diff --git a/docs/benchmarks.md b/docs/benchmarks.md
index 0fe82e5..d9319c5 100644
--- a/docs/benchmarks.md
+++ b/docs/benchmarks.md
@@ -5,44 +5,104 @@ hide:
# Benchmarks
-## Large Language Models (LLM)
+!!! admonition "WIP - Updating Results"
-
+ Below is recent data from the Jetson Orin Nano Super benchmarks - see [here](https://developer.nvidia.com/blog/nvidia-jetson-orin-nano-developer-kit-gets-a-super-boost/?ncid=so-othe-293081-vt48) for more info.
-For running LLM benchmarks, see the [`MLC`](https://github.com/dusty-nv/jetson-containers/tree/master/packages/llm/mlc) container documentation.
+ Currently in the process of collating these across AGX Orin and Orin NX - for now, the previous results are archived [below](#large-language-models-llm).
-## Small Language Models (SLM)
+#### Jetson Orin Nano Super
-
+=== "LLM / SLM"
-Small language models are generally defined as having fewer than 7B parameters *(Llama-7B shown for reference)*
-For more data and info about running these models, see the [`SLM`](tutorial_slm.md) tutorial and [`MLC`](https://github.com/dusty-nv/jetson-containers/tree/master/packages/llm/mlc) container documentation.
+
-## Vision Language Models (VLM)
+ | Model | Jetson Orin Nano (original) | Jetson Orin Nano Super | Perf Gain (X) |
+ |--------------|:---------------------------:|:----------------------:|:-------------:|
+ | Llama 3.1 8B | 14 | 19.14 | 1.37 |
+ | Llama 3.2 3B | 27.7 | 43.07 | 1.55 |
+ | Qwen2.5 7B | 14.2 | 21.75 | 1.53 |
+ | Gemma 2 2B | 21.5 | 34.97 | 1.63 |
+ | Gemma 2 9B | 7.2 | 9.21 | 1.28 |
+ | Phi 3.5 3B | 24.7 | 38.1 | 1.54 |
+ | SmolLM2 | 41 | 64.5 | 1.57 |
-
+ For running these benchmarks, this [script](https://github.com/dusty-nv/jetson-containers/blob/master/packages/llm/mlc/benchmark.sh) will launch a series of containers that download/build/run the models with MLC and INT4 quantization.
-This measures the end-to-end pipeline performance for continuous streaming like with [Live Llava](tutorial_live-llava.md).
-For more data and info about running these models, see the [`NanoVLM`](tutorial_nano-vlm.md) tutorial.
+ ```
+ git clone https://github.com/dusty-nv/jetson-containers
+ bash jetson-containers/install.sh
+ bash jetson-containers/packages/llm/mlc/benchmarks.sh
+ ```
-## Vision Transformers (ViT)
+=== "Vision / Language Models"
-
+
-VIT performance data from [[1]](https://github.com/mit-han-lab/efficientvit#imagenet) [[2]](https://github.com/NVIDIA-AI-IOT/nanoowl#performance) [[3]](https://github.com/NVIDIA-AI-IOT/nanosam#performance)
+ | Model | Jetson Orin Nano (original) | Jetson Orin Nano Super | Perf Gain (X) |
+ |----------------|:---------------------------:|:----------------------:|:-------------:|
+ | VILA 1.5 3B | 0.7 | 1.06 | 1.51 |
+ | VILA 1.5 8B | 0.574 | 0.83 | 1.45 |
+ | LLAVA 1.6 7B | 0.412 | 0.57 | 1.38 |
+ | Qwen2 VL 2B | 2.8 | 4.4 | 1.57 |
+ | InternVL2.5 4B | 2.5 | 5.1 | 2.04 |
+ | PaliGemma2 3B | 13.7 | 21.6 | 1.58 |
+ | SmolVLM 2B | 8.1 | 12.9 | 1.59 |
-## Stable Diffusion
+=== "Vision Transformers"
-
+
-## Riva
+ | Model | Jetson Orin Nano (original) | Jetson Orin Nano Super | Perf Gain (X) |
+ |-----------------------|:---------------------------:|:----------------------:|:-------------:|
+ | clip-vit-base-patch32 | 196 | 314 | 1.60 |
+ | clip-vit-base-patch16 | 95 | 161 | 1.69 |
+ | DINOv2-base-patch14 | 75 | 126 | 1.68 |
+ | SAM2 base | 4.42 | 6.34 | 1.43 |
+ | Grounding DINO | 4.11 | 6.23 | 1.52 |
+ | vit-base-patch16-224 | 98 | 158 | 1.61 |
+ | vit-base-patch32-224 | 171 | 273 | 1.60 |
-
+#### Jetson AGX Orin
-For running Riva benchmarks, see [ASR Performance](https://docs.nvidia.com/deeplearning/riva/user-guide/docs/asr/asr-performance.html) and [TTS Performance](https://docs.nvidia.com/deeplearning/riva/user-guide/docs/tts/tts-performance.html).
+=== "Large Language Models (LLM)"
-## Vector Database
+ 
-
+ For running LLM benchmarks, see the [`MLC`](https://github.com/dusty-nv/jetson-containers/tree/master/packages/llm/mlc) container documentation.
-For running vector database benchmarks, see the [`NanoDB`](https://github.com/dusty-nv/jetson-containers/tree/master/packages/vectordb/nanodb) container documentation.
+=== "Small Language Models (SLM)"
+
+ 
+
+ Small language models are generally defined as having fewer than 7B parameters *(Llama-7B shown for reference)*
+ For more data and info about running these models, see the [`SLM`](tutorial_slm.md) tutorial and [`MLC`](https://github.com/dusty-nv/jetson-containers/tree/master/packages/llm/mlc) container documentation.
+
+=== "Vision Language Models (VLM)"
+
+ 
+
+ This measures the end-to-end pipeline performance for continuous streaming like with [Live Llava](tutorial_live-llava.md).
+ For more data and info about running these models, see the [`NanoVLM`](tutorial_nano-vlm.md) tutorial.
+
+=== "Vision Transformers (ViT)"
+
+ 
+
+ VIT performance data from [[1]](https://github.com/mit-han-lab/efficientvit#imagenet) [[2]](https://github.com/NVIDIA-AI-IOT/nanoowl#performance) [[3]](https://github.com/NVIDIA-AI-IOT/nanosam#performance)
+
+=== "Stable Diffusion"
+
+ 
+
+=== "Riva"
+
+ 
+
+ For running Riva benchmarks, see [ASR Performance](https://docs.nvidia.com/deeplearning/riva/user-guide/docs/asr/asr-performance.html) and [TTS Performance](https://docs.nvidia.com/deeplearning/riva/user-guide/docs/tts/tts-performance.html).
+
+=== "Vector Database"
+
+ 
+
+ For running vector database benchmarks, see the [`NanoDB`](https://github.com/dusty-nv/jetson-containers/tree/master/packages/vectordb/nanodb) container documentation.
diff --git a/docs/overrides/main.html b/docs/overrides/main.html
index cc19648..456d4be 100644
--- a/docs/overrides/main.html
+++ b/docs/overrides/main.html
@@ -2,20 +2,19 @@
{% extends "base.html" %}
-{#
{% block announce %}
-
⛄❄️ Jetson Orin Nano Super now available for $249 (up to 1.7X gains through JetPack update, see our blog for more info)
{% endblock %}
-#}
+
{% block scripts %}
diff --git a/docs/research.md b/docs/research.md
index 850636b..2e9485f 100644
--- a/docs/research.md
+++ b/docs/research.md
@@ -10,9 +10,11 @@ The Jetson AI Lab Research Group is a global collective for advancing open-sourc
There are virtual [meetings](#meeting-schedule) that anyone is welcome to join, offline discussion on the [Jetson Projects](https://forums.developer.nvidia.com/c/agx-autonomous-machines/jetson-embedded-systems/jetson-projects/78){:target="_blank"} forum, and guidelines for upstreaming open-source [contributions](#contribution-guidelines).
-!!! abstract "Next Meeting - 12/10"
+!!! abstract "Next Meeting - 1/7"
- The next team meeting is on Tuesday, December 10th at 9am PST - see the [invite](#meeting-schedule) below or click [here](https://teams.microsoft.com/l/meetup-join/19%3ameeting_NTA4ZmE4MDAtYWUwMS00ZTczLWE0YWEtNTE5Y2JkNTFmOWM1%40thread.v2/0?context=%7b%22Tid%22%3a%2243083d15-7273-40c1-b7db-39efd9ccc17a%22%2c%22Oid%22%3a%221f165bb6-326c-4610-b292-af9159272b08%22%7d){:target="_blank"} to join the meeting in progress.
+ With holiday schedules soon taking effect, we will reconvene in 2025 - thank you everyone for an amazing year!
+ In the meantime, enjoy the time with your families, and feel welcome to keep in touch through the forums, Discord, or LinkedIn.
+ The next team meeting is on Tuesday, January 7th at 9am PST - see the [invite](#meeting-schedule) below or click [here](https://teams.microsoft.com/l/meetup-join/19%3ameeting_NTA4ZmE4MDAtYWUwMS00ZTczLWE0YWEtNTE5Y2JkNTFmOWM1%40thread.v2/0?context=%7b%22Tid%22%3a%2243083d15-7273-40c1-b7db-39efd9ccc17a%22%2c%22Oid%22%3a%221f165bb6-326c-4610-b292-af9159272b08%22%7d){:target="_blank"} to join the meeting in progress.
## Topics of Interest
@@ -75,7 +77,7 @@ Ongoing technical discussions are encouraged to occur on the forums or GitHub Is
We'll aim to meet monthly or bi-weekly as a team in virtual meetings that anyone is welcome to join and speak during. We'll discuss the latest updates and experiments that we want to explore. Please remain courteous to others during the calls. We'll stick around after for anyone who has questions or didn't get the chance to be heard.
-!!! abstract "Tuesday December 10th at 9am PST (12/10/24)"
+!!! abstract "Tuesday January 7th at 9am PST (1/7/24)"
- Microsoft Teams - [Meeting Link](https://teams.microsoft.com/l/meetup-join/19%3ameeting_NTA4ZmE4MDAtYWUwMS00ZTczLWE0YWEtNTE5Y2JkNTFmOWM1%40thread.v2/0?context=%7b%22Tid%22%3a%2243083d15-7273-40c1-b7db-39efd9ccc17a%22%2c%22Oid%22%3a%221f165bb6-326c-4610-b292-af9159272b08%22%7d){:target="_blank"}
- Meeting ID: `264 770 145 196`
@@ -100,6 +102,14 @@ The agenda will be listed here beforehand - post to the forum to add agenda item
## Past Meetings
+Recordings Archive
+
+
Due to a backlog of editing/posting the previous meetings, here is a link containing the raw footage:
+
+
 -## Vision Language Models (VLM)
+ | Model | Jetson Orin Nano (original) | Jetson Orin Nano Super | Perf Gain (X) |
+ |--------------|:---------------------------:|:----------------------:|:-------------:|
+ | Llama 3.1 8B | 14 | 19.14 | 1.37 |
+ | Llama 3.2 3B | 27.7 | 43.07 | 1.55 |
+ | Qwen2.5 7B | 14.2 | 21.75 | 1.53 |
+ | Gemma 2 2B | 21.5 | 34.97 | 1.63 |
+ | Gemma 2 9B | 7.2 | 9.21 | 1.28 |
+ | Phi 3.5 3B | 24.7 | 38.1 | 1.54 |
+ | SmolLM2 | 41 | 64.5 | 1.57 |
-
+ For running these benchmarks, this [script](https://github.com/dusty-nv/jetson-containers/blob/master/packages/llm/mlc/benchmark.sh) will launch a series of containers that download/build/run the models with MLC and INT4 quantization.
-This measures the end-to-end pipeline performance for continuous streaming like with [Live Llava](tutorial_live-llava.md).
-For more data and info about running these models, see the [`NanoVLM`](tutorial_nano-vlm.md) tutorial.
+ ```
+ git clone https://github.com/dusty-nv/jetson-containers
+ bash jetson-containers/install.sh
+ bash jetson-containers/packages/llm/mlc/benchmarks.sh
+ ```
-## Vision Transformers (ViT)
+=== "Vision / Language Models"
-
+
-## Vision Language Models (VLM)
+ | Model | Jetson Orin Nano (original) | Jetson Orin Nano Super | Perf Gain (X) |
+ |--------------|:---------------------------:|:----------------------:|:-------------:|
+ | Llama 3.1 8B | 14 | 19.14 | 1.37 |
+ | Llama 3.2 3B | 27.7 | 43.07 | 1.55 |
+ | Qwen2.5 7B | 14.2 | 21.75 | 1.53 |
+ | Gemma 2 2B | 21.5 | 34.97 | 1.63 |
+ | Gemma 2 9B | 7.2 | 9.21 | 1.28 |
+ | Phi 3.5 3B | 24.7 | 38.1 | 1.54 |
+ | SmolLM2 | 41 | 64.5 | 1.57 |
-
+ For running these benchmarks, this [script](https://github.com/dusty-nv/jetson-containers/blob/master/packages/llm/mlc/benchmark.sh) will launch a series of containers that download/build/run the models with MLC and INT4 quantization.
-This measures the end-to-end pipeline performance for continuous streaming like with [Live Llava](tutorial_live-llava.md).
-For more data and info about running these models, see the [`NanoVLM`](tutorial_nano-vlm.md) tutorial.
+ ```
+ git clone https://github.com/dusty-nv/jetson-containers
+ bash jetson-containers/install.sh
+ bash jetson-containers/packages/llm/mlc/benchmarks.sh
+ ```
-## Vision Transformers (ViT)
+=== "Vision / Language Models"
-
+  -VIT performance data from [[1]](https://github.com/mit-han-lab/efficientvit#imagenet) [[2]](https://github.com/NVIDIA-AI-IOT/nanoowl#performance) [[3]](https://github.com/NVIDIA-AI-IOT/nanosam#performance)
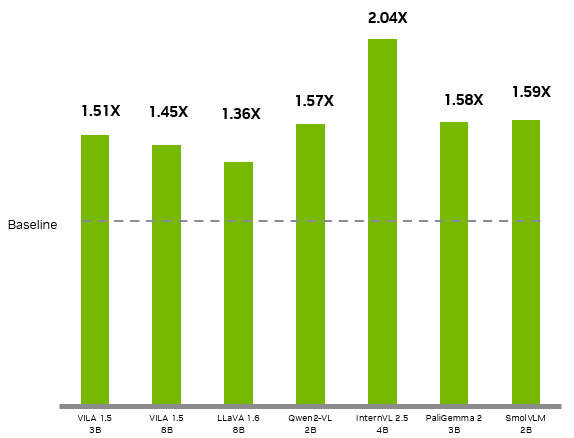
+ | Model | Jetson Orin Nano (original) | Jetson Orin Nano Super | Perf Gain (X) |
+ |----------------|:---------------------------:|:----------------------:|:-------------:|
+ | VILA 1.5 3B | 0.7 | 1.06 | 1.51 |
+ | VILA 1.5 8B | 0.574 | 0.83 | 1.45 |
+ | LLAVA 1.6 7B | 0.412 | 0.57 | 1.38 |
+ | Qwen2 VL 2B | 2.8 | 4.4 | 1.57 |
+ | InternVL2.5 4B | 2.5 | 5.1 | 2.04 |
+ | PaliGemma2 3B | 13.7 | 21.6 | 1.58 |
+ | SmolVLM 2B | 8.1 | 12.9 | 1.59 |
-## Stable Diffusion
+=== "Vision Transformers"
-
+
-VIT performance data from [[1]](https://github.com/mit-han-lab/efficientvit#imagenet) [[2]](https://github.com/NVIDIA-AI-IOT/nanoowl#performance) [[3]](https://github.com/NVIDIA-AI-IOT/nanosam#performance)
+ | Model | Jetson Orin Nano (original) | Jetson Orin Nano Super | Perf Gain (X) |
+ |----------------|:---------------------------:|:----------------------:|:-------------:|
+ | VILA 1.5 3B | 0.7 | 1.06 | 1.51 |
+ | VILA 1.5 8B | 0.574 | 0.83 | 1.45 |
+ | LLAVA 1.6 7B | 0.412 | 0.57 | 1.38 |
+ | Qwen2 VL 2B | 2.8 | 4.4 | 1.57 |
+ | InternVL2.5 4B | 2.5 | 5.1 | 2.04 |
+ | PaliGemma2 3B | 13.7 | 21.6 | 1.58 |
+ | SmolVLM 2B | 8.1 | 12.9 | 1.59 |
-## Stable Diffusion
+=== "Vision Transformers"
-
+