ml-team@netdata.cloud or come join us in the [🤖-ml-powered-monitoring](https://discord.gg/4eRSEUpJnc) channel of the Netdata discord.
+This means that in addition to collecting raw value metrics, the Netdata agent will also produce an [`anomaly-bit`](/docs/agent/ml#anomaly-bit---100--anomalous-0--normal) every second which will be `100` when recent raw metric values are considered anomalous by Netdata and `0` when they look normal. Once we aggregate beyond one second intervals this aggregated `anomaly-bit` becomes an ["anomaly rate"](/docs/agent/ml#anomaly-rate---averageanomaly-bit).
-Once ML is enabled, Netdata will begin training a model for each dimension. By default this model is a [k-means clustering](https://en.wikipedia.org/wiki/K-means_clustering) model trained on the most recent 4 hours of data. Rather than just using the most recent value of each raw metric, the model works on a preprocessed ["feature vector"](#feature-vector) of recent smoothed and differenced values. This should enable the model to detect a wider range of potentially anomalous patterns in recent observations as opposed to just point anomalies like big spikes or drops. ([This infographic](https://user-images.githubusercontent.com/2178292/144414415-275a3477-5b47-43d6-8959-509eb48ebb20.png) shows some different types of anomalies.)
-
-The sections below will introduce some of the main concepts:
-- anomaly bit
-- anomaly score
-- anomaly rate
-- anomaly detector
-
-Additional explanations and details can be found in the [Glossary](#glossary) and [Notes](#notes) at the bottom of the page.
-
-### Anomaly Bit - (100 = Anomalous, 0 = Normal)
-
-Once each model is trained, Netdata will begin producing an ["anomaly score"](#anomaly-score) at each time step for each dimension. This ["anomaly score"](#anomaly-score) is essentially a distance measure to the trained cluster centers of the model (by default each model has k=2, so two cluster centers are learned). More anomalous looking data should be more distant to those cluster centers. If this ["anomaly score"](#anomaly-score) is sufficiently large, this is a sign that the recent raw values of the dimension could potentially be anomalous. By default, "sufficiently large" means that the distance is in the 99th percentile or above of all distances observed during training or, put another way, it has to be further away than the furthest 1% of the data used during training. Once this threshold is passed, the ["anomaly bit"](#anomaly-bit) corresponding to that dimension is set to 100 to flag it as anomalous, otherwise it would be left at 0 to signal normal data.
-
-What this means is that in addition to the raw value of each metric, Netdata now also stores an ["anomaly bit"](#anomaly-bit) that is either 100 (anomalous) or 0 (normal). Importantly, this is achieved without additional storage overhead due to how the anomaly bit has been implemented within the existing internal Netdata storage representation.
-
-This ["anomaly bit"](#anomaly-bit) is exposed via the `anomaly-bit` key that can be passed to the `options` param of the `/api/v1/data` REST API.
-
-For example, here are some recent raw dimension values for `system.ip` on our [london](http://london.my-netdata.io/) demo server:
-
-[`https://london.my-netdata.io/api/v1/data?chart=system.ip`](https://london.my-netdata.io/api/v1/data?chart=system.ip)
-
-```
-{
- "labels": ["time", "received", "sent"],
- "data":
- [
- [ 1638365672, 54.84098, -76.70201],
- [ 1638365671, 124.4328, -309.7543],
- [ 1638365670, 123.73152, -167.9056],
- ...
- ]
-}
-```
-
-And if we add the `&options=anomaly-bit` params, we can see the "anomaly bit" value corresponding to each raw dimension value:
-
-[`https://london.my-netdata.io/api/v1/data?chart=system.ip&options=anomaly-bit`](https://london.my-netdata.io/api/v1/data?chart=system.ip&options=anomaly-bit)
-
-```
-{
- "labels": ["time", "received", "sent"],
- "data":
- [
- [ 1638365672, 0, 0],
- [ 1638365671, 0, 0],
- [ 1638365670, 0, 0],
- ...
- ]
-}
-```
-In this example, the dimensions "received" and "sent" didn't show any abnormal behavior, so the anomaly bit is zero.
-Under normal circumstances, the anomaly bit will mostly be 0. However, there can be random fluctuations setting the anomaly to 100, although this very much depends on the nature of the dimension in question.
-
-### Anomaly Rate - average(anomaly bit)
-
-Once all models have been trained, we can think of the Netdata dashboard as essentially a big matrix or table of 0's and 100's. If we consider this "anomaly bit"-based representation of the state of the node, we can now think about how we might detect overall node level anomalies. The figure below illustrates the main ideas.
-
-```
- dimensions
-time d1 d2 d3 d4 d5 NAR
- 1 0 0 0 0 0 0%
- 2 0 0 0 0 100 20%
- 3 0 0 0 0 0 0%
- 4 0 100 0 0 0 20%
- 5 100 0 0 0 0 20%
- 6 0 100 100 0 100 60%
- 7 0 100 0 100 0 40%
- 8 0 0 0 0 100 20%
- 9 0 0 100 100 0 40%
- 10 0 0 0 0 0 0%
-
-DAR 10% 30% 20% 20% 30% 22% NAR_t1-t10
-
-DAR = Dimension Anomaly Rate
-NAR = Node Anomaly Rate
-NAR_t1-t10 = Node Anomaly Rate over t1 to t10
-```
-
-To work out an ["anomaly rate"](#anomaly-rate), we can just average a row or a column in any direction. For example, if we were to just average along a row then this would be the ["node anomaly rate"](#node-anomaly-rate) (all dimensions) at time t. Likewise if we averaged a column then we would have the ["dimension anomaly rate"](#dimension-anomaly-rate) for each dimension over the time window t=1-10. Extending this idea, we can work out an overall ["anomaly rate"](#anomaly-rate) for the whole matrix or any subset of it we might be interested in.
-
-### Anomaly Detector - Node level anomaly events
-
-An ["anomaly detector"](#anomaly-detector) looks at all anomaly bits of a node. Netdata's anomaly detector produces an ["anomaly event"](#anomaly-event) when a the percentage of anomaly bits is high enough for a persistent amount of time. This anomaly event signals that there was sufficient evidence among all the anomaly bits that some strange behavior might have been detected in a more global sense across the node.
-
-Essentially if the ["Node Anomaly Rate"](#node-anomaly-rate) (NAR) passes a defined threshold and stays above that threshold for a persistent amount of time, a "Node [Anomaly Event](#anomaly-event)" will be triggered.
-
-These anomaly events are currently exposed via `/api/v1/anomaly_events`
-
-**Note**: Clicking the link below will likely return an empty list of `[]`. This is the response when no anomaly events exist in the specified range. The example response below is illustrative of what the response would be when one or more anomaly events exist within the range of `after` to `before`.
-
-https://london.my-netdata.io/api/v1/anomaly_events?after=1638365182000&before=1638365602000
-
-If an event exists within the window, the result would be a list of start and end times.
-
-```
-[
- [
- 1638367788,
- 1638367851
- ]
-]
-```
-
-Information about each anomaly event can then be found at the `/api/v1/anomaly_event_info` endpoint (making sure to pass the `after` and `before` params):
-
-**Note**: If you click the below url you will get a `null` since no such anomaly event exists as the response is just an illustrative example taken from a node that did have such an anomaly event.
-
-https://london.my-netdata.io/api/v1/anomaly_event_info?after=1638367788&before=1638367851
+To be as concrete as possible, the below api call shows how to access the raw anomaly bit of the `system.cpu` chart from the [london.my-netdata.io](https://london.my-netdata.io) Netdata demo server. Passing `options=anomaly-bit` returns the anomay bit instead of the raw metric value.
```
-[
- [
- 0.66,
- "netdata.response_time|max"
- ],
- [
- 0.63,
- "netdata.response_time|average"
- ],
- [
- 0.54,
- "netdata.requests|requests"
- ],
- ...
+https://london.my-netdata.io/api/v1/data?chart=system.cpu&options=anomaly-bit
```
-The query returns a list of dimension anomaly rates for all dimensions that were considered part of the detected anomaly event.
-
-**Note**: We plan to build additional anomaly detection and exploration features into both Netdata Agent and Netdata Cloud. The current endpoints are still under active development to power the upcoming features.
-
-## Configuration
-
-To enable anomaly detection:
-1. Find and open the Netdata configuration file `netdata.conf`.
-2. In the `[ml]` section, set `enabled = yes`.
-3. Restart netdata (typically `sudo systemctl restart netdata`).
-
-**Note**: If you would like to learn more about configuring Netdata please see [the configuration guide](/guides/step-by-step/step-04).
-
-Below is a list of all the available configuration params and their default values.
+If we aggregate the above to just 1 point by adding `points=1` we get an "[Anomaly Rate](/docs/agent/ml#anomaly-rate---averageanomaly-bit)":
```
-[ml]
- # enabled = no
- # maximum num samples to train = 14400
- # minimum num samples to train = 3600
- # train every = 3600
- # num samples to diff = 1
- # num samples to smooth = 3
- # num samples to lag = 5
- # maximum number of k-means iterations = 1000
- # dimension anomaly score threshold = 0.99
- # host anomaly rate threshold = 0.01000
- # minimum window size = 30.00000
- # maximum window size = 600.00000
- # idle window size = 30.00000
- # window minimum anomaly rate = 0.25000
- # anomaly event min dimension rate threshold = 0.05000
- # hosts to skip from training = !*
- # charts to skip from training = !system.* !cpu.* !mem.* !disk.* !disk_* !ip.* !ipv4.* !ipv6.* !net.* !net_* !netfilter.* !services.* !apps.* !groups.* !user.* !ebpf.* !netdata.* *
+https://london.my-netdata.io/api/v1/data?chart=system.cpu&options=anomaly-bit&points=1
```
-### Descriptions (min/max)
-
-- `enabled`: `yes` to enable, `no` to disable.
-- `maximum num samples to train`: (`3600`/`21600`) This is the maximum amount of time you would like to train each model on. For example, the default of `14400` trains on the preceding 4 hours of data, assuming an `update every` of 1 second.
-- `minimum num samples to train`: (`900`/`21600`) This is the minimum amount of data required to be able to train a model. For example, the default of `3600` implies that once at least 1 hour of data is available for training, a model is trained, otherwise it is skipped and checked again at the next training run.
-- `train every`: (`1800`/`21600`) This is how often each model will be retrained. For example, the default of `3600` means that each model is retrained every hour. Note: The training of all models is spread out across the `train every` period for efficiency, so in reality, it means that each model will be trained in a staggered manner within each `train every` period.
-- `num samples to diff`: (`0`/`1`) This is a `0` or `1` to determine if you want the model to operate on differences of the raw data or just the raw data. For example, the default of `1` means that we take differences of the raw values. Using differences is more general and works on dimensions that might naturally tend to have some trends or cycles in them that is normal behavior to which we don't want to be too sensitive.
-- `num samples to smooth`: (`0`/`5`) This is a small integer that controls the amount of smoothing applied as part of the feature processing used by the model. For example, the default of `3` means that the rolling average of the last 3 values is used. Smoothing like this helps the model be a little more robust to spiky types of dimensions that naturally "jump" up or down as part of their normal behavior.
-- `num samples to lag`: (`0`/`5`) This is a small integer that determines how many lagged values of the dimension to include in the feature vector. For example, the default of `5` means that in addition to the most recent (by default, differenced and smoothed) value of the dimension, the feature vector will also include the 5 previous values too. Using lagged values in our feature representation allows the model to work over strange patterns over recent values of a dimension as opposed to just focusing on if the most recent value itself is big or small enough to be anomalous.
-- `maximum number of k-means iterations`: This is a parameter that can be passed to the model to limit the number of iterations in training the k-means model. Vast majority of cases can ignore and leave as default.
-- `dimension anomaly score threshold`: (`0.01`/`5.00`) This is the threshold at which an individual dimension at a specific timestep is considered anomalous or not. For example, the default of `0.99` means that a dimension with an anomaly score of 99% or higher is flagged as anomalous. This is a normalized probability based on the training data, so the default of 99% means that anything that is as strange (based on distance measure) or more strange as the most strange 1% of data observed during training will be flagged as anomalous. If you wanted to make the anomaly detection on individual dimensions more sensitive you could try a value like `0.90` (90%) or to make it less sensitive you could try `1.5` (150%).
-- `host anomaly rate threshold`: (`0.0`/`1.0`) This is the percentage of dimensions (based on all those enabled for anomaly detection) that need to be considered anomalous at specific timestep for the host itself to be considered anomalous. For example, the default value of `0.01` means that if more than 1% of dimensions are anomalous at the same time then the host itself is considered in an anomalous state.
-- `minimum window size`: The Netdata "Anomaly Detector" logic works over a rolling window of data. This parameter defines the minimum length of window to consider. If over this window the host is in an anomalous state then an anomaly detection event will be triggered. For example, the default of `30` means that the detector will initially work over a rolling window of 30 seconds. Note: The length of this window will be dynamic once an anomaly event has been triggered such that it will expand as needed until either the max length of an anomaly event is hit or the host settles back into a normal state with sufficiently decreased host level anomaly states in the rolling window. Note: If you wanted to adjust the higher level anomaly detector behavior then this is one parameter you might adjust to see the impact of on anomaly detection events.
-- `maximum window size`: This parameter defines the maximum length of window to consider. If an anomaly event reaches this size, it will be closed. This is to provide an upper bound on the length of an anomaly event and cost of the anomaly detector logic for that event.
-- `window minimum anomaly rate`: (`0.0`/`1.0`) This parameter corresponds to a threshold on the percentage of time in the rolling window that the host was considered in an anomalous state. For example, the default of `0.25` means that if the host is in an anomalous state for 25% of more of the rolling window then and anomaly event will be triggered or extended if one is already active. Note: If you want to make the anomaly detector itself less sensitive, you can adjust this value to something like `0.75` which would mean the host needs to be much more consistently in an anomalous state to trigger an anomaly detection event. Likewise, a lower value like `0.1` would make the anomaly detector more sensitive.
-- `anomaly event min dimension rate threshold`: (`0.0`/`1.0`) This is a parameter that helps filter out irrelevant dimensions from anomaly events. For example, the default of `0.05` means that only dimensions that were considered anomalous for at least 5% of the anomaly event itself will be included in that anomaly event. The idea here is to just include dimensions that were consistently anomalous as opposed to those that may have just randomly happened to be anomalous at the same time.
-- `hosts to skip from training`: This parameter allows you to turn off anomaly detection for any child hosts on a parent host by defining those you would like to skip from training here. For example, a value like `dev-*` skips all hosts on a parent that begin with the "dev-" prefix. The default value of `!*` means "don't skip any".
-- `charts to skip from training`: This parameter allows you to exclude certain charts from anomaly detection by defining them here. By default, all charts, apart from a specific allow list of the typical basic Netdata charts, are excluded. If you have additional charts you would like to include for anomaly detection, you can add them here. **Note**: It is recommended to add charts in small groups and then measure any impact on performance before adding additional ones.
-
-## Charts
-
-Once enabled, the "Anomaly Detection" menu and charts will be available on the dashboard.
-
-
-
-In terms of anomaly detection, the most interesting charts would be the `anomaly_detection.dimensions` and `anomaly_detection.anomaly_rate` ones, which hold the `anomalous` and `anomaly_rate` dimensions that show the overall number of dimensions considered anomalous at any time and the corresponding anomaly rate.
-
-- `anomaly_detection.dimensions`: Total count of dimensions considered anomalous or normal.
-- `anomaly_detection.dimensions`: Percentage of anomalous dimensions.
-- `anomaly_detection.detector_window`: The length of the active window used by the detector.
-- `anomaly_detection.detector_events`: Flags (0 or 1) to show when an anomaly event has been triggered by the detector.
-- `anomaly_detection.prediction_stats`: Diagnostic metrics relating to prediction time of anomaly detection.
-- `anomaly_detection.training_stats`: Diagnostic metrics relating to training time of anomaly detection.
-
-Below is an example of how these charts may look in the presence of an anomaly event.
-
-Initially we see a jump in `anomalous` dimensions:
-
-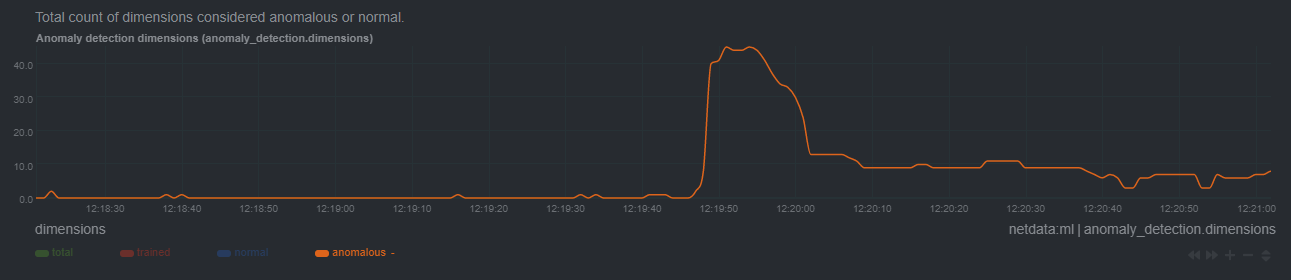
-
-And a corresponding jump in the `anomaly_rate`:
-
-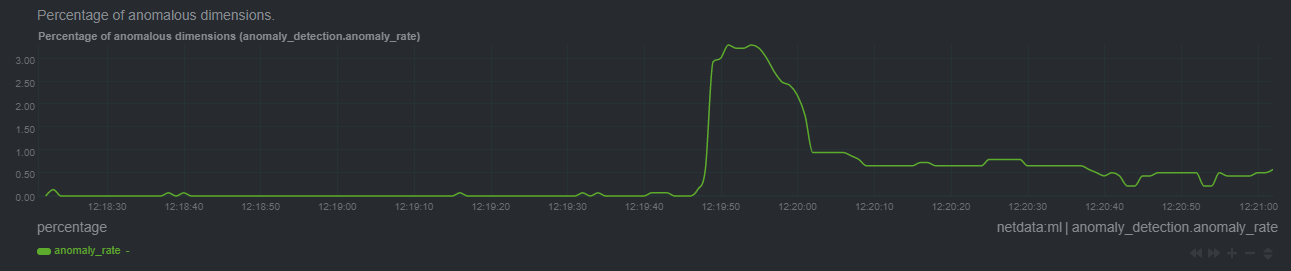
-
-After a short while the rolling node anomaly rate goes `above_threshold`, and once it stays above threshold for long enough a `new_anomaly_event` is created:
-
-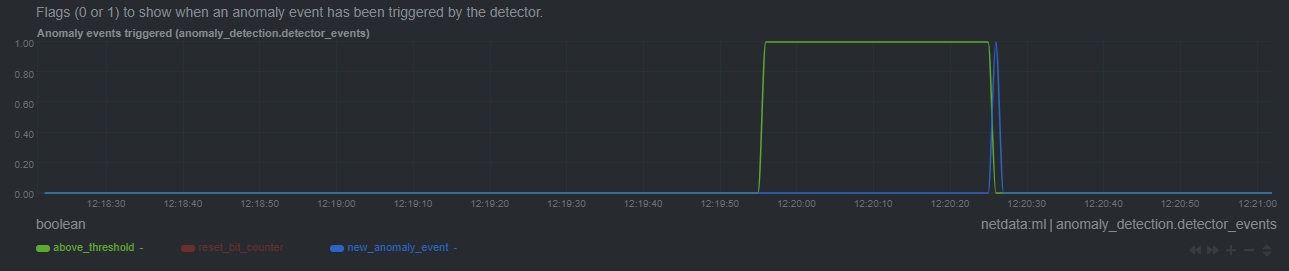
-
-## Glossary
-
-#### _feature vector_
+The fundamentals of Netdata's anomaly detection approach and implmentation are covered in lots more detail in the [agent ML documentation](/docs/agent/ml).
-A [feature vector](https://en.wikipedia.org/wiki/Feature_(machine_learning)) is what the ML model is trained on and uses for prediction. The most simple feature vector would be just the latest raw dimension value itself [x]. By default Netdata will use a feature vector consisting of the 6 latest differences and smoothed values of the dimension so conceptually something like `[avg3(diff1(x-5)), avg3(diff1(x-4)), avg3(diff1(x-3)), avg3(diff1(x-2)), avg3(diff1(x-1)), avg3(diff1(x))]` which ends up being just 6 floating point numbers that try and represent the "shape" of recent data.
+This guide will explain how to get started using these ML based anomaly detection capabilities within Netdata.
-#### _anomaly score_
+## Anomaly Advisor
-At prediction time the anomaly score is just the distance of the most recent feature vector to the trained cluster centers of the model, which are themselves just feature vectors, albeit supposedly the best most representative feature vectors that could be "learned" from the training data. So if the most recent feature vector is very far away in terms of [euclidean distance](https://en.wikipedia.org/wiki/Euclidean_distance#:~:text=In%20mathematics%2C%20the%20Euclidean%20distance,being%20called%20the%20Pythagorean%20distance.) it's more likely that the recent data it represents consists of some strange pattern not commonly found in the training data.
+The [Anomaly Advisor](/docs/cloud/insights/anomaly-advisor) is the flagship anomaly detection feature within Netdata. In the "Anomalies" tab of Netdata you will see an overall "Anomaly Rate" chart that aggregates node level anomaly rate for all nodes in a space. The aim of this chart is to make it easy to quickly spot periods of time where the overall "[node anomaly rate](/docs/agent/ml#node-anomaly-rate)" is evelated in some unusual way and for what node or nodes this relates to.
-#### _anomaly bit_
+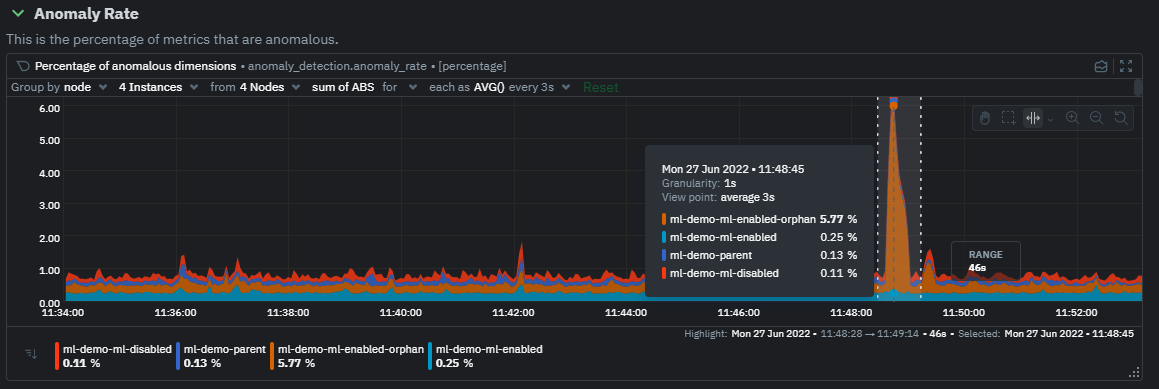
-If the anomaly score is greater than a specified threshold then the most recent feature vector, and hence most recent raw data, is considered anomalous. Since storing the raw anomaly score would essentially double amount of storage space Netdata would need, we instead efficiently store just the anomaly bit in the existing internal Netdata data representation without any additional storage overhead.
+Once an area on the Anomaly Rate chart is highlighted netdata will append a "heatmap" to the bottom of the screen that shows which metrics were more anomalous in the highlighted timeframe. Each row in the heatmap consists of an anomaly rate sparkline graph that can be expanded to reveal the raw underlying metric chart for that dimension.
-#### _anomaly rate_
+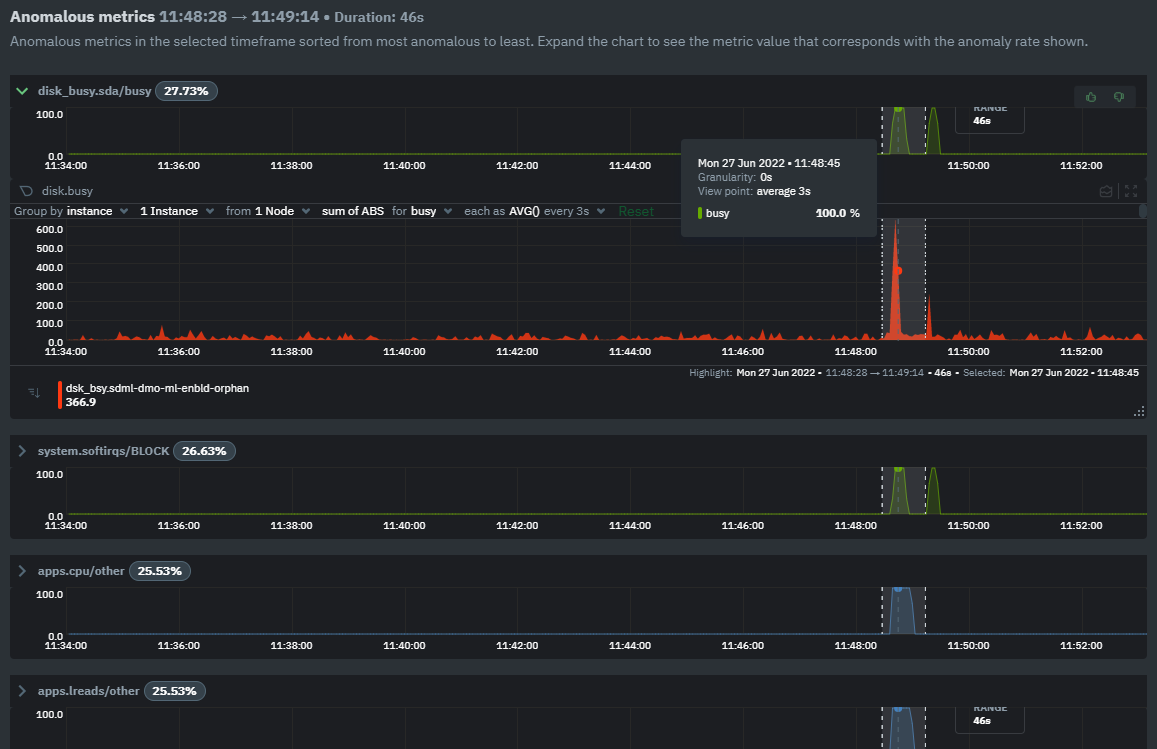
-An anomaly rate is really just an average over one or more anomaly bits. An anomaly rate can be calculated over time for one or more dimensions or at a point in time across multiple dimensions, or some combination of the two. Its just an average of some collection of anomaly bits.
+## Embedded Anomaly Rate Charts
-#### _anomaly detector_
+Charts in both the [Overview](/docs/cloud/visualize/overview) and [single node dashboard](/docs/cloud/visualize/overview#jump-to-single-node-dashboards) tabs also expose the underlying anomaly rates for each dimension so users can easily see if the raw metrics are considered anomalous or not by Netdata.
-The is essentially business logic that just tries to process a collection of anomaly bits to determine if there is enough active anomaly bits to merit investigation or declaration of a node level anomaly event.
+Pressing the anomalies icon (next to the information icon in the chart header) will expand the anomaly rate chart to make it easy to see how the anomaly rate for any individual dimension corresponds to the raw underlying data. In the example below we can see that the spike in `system.pgpgio|in` corresponded in the anomaly rate for that dimension jumping to 100% for a small period of time until the spike passed.
-#### _anomaly event_
+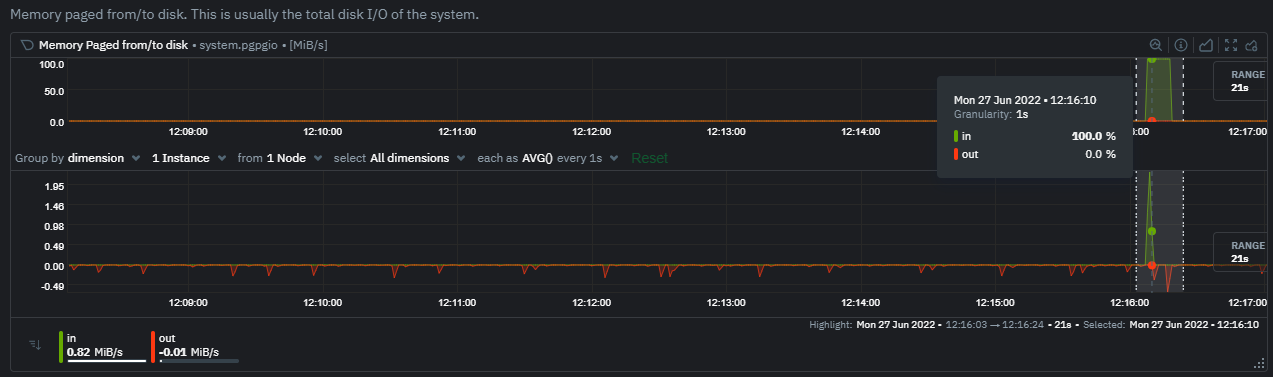
-Anomaly events are triggered by the anomaly detector and represent a window of time on the node with sufficiently elevated anomaly rates across all dimensions.
+## Anomaly Rate Based Alerts
-#### _dimension anomaly rate_
+It is possible to use the `anomaly-bit` when defining traditional Alerts within netdata. The `anomaly-bit` is just another `options` parameter that can be passed as part of an [alarm line lookup](/docs/agent/health/reference#alarm-line-lookup).
-The anomaly rate of a specific dimension over some window of time.
+You can see some example ML based alert configurations below:
-#### _node anomaly rate_
+- [Anomaly rate based CPU dimensions alarm](/docs/agent/health/reference#example-8---anomaly-rate-based-cpu-dimensions-alarm)
+- [Anomaly rate based CPU chart alarm](/docs/agent/health/reference#example-9---anomaly-rate-based-cpu-chart-alarm)
+- [Anomaly rate based node level alarm](/docs/agent/health/reference#example-10---anomaly-rate-based-node-level-alarm)
+- More examples in the [`/health/health.d/ml.conf`](https://github.com/netdata/netdata/blob/master/health/health.d/ml.conf) file that ships with the agent.
-The anomaly rate across all dimensions of a node.
+## Learn More
-## Notes
+Check out the resources below to learn more about how Netdata is approaching ML:
-- We would love to hear any feedback relating to this functionality, please email us at analytics-ml-team@netdata.cloud or come join us in the [🤖-ml-powered-monitoring](https://discord.gg/4eRSEUpJnc) channel of the Netdata discord.
-- We are working on additional UI/UX based features that build on these core components to make them as useful as possible out of the box.
-- Although not yet a core focus of this work, users could leverage the `anomaly_detection` chart dimensions and/or `anomaly-bit` options in defining alarms based on ML driven anomaly detection models.
-- [This presentation](https://docs.google.com/presentation/d/18zkCvU3nKP-Bw_nQZuXTEa4PIVM6wppH3VUnAauq-RU/edit?usp=sharing) walks through some of the main concepts covered above in a more informal way.
-- After restart Netdata will wait until `minimum num samples to train` observations of data are available before starting training and prediction.
-- Netdata uses [dlib](https://github.com/davisking/dlib) under the hood for its core ML features.
-- You should benchmark Netdata resource usage before and after enabling ML. Typical overhead ranges from 1-2% additional CPU at most.
-- The "anomaly bit" has been implemented to be a building block to underpin many more ML based use cases that we plan to deliver soon.
-- At its core Netdata uses an approach and problem formulation very similar to the Netdata python [anomalies collector](/docs/agent/collectors/python.d.plugin/anomalies), just implemented in a much much more efficient and scalable way in the agent in c++. So if you would like to learn more about the approach and are familiar with Python that is a useful resource to explore, as is the corresponding [deep dive tutorial](https://nbviewer.org/github/netdata/community/blob/main/netdata-agent-api/netdata-pandas/anomalies_collector_deepdive.ipynb) where the default model used is PCA instead of K-Means but the overall approach and formulation is similar.
\ No newline at end of file
+- [Agent ML documentation](/docs/agent/ml).
+- [Anomaly Advisor documentation](/docs/cloud/insights/anomaly-advisor).
+- [Metric Correlations documentation](/docs/cloud/insights/metric-correlations).
+- Anomaly Advisor [launch blog post](https://www.netdata.cloud/blog/introducing-anomaly-advisor-unsupervised-anomaly-detection-in-netdata/).
+- Netdata Approach to ML [blog post](https://www.netdata.cloud/blog/our-approach-to-machine-learning/).
+- `areal/ml` related [GitHub Discussions](https://github.com/netdata/netdata/discussions?discussions_q=label%3Aarea%2Fml).
+- Netdata Machine Learning Meetup [deck](https://docs.google.com/presentation/d/1rfSxktg2av2k-eMwMbjN0tXeo76KC33iBaxerYinovs/edit?usp=sharing) and [YouTube recording](https://www.youtube.com/watch?v=eJGWZHVQdNU).
+- Netdata Anomaly Advisor [YouTube Playlist](https://youtube.com/playlist?list=PL-P-gAHfL2KPeUcCKmNHXC-LX-FfdO43j).
diff --git a/guides/troubleshoot/troubleshooting-agent-with-cloud-connection.md b/guides/troubleshoot/troubleshooting-agent-with-cloud-connection.md
new file mode 100644
index 000000000..ae92e1751
--- /dev/null
+++ b/guides/troubleshoot/troubleshooting-agent-with-cloud-connection.md
@@ -0,0 +1,117 @@
+---
+title: "Troubleshoot Agent-Cloud connectivity issues"
+description: "A simple guide to troubleshoot occurrences where the Agent is showing as offline after claiming."
+custom_edit_url: https://github.com/netdata/netdata/edit/master/guides/troubleshoot/troubleshooting-agent-with-cloud-connection.md
+---
+
+
+
+When you are claiming a node, you might not be able to immediately see it online in Netdata Cloud.
+This could be due to an error in the claiming process or a temporary outage of some services.
+
+We identified some scenarios that might cause this delay and possible actions you could take to overcome each situation.
+
+The most common explanation for the delay usually falls into one of the following three categories:
+
+- [The claiming process of the kickstart script was unsuccessful](#the-claiming-process-of-the-kickstart-script-was-unsuccessful)
+- [Claiming on an older, deprecated version of the Agent](#claiming-on-an-older-deprecated-version-of-the-agent)
+- [Network issues while connecting to the Cloud](#network-issues-while-connecting-to-the-cloud)
+
+## The claiming process of the kickstart script was unsuccessful
+
+Here, we will try to define some edge cases you might encounter when claiming a node.
+
+### The kickstart script auto-claimed the Agent but there was no error message displayed
+
+The kickstart script will install/update your Agent and then try to claim the node to the Cloud (if tokens are provided). To
+complete the second part, the Agent must be running. In some platforms, the Netdata service cannot be enabled by default
+and you must do it manually, using the following steps:
+
+1. Check if the Agent is running:
+
+ ```bash
+ systemctl status netdata
+ ```
+
+ The expected output should contain info like this:
+
+ ```bash
+ Active: active (running) since Wed 2022-07-06 12:25:02 EEST; 1h 40min ago
+ ```
+
+2. Enable and start the Netdata Service.
+
+ ```bash
+ systemctl enable netdata
+ systemctl start netdata
+ ```
+
+3. Retry the kickstart claiming process.
+
+:::note
+
+In some cases a simple restart of the Agent can fix the issue.
+Read more about [Starting, Stopping and Restarting the Agent](/docs/configure/start-stop-restart).
+
+:::
+
+## Claiming on an older, deprecated version of the Agent
+
+Make sure that you are using the latest version of Netdata if you are using the [Claiming script](/docs/agent/claim#claiming-script).
+
+With the introduction of our new architecture, Agents running versions lower than `v1.32.0` can face claiming problems, so we recommend you [update the Netdata Agent](/docs/agent/packaging/installer/update) to the latest stable version.
+
+## Network issues while connecting to the Cloud
+
+### Verify that your IP is whitelisted from Netdata Cloud
+
+Most of the nodes change IPs dynamically. It is possible that your current IP has been restricted from accessing `app.netdata.cloud` due to security concerns.
+
+To verify this:
+
+1. Check the Agent's `aclk-state`.
+
+ ```bash
+ sudo netdatacli aclk-state | grep "Banned By Cloud"
+ ```
+
+ The output will contain a line indicating if the IP is banned from `app.netdata.cloud`:
+
+ ```bash
+ Banned By Cloud: yes
+ ```
+
+2. If your node's IP is banned, you can:
+
+ - Contact our team to whitelist your IP by submitting a ticket in the [Netdata forum](https://community.netdata.cloud/)
+ - Change your node's IP
+
+### Make sure that your node has internet connectivity and can resolve network domains
+
+1. Try to reach a well known host:
+
+ ```bash
+ ping 8.8.8.8
+ ```
+
+2. If you can reach external IPs, then check your domain resolution.
+
+ ```bash
+ host app.netdata.cloud
+ ```
+
+ The expected output should be something like this:
+
+ ```bash
+ app.netdata.cloud is an alias for main-ingress-545609a41fcaf5d6.elb.us-east-1.amazonaws.com.
+ main-ingress-545609a41fcaf5d6.elb.us-east-1.amazonaws.com has address 54.198.178.11
+ main-ingress-545609a41fcaf5d6.elb.us-east-1.amazonaws.com has address 44.207.131.212
+ main-ingress-545609a41fcaf5d6.elb.us-east-1.amazonaws.com has address 44.196.50.41
+ ```
+
+ :::info
+
+ There will be cases in which the firewall restricts network access. In those cases, you need to whitelist the `app.netdata.cloud` domain to be able to see your nodes in Netdata Cloud.
+ If you can't whitelist domains in your firewall, you can whitelist the IPs that the above command will produce, but keep in mind that they can change without any notice.
+
+ :::