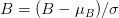diff --git "a/35_\354\274\200\353\235\274\354\212\244\353\245\274 \354\235\264\354\232\251\355\225\234 \353\213\244\354\244\221 \353\235\274\353\262\250 \353\266\204\353\245\230.md" "b/35_\354\274\200\353\235\274\354\212\244\353\245\274 \354\235\264\354\232\251\355\225\234 \353\213\244\354\244\221 \353\235\274\353\262\250 \353\266\204\353\245\230.md"
deleted file mode 100644
index db3fc42..0000000
--- "a/35_\354\274\200\353\235\274\354\212\244\353\245\274 \354\235\264\354\232\251\355\225\234 \353\213\244\354\244\221 \353\235\274\353\262\250 \353\266\204\353\245\230.md"
+++ /dev/null
@@ -1,830 +0,0 @@
-## 케라스를 이용한 다중 라벨 분류(Multi-label classification with Keras)
-[원문 링크](https://www.pyimagesearch.com/2018/05/07/multi-label-classification-with-keras/)
-> 본 튜토리얼에서는 하나의 CNN을 사용해 옷의 종류와 색을 동시에 분류하는 다중 라벨 분류(multi-label classification)를 다룹니다. 다중 클래스 분류(multi-class classification)와 비교해 어떻게 다른지, 어떻게 구현할 수 있는지 알아봅시다.
-
-* Keras
-* CNN
-* Multi-label
-* Classification
-
-----
-
-해당 튜토리얼은 총 네 부분으로 나뉩니다.
-
-첫 번째 파트에서는 다중 라벨 분류를 위한 데이터 세트(그리고 빠르게 자신만의 데이터 세트를 구축하는 법)에 대해 알아봅니다.
-
-두 번째 파트에서는 다중 라벨 분류를 위해 사용할 케라스 신경망 아키텍처인 `소형VGGNet`에 대해 알아본 후,
-해당 신경망을 구현해 봅니다.
-
-세 번째 파트에서는 직접 구현한 `소형VGGNet`을 다중 라벨 데이터 세트에 대해 학습시켜 봅니다.
-
-마지막으로 학습된 신경망을 예시 이미지들에 대해 테스트 해보는 것으로 본 튜토리얼을 마무리하고,
-다중 라벨 분석이 필요한 경우, 그리고 이 때 주의해야 할 점 몇가지를 알아보도록 하겠습니다.
-
-### 다중 라벨 분류를 위한 데이터 세트
-
-
-
-데이터 세트 다음을 포함하여 총 6개 범주에 걸쳐 2,167개의 이미지들로 구성됩니다.
-* 검정색 청바지 (344개의 이미지)
-* 파란색 드레스 (386개의 이미지)
-* 파란색 청바지 (356개의 이미지)
-* 파란색 셔츠 (369개의 이미지)
-* 빨간색 드레스 (380개의 이미지)
-* 빨간색 셔츠 (332개의 이미지)
-
-***다중 라벨 분류의 목표는 옷의 종류와 색을 모두 예측하는 모델을 만드는 것입니다***
-
-본 튜토리얼에서 사용하는 데이터 세트는 [*해당 튜토리얼*](https://www.pyimagesearch.com/2018/04/09/how-to-quickly-build-a-deep-learning-image-dataset/)을 참고하여 만들었으며, 이미지들을 다운로드하고 6개의 클래스 각각에 대해 관련 없는 이미지들을 수동으로 제거하는 과정에는 약 30분의 시간이 걸립니다.
-
-자체적으로 딥러닝을 위한 이미지 데이터 세트를 구축하려고 한다면 위에 링크된 튜토리얼은 아주 좋은 시작점이 될 것입니다.
-
-### 다중 라벨 분류 프로젝트 구조
-원문의 "다운로드" 섹션에서 코드와 파일들을 다운로드 할 수 있습니다.
-zip 파일을 추출하면 다음과 같은 디렉토리 구조가 표시됩니다.
-
- ├── classify.py
- ├── dataset
- │ ├── black_jeans [344 entries]
- │ ├── blue_dress [386 entries]
- │ ├── blue_jeans [356 entries]
- │ ├── blue_shirt [369 entries]
- │ ├── red_dress [380 entries]
- │ └── red_shirt [332 entries]
- ├── examples
- │ ├── example_01.jpg
- │ ├── example_02.jpg
- │ ├── example_03.jpg
- │ ├── example_04.jpg
- │ ├── example_05.jpg
- │ ├── example_06.jpg
- │ └── example_07.jpg
- ├── fashion.model
- ├── mlb.pickle
- ├── plot.png
- ├── pyimagesearch
- │ ├── __init__.py
- │ └── smallervggnet.py
- ├── search_bing_api.py
- └── train.py
-
-zip 루트에는 6개의 파일들과 3개의 디렉토리들이 표시됩니다. 이 문서에서 다루는 중요한 파일들은 다음과 같습니다.
-
-1. `search_bing_api.py` : 이 스크립트를 사용하여 딥러닝 학습 이미지 데이터 세트를 [빠르게 구축할 수 있습니다](https://www.pyimagesearch.com/2018/04/09/how-to-quickly-build-a-deep-learning-image-dataset/).
-하지만 이미지 데이터 세트가 이미 zip 아카이브에 포함되어 있으므로 이 스크립트를 실행할 필요는 없습니다. 해당 코드는 프로젝트의 완결성을 위해서 추가되었습니다.
-2. `train.py` : 데이터가 모이면, 해당 스크립트를 사용하여 모델을 학습시킵니다.
-3. `fashion.model` : `train.py`에 의해 디스크에 저장된 모델 객체입니다. 후에 `classify.py`스크립트에서 사용하게 됩니다.
-4. `mlb.pickle` : `train.py`에서 생성된 파일로 `scikit-learn`의 `MultiLabelBinarizer` 객체입니다. 해당 파일은 데이터의 범주 이름들을 저장하고 있습니다.
-5. `plot.png` : `plot.png`는 학습의 결과로 `train.py`에서 생성됩니다. 자체적으로 구축한 데이터 세트에 대해 학습을 진행하는 경우, 해당 파일을 통해 과적합 여부를 확인해 보는게 좋습니다.
-6. `classify.py` : 분류기를 테스트하기 위한 스크립트입니다. 다른 곳에(아이폰 딥러닝 앱이나 라즈베리 파이 딥러닝 프로젝트 같은) 모델을 배포하기 전에는 항상 로컬에서 테스트를 거치는 것이 좋습니다.
-
-프로젝트의 세 가지 디렉토리들은 다음과 같습니다.
-
-1. `dataset` : 이 디렉토리는 이미지 데이터 세트를 저장하고 있으며, 각 범주마다 고유의 하위 디렉토리가 있습니다. 이 작업을 통해 (1) 데이터 세트의 구조를 정돈할 수 있으며 (2) 주어진 이미지 경로가 속한 범주의 이름을 쉽게 추출할 수 있습니다.
-2. `pyimagesearch` : `pyimagesearch`는 케라스 신경망을 포함하는 모듈입니다. `__init__.py` 파일은 해당 디렉토리를 모듈로 관리하기 위하여 존재합니다. 또 다른 파일인 `smallervggnet.py`는 신경망 모델을 만들기 위한 코드를 포함하고 있습니다.
-3. `examples` : 이 디렉토리에는 7개의 예제 이미지들이 있습니다. 각각의 이미지에 대해 `classify.py`를 사용하여 다중 라벨 분류를 진행하게 될 것입니다.
-
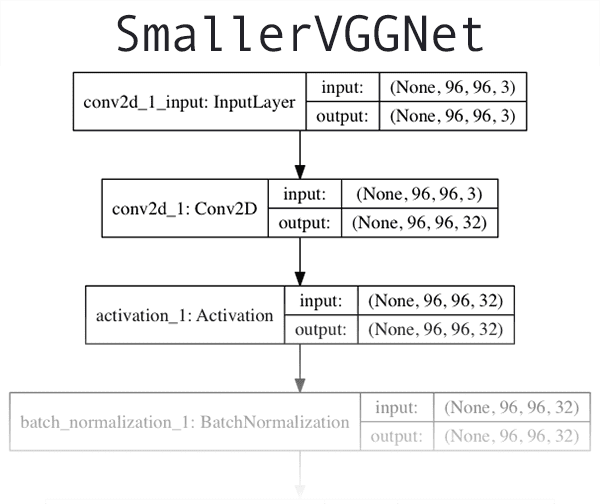
-### 다중 라벨 분류를 위한 케라스 신경망 아키텍처
-
-
-
-본 튜토리얼에서 사용하고 있는 CNN 아키텍처인 `소형VGGNet`은 `VGGNet`의 단순화된 버전입니다. `VGGNet`모델은 2014년 Simonyan과 Zisserman의 논문 [***Very Deep Convolutional Networks for Large Scale Image Recognition***](https://arxiv.org/pdf/1409.1556/)에서 처음 소개되었습니다.
-
-`소형VGGNet`의 아키텍처/코드에 대한 자세한 설명은 [***이 포스트***](https://www.pyimagesearch.com/2018/04/16/keras-and-convolutional-neural-networks-cnns/)에서 다루고 있습니다. 만약 자체적으로 모델을 디자인하고 싶다면 [***Deep Learning for Computer Vision with Python***](https://www.pyimagesearch.com/deep-learning-computer-vision-python-book/) 책을 참조해 보는 것도 좋습니다.
-
-앞서 코드와 파일들을 다운로드 받았다면, `pyimagesearch`모듈의 `smallervggnet.py`파일을 살펴보도록 하겠습니다.
-
-```python
-# 필요한 패키지들을 가져옵니다
-from keras.models import Sequential
-from keras.layers.normalization import BatchNormalization
-from keras.layers.convolutional import Conv2D
-from keras.layers.convolutional import MaxPooling2D
-from keras.layers.core import Activation
-from keras.layers.core import Flatten
-from keras.layers.core import Dropout
-from keras.layers.core import Dense
-from keras import backend as K
-```
-
-먼저 관련 케라스 모듈을 가져온 다음, `소형VGGNet` 클래스를 정의합니다.
-
-```python
-class SmallerVGGNet:
- @staticmethod
- def build(width, height, depth, classes, finalAct="softmax"):
- # 인풋 이미지의 차원과, 채널에 해당하는 축을 설정하여 모델을 초기화합니다
- # "channels_last"는 채널의 축이 마지막에 오는 것을 의미합니다
- model = Sequential()
- inputShape = (height, width, depth)
- chanDim = -1
-
- # 만약 "channels_first"를 사용한다면, 인풋 이미지의 차원을
- # 그에 맞게 바꿔줍니다
- if K.image_data_format() == "channels_first":
- inputShape = (depth, height, width)
- chanDim = 1
-```
-
-모델의 정의부입니다. `build` 함수를 통해 CNN모델을 만들 수 있습니다.
-
-`build` 함수는 `width`, `height`, `depth`, `classes`의 총 네 가지 입력변수를 필요로 합니다.
-`depth`는 입력 이미지의 채널 수를 지정하며 `classes`는 범주/클래스의 개수(정수)입니다(클래스 라벨 자체는 아님).
-`train.py` 스크립트에서 이러한 매개변수를 사용하여 `96 x 96 x 3` 입력 볼륨을 갖는 모델을 만들 것입니다.
-
-또한 `finalAct`(기본값 `"softmax"`)라는 옵션을 추가적으로 줄 수 있으며, 이는 네트워크 아키텍처의 끝에서 사용됩니다.
-이 값을 `"softmax"`에서 `"sigmoid"`로 변경하여 다중 라벨 분류를 수행할 수 있습니다.
-해당 옵션을 통해 단순/다중 라벨 분류를 위한 모델들을 모두 만들 수 있습니다.
-
-모델은 디폴트 값인 `"channels_last"`를 기반으로 하고있으며,
-코드 하단의 `if`문을 활용하면 `"channels_first"`으로 간편하게 설정 변경할 수 있습니다.
-
-다음은 첫 `CONV => RELU => POOL`블록을 만들어볼 차례입니다.
-
-```python
- # CONV => RELU => POOL
- model.add(Conv2D(32, (3, 3), padding="same",
- input_shape=inputShape))
- model.add(Activation("relu"))
- model.add(BatchNormalization(axis=chanDim))
- model.add(MaxPooling2D(pool_size=(3, 3)))
- model.add(Dropout(0.25))
-```
-
-위의 합성곱 계층은 32개의 필터와 3 x 3 크기의 커널을 가지며, 최종 값은 ReLU 활성화 함수를 거치게 됩니다.
-
-드롭아웃(Dropout)은 현재 계층과 다음 계층을 연결하는 노드들의 값을 무작위로 0으로 바꾸어주는 과정입니다(연결을 끊어주는 효과).
-이러한 프로세스는 네트워크가 특정 클래스, 객체, 가장자리 또는 모서리를 예측하는데 있어
-계층 내 어떠한 단일 노드에만 의존하지 않게 하여 네트워크의 과적합을 예방하는데 도움이 됩니다.
-
-그 후 모델은 두개의 `(CONV => RELU) * 2 => POOL`블록을 거치게 됩니다.
-
-```python
- # (CONV => RELU) * 2 => POOL
- model.add(Conv2D(64, (3, 3), padding="same"))
- model.add(Activation("relu"))
- model.add(BatchNormalization(axis=chanDim))
- model.add(Conv2D(64, (3, 3), padding="same"))
- model.add(Activation("relu"))
- model.add(BatchNormalization(axis=chanDim))
- model.add(MaxPooling2D(pool_size=(2, 2)))
- model.add(Dropout(0.25))
-
- # (CONV => RELU) * 2 => POOL
- model.add(Conv2D(128, (3, 3), padding="same"))
- model.add(Activation("relu"))
- model.add(BatchNormalization(axis=chanDim))
- model.add(Conv2D(128, (3, 3), padding="same"))
- model.add(Activation("relu"))
- model.add(BatchNormalization(axis=chanDim))
- model.add(MaxPooling2D(pool_size=(2, 2)))
- model.add(Dropout(0.25))
-```
-
-여기서 주목해야 할 점은 필터의 개수와 커널의 크기, 그리고 풀링의 크기에 변화를 주어
-공간의 크기는 점차 줄이지만, 깊이를 높인다는 것입니다.
-
-다음은 마지막 블록인 `FC => RELU`입니다.
-
-```python
- # FC => RELU
- model.add(Flatten())
- model.add(Dense(1024))
- model.add(Activation("relu"))
- model.add(BatchNormalization())
- model.add(Dropout(0.5))
-
- # 단일 라벨 분류는 *softmax* 활성화 함수를 사용합니다
- # 다중 라벨 분류는 *sigmoid* 활성화 함수를 사용합니다
- model.add(Dense(classes))
- model.add(Activation(finalAct))
-
- # 네트워크 아키텍처를 반환합니다
- return model
-```
-
-완전하게 연결된 계층(Fully Connected layer)인 `Dense`는 모델의 마지막에 배치됩니다.
-
-`Dense`의 결과 값은 마지막 활성화 함수인 `finalAct`를 거치게 됩니다.
-`"softmax"`를 사용하면 단일 라벨 분류를 수행하는 모델을 만들 수 있습니다.
-본 튜토리얼에서는 다중 라벨 분류를 위해 `"sigmoid"`를 사용합니다(`smallervggnet.py`와 `train.py` 참조).
-
-### 다중 라벨 분류를 위한 케라스 모델 구현
-
-이제 `소형VGGNet`을 구현했으니, `train.py`를 작성할 차례입니다. 이 스크립트는 다중 라벨 분류를 위해 케라스 모델을 학습시키는데 사용됩니다.
-
-`train.py`는 [***이 포스트***](https://www.pyimagesearch.com/2018/04/16/keras-and-convolutional-neural-networks-cnns/)에 기반하여 작성되었기 때문에 비교하여 같이 읽어본다면 스크립트를 이해하는데 도움이 될 것입니다.
-
-이제 `train.py`파일을 만들어 아래와 같이 코드를 작성합니다.
-
-```python
-# matplotlib의 백엔드를 설정하여 그림이 백그라운드에서 저장될 수 있게합니다
-import matplotlib
-matplotlib.use("Agg")
-
-# 필요한 패키지들을 가져옵니다
-from keras.preprocessing.image import ImageDataGenerator
-from keras.optimizers import Adam
-from keras.preprocessing.image import img_to_array
-from sklearn.preprocessing import MultiLabelBinarizer
-from sklearn.model_selection import train_test_split
-from pyimagesearch.smallervggnet import SmallerVGGNet
-import matplotlib.pyplot as plt
-from imutils import paths
-import numpy as np
-import argparse
-import random
-import pickle
-import cv2
-import os
-```
-
-위 코드에서는 해당 스크립트에 필요한 모듈들을 가져옵니다. `matplotlib.use("Agg")`로 렌더링을 위한 `matplotlib` 백엔드를 설정합니다. (본 튜토리얼은 Keras, scikit-learn, matplotlib, imutils 그리고 OpenCV가 모두 설치되어있다는 가정하에 진행됩니다.)
-
-만약 이번 튜토리얼로 처음 딥러닝을 실습해보는 것이라면, 필요한 라이브러리 및 패키지들을 준비하기 위한 두 가지 옵션이 있습니다.
-
-1. 사전에 구성된 환경(스타벅스 커피보다 저렴한 비용으로 오늘의 실습을 5분도 되지 않아 시작할 수 있습니다)
-2. 자체적으로 환경을 구성
-
-저는 클라우드에서 인스턴스 시작부터 파일 업로드와 학습, 데이터 다운로드,
-그리고 종료까지 채 수 분이 걸리지 않는 사전 구성된 환경을 선호합니다. 제가 추천하는 두 가지 환경은 다음과 같습니다.
-
-1. [Python을 활용한 AWS 딥러닝 AMI](https://www.pyimagesearch.com/2017/09/20/pre-configured-amazon-aws-deep-learning-ami-with-python/)
-2. [Microsoft의 딥러닝을 위한 DSVM(Data Science Virtual Machine)](https://www.pyimagesearch.com/2017/09/20/pre-configured-amazon-aws-deep-learning-ami-with-python/)
-
-만약 아직도 자체적으로 환경을 구성하기를 원하신다면(디버깅과 각종 문제 해결에 필요한 시간이 있으시다면),
-다음의 블로그 포스팅들을 참고해 보시는 것을 추천해드립니다.
-
-1. [Python 딥러닝을 위한 Ubuntu 환경 설정](https://www.pyimagesearch.com/2017/09/25/configuring-ubuntu-for-deep-learning-with-python/)
-2. [Python 딥러닝을 위한 Ubuntu 16.04 + CUDA + GPU 환경 설정](https://www.pyimagesearch.com/2017/09/27/setting-up-ubuntu-16-04-cuda-gpu-for-deep-learning-with-python/)
-3. [macOS에서 Python, Tensorflow, 그리고 Keras를 사용해서 딥러닝 해보기](https://www.pyimagesearch.com/2017/09/29/macos-for-deep-learning-with-python-tensorflow-and-keras/)
-
-이제 (1) 환경설정이 모두 완료되고 (2) 필요한 패키지들을 모두 가져왔기 때문에, 명령줄 인수들을 파싱해볼 차례입니다.
-
-```python
-# construct the argument parse and parse the arguments
-ap = argparse.ArgumentParser()
-ap.add_argument("-d", "--dataset", required=True,
- help="path to input dataset (i.e., directory of images)")
-ap.add_argument("-m", "--model", required=True,
- help="path to output model")
-ap.add_argument("-l", "--labelbin", required=True,
- help="path to output label binarizer")
-ap.add_argument("-p", "--plot", type=str, default="plot.png",
- help="path to output accuracy/loss plot")
-args = vars(ap.parse_args())
-```
-
-스크립트에 대한 명령줄 인수들은 함수에 대한 매개 변수들과 같습니다. 만약 비유가 이해가 가지 않으신다면 명령줄 인수에 대한 [블로그 포스팅](https://www.pyimagesearch.com/2018/03/12/python-argparse-command-line-arguments/)을 읽어보시는 것을 추천합니다.
-
-위 스크립트에는 총 네 가지의 인수들이 있습니다.
-
-1. `--dataset` : 데이터 세트의 경로입니다.
-2. `--model` : 디스크에 저장된 케라스 모델의 경로입니다.
-3. `--labelbin` : 학습의 결과인 `MultiLabelBinarizer`가 저장될 경로입니다.
-4. `--plot` : 학습 손실 값과 정확도 값의 그래프가 저장될 경로입니다.
-
-만약 위의 변수들의 역할이 이해가 가지 않으신다면 [이 포스트](https://www.pyimagesearch.com/2018/04/16/keras-and-convolutional-neural-networks-cnns/) 읽어보시는 것이 좋습니다.
-
-다음은 학습 과정에서 중요한 역할을 수행하는 몇 가지 중요한 변수를 초기화하겠습니다.
-
-```python
-# 학습을 위해 에폭과 초기 학습률, 배치 사이즈, 그리고 이미지의 차원을 초기화합니다
-EPOCHS = 75
-INIT_LR = 1e-3
-BS = 32
-IMAGE_DIMS = (96, 96, 3)
-```
-
-위의 변수들은 다음과 같은 의미를 갖습니다.
-
-* 네트워크는 75 `EPOCHS`동안 역전파를 통해 점진적으로 패턴을 학습합니다.
-* 초기 학습률(Learning rate)은 `1e-3`(Adam 옵티마이저의 기본값)입니다.
-* 배치 크기는 `32`입니다. GPU를 사용하는 경우 GPU 성능에 따라 이 값을 조정해야 하지만, 이번 프로젝트에는 `32`의 배치 크기로 좋은 결과를 얻을 수 있습니다.
-* 위에서 설명한 바와 같이 이미지의 크기는 `96 x 96`이며 3개의 채널을 가지고 있습니다.
-
-자세한 디테일은 [이전 포스트](https://www.pyimagesearch.com/2018/04/16/keras-and-convolutional-neural-networks-cnns/)를 참고하세요.
-
-이 다음 두 개의 코드 블록은 학습 데이터 로드와 전처리를 수행합니다.
-
-```python
-# 이미지 경로를 섞어줍니다
-print("[INFO] loading images...")
-imagePaths = sorted(list(paths.list_images(args["dataset"])))
-random.seed(42)
-random.shuffle(imagePaths)
-
-# 데이터와 라벨을 초기화합니다
-data = []
-labels = []
-```
-
-여기서는 `imagePaths`(영상 경로)를 읽어와 무작위로 섞어준 다음, 데이터와 라벨 목록을 초기화합니다.
-
-그런 다음 `imagePaths`의 각각의 경로에 대해 이미지 데이터를 전처리하며 다중 클래스 라벨을 추출합니다.
-
-```python
-# 인풋 이미지들에 대해 아래의 반복문을 수행합니다
-for imagePath in imagePaths:
- # 이미지를 로드하고, 전처리한 후 데이터 리스트에 저장합니다
- image = cv2.imread(imagePath)
- image = cv2.resize(image, (IMAGE_DIMS[1], IMAGE_DIMS[0]))
- image = img_to_array(image)
- data.append(image)
-
- # 이미지 경로에서 라벨을 추출한 후, 라벨 리스트를 업데이트합니다
- l = label = imagePath.split(os.path.sep)[-2].split("_")
- labels.append(l)
-```
-
-먼저 `cv2.imread(imagePath)`를 통해 각 이미지를 메모리에 로드합니다. 그 다음 두 줄에서는 딥러닝 파이프라인의 중요한 단계인 전처리를 수행합니다. `data.append(image)`는 처리된 이미지를 데이터에 추가합니다. 다음 줄의 `split`은 다중 라벨 분류 작업을 위해 이미지 경로를 여러 라벨로 분할합니다. 해당 라인의 실행 결과로 2개의 원소를 갖는 리스트가 생성된 후, 라벨 리스트에 추가됩니다.
-
-다음은 위의 작업을 터미널에서 단계별로 수행해 본 예시로, 다중 라벨 파싱이 어떻게 진행되는지 자세히 알 수 있습니다.
-
-```python
-$ python
->>> import os
->>> labels = []
->>> imagePath = "dataset/red_dress/long_dress_from_macys_red.png"
->>> l = label = imagePath.split(os.path.sep)[-2].split("_")
->>> l
-['red', 'dress']
->>> labels.append(l)
->>>
->>> imagePath = "dataset/blue_jeans/stylish_blue_jeans_from_your_favorite_store.png"
->>> l = label = imagePath.split(os.path.sep)[-2].split("_")
->>> labels.append(l)
->>>
->>> imagePath = "dataset/red_shirt/red_shirt_from_target.png"
->>> l = label = imagePath.split(os.path.sep)[-2].split("_")
->>> labels.append(l)
->>>
->>> labels
-[['red', 'dress'], ['blue', 'jeans'], ['red', 'shirt']]
-```
-
-보시다시피 `labels` 리스트는 "리스트의 리스트"입니다. `labels`의 각 원소는 2개의 원소를 갖는 리스트입니다. 각 리스트의 두 라벨은 입력 이미지 파일 경로를 기준으로 작성됩니다.
-
-전처리 과정은 아직 끝나지 않았습니다.
-
-```python
-# 모든 픽셀 값이 [0, 1]의 범위 내에 오도록 변환합니다
-data = np.array(data, dtype="float") / 255.0
-labels = np.array(labels)
-print("[INFO] data matrix: {} images ({:.2f}MB)".format(
- len(imagePaths), data.nbytes / (1024 * 1000.0)))
-```
-
-`data` 리스트에는 NumPy 배열로 저장된 이미지들이 포함되어 있습니다. 코드 한 줄에서 리스트를 NumPy 배열로 변환하고, 픽셀 강도를 범위 `[0, 1]`로 조정합니다.
-
-또한 라벨을 NumPy 배열로 변환합니다.
-
-이제 라벨을 이진화해 봅시다. 아래 블록은 이번 포스트의 다중 클래스 분류 개념에 있어 매우 중요합니다.
-
-```python
-# scikit-learn의 다중 라벨 이진화 함수를 사용해 라벨을 이진화 합니다
-print("[INFO] class labels:")
-mlb = MultiLabelBinarizer()
-labels = mlb.fit_transform(labels)
-
-# 나올 수 있는 모든 라벨들을 출력합니다
-for (i, label) in enumerate(mlb.classes_):
- print("{}. {}".format(i + 1, label))
-```
-
-다중 클래스 분류를 위해 라벨을 이진화하려면, scikit-learn 라이브러리의 [MultiLabelBinarizer](http://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MultiLabelBinarizer.html) 클래스를 활용해야 합니다. 다중 클래스 분류에는 표준 `LabelBinariser` 클래스를 사용할 수 없습니다. 위의 과정을 거쳐 사람이 읽을 수 있는 라벨들을 각 이미지가 어떤 클래스들에 속하는지 나타내는 벡터 값으로 인코딩합니다.
-
-다음은 `MultiLabelBinarizer`가 `("red", "math")`의 튜플을 6가지 범주가 있는 벡터로 변환하는 과정을 보여 주는 예입니다.
-
-```python
-$ python
->>> from sklearn.preprocessing import MultiLabelBinarizer
->>> labels = [
-... ("blue", "jeans"),
-... ("blue", "dress"),
-... ("red", "dress"),
-... ("red", "shirt"),
-... ("blue", "shirt"),
-... ("black", "jeans")
-... ]
->>> mlb = MultiLabelBinarizer()
->>> mlb.fit(labels)
-MultiLabelBinarizer(classes=None, sparse_output=False)
->>> mlb.classes_
-array(['black', 'blue', 'dress', 'jeans', 'red', 'shirt'], dtype=object)
->>> mlb.transform([("red", "dress")])
-array([[0, 0, 1, 0, 1, 0]])
-```
-
-`One-hot` 인코딩은 범주형 라벨을 단일 정수에서 벡터로 변환합니다. 같은 개념은 위의 과정에도 적용됩니다(위의 경우 `Two-hot`이긴 합니다).
-
-여기서 위의 Python 셸(`train.py`의 코드 블록과 혼동하지 마세요)의 최종 결과인 `array([[0, 0, 1, 0, 1, 0]])`에서 두 개의 범주형 라벨이 "hot"(배열에서 "1"로 표시)하여 각 라벨의 존재를 나타낸다는 것에 주목할 필요가 있습니다. 이 경우 "dress"와 "red"가 "hot"하며, 다른 모든 라벨의 값은 "0"입니다.
-
-이제 학습 및 테스트 분할을 구성하고, 데이터를 증강하기 위한 `ImageDataGenerator`를 초기화합니다.
-
-```python
-# 데이터의 80%를 학습에, 나머지 20%를 테스트에 사용하기 위해
-# 데이터를 나누는 과정입니다
-(trainX, testX, trainY, testY) = train_test_split(data,
- labels, test_size=0.2, random_state=42)
-
-# 이미지 오그멘테이션을 위한 제너레이터를 초기화합니다
-aug = ImageDataGenerator(rotation_range=25, width_shift_range=0.1,
- height_shift_range=0.1, shear_range=0.2, zoom_range=0.2,
- horizontal_flip=True, fill_mode="nearest")
-```
-
-학습과 테스트를 위해 데이터를 분할하는 것은 머신러닝을 적용하는데 있어 일반적인 과정입니다. 위 코드 블록에서는 scikit-learn의 `train_test_split`을 통해 이미지의 80%를 학습 데이터에 할당하고, 20%를 테스트 데이터에 할당하였습니다.
-
-`ImageDataGenerator`는 데이터 분할 이후에 초기화합니다. 클래스당 1,000개 미만의 이미지로 작업하는 경우 데이터 증강은 거의 항상 "반드시" 해야하는 작업입니다.
-
-다음으로 모델을 만들고 Adam 옵티마이저를 초기화해 봅니다.
-
-```python
-# 다중 라벨 분류를 수행할 수 있도록 sigmoid 활성화 함수를
-# 네트워크의 마지막 레이어로 설정합니다
-print("[INFO] compiling model...")
-model = SmallerVGGNet.build(
- width=IMAGE_DIMS[1], height=IMAGE_DIMS[0],
- depth=IMAGE_DIMS[2], classes=len(mlb.classes_),
- finalAct="sigmoid")
-
-# 옵티마이저를 초기화합니다
-opt = Adam(lr=INIT_LR, decay=INIT_LR / EPOCHS)
-```
-
-위 코드에서 `SmallerVGGNet.build`로 `소형VGGNet`모델을 빌드합니다.
-이 때 `finalAct="sigmoid"`는 이 모델로 다중 라벨 분류를 수행할 것임을 나타냅니다.
-
-이제 모델을 컴파일하고 학습을 시작합니다(하드웨어에 따라 시간이 좀 걸릴 수 있습니다).
-
-```python
-# 각각의 결과 라벨을 독립적인 베르누이 분포로 취급하기 위해
-# 범주형 교차 엔트로피 대신 이진 교차 엔트로피를 사용하여 모델을 컴파일합니다
-model.compile(loss="binary_crossentropy", optimizer=opt,
- metrics=["accuracy"])
-
-# 네트워크를 학습시킵니다
-print("[INFO] training network...")
-H = model.fit_generator(
- aug.flow(trainX, trainY, batch_size=BS),
- validation_data=(testX, testY),
- steps_per_epoch=len(trainX) // BS,
- epochs=EPOCHS, verbose=1)
-```
-
-`model.compile`로 모델을 컴파일할 때, **범주형 교차 엔트로피(categorical cross-entropy)**대신 **이진 교차 엔트로피(binary cross-entropy)**를 사용합니다.
-
-이것은 다중 라벨 분류에 있어 직관에 어긋나는 것처럼 보일 수 있지만, 이는 각각의 결과 라벨을 독립적인 베르누이 분포로 취급하기 위함입니다. 이를 통해 각각의 결과 노드들을 독립적으로 학습시킬 수 있습니다.
-
-모델 빌드 후에는 증강된 데이터를 사용하여 학습을 시작합니다.
-
-학습이 끝난 후에는 모델과 `MultiLabelBinarizer`를 디스크에 저장할 수 있습니다.
-
-```python
-# 모델을 디스크에 저장합니다
-print("[INFO] serializing network...")
-model.save(args["model"])
-
-# `MultiLabelBinarizer`를 디스크에 저장합니다
-print("[INFO] serializing label binarizer...")
-f = open(args["labelbin"], "wb")
-f.write(pickle.dumps(mlb))
-f.close()
-```
-
-이제 정확도와 손실 값을 그래프로 나타내 봅니다.
-
-```python
-# 학습 로스와 정확도를 그래프로 그려줍니다
-plt.style.use("ggplot")
-plt.figure()
-N = EPOCHS
-plt.plot(np.arange(0, N), H.history["loss"], label="train_loss")
-plt.plot(np.arange(0, N), H.history["val_loss"], label="val_loss")
-plt.plot(np.arange(0, N), H.history["acc"], label="train_acc")
-plt.plot(np.arange(0, N), H.history["val_acc"], label="val_acc")
-plt.title("Training Loss and Accuracy")
-plt.xlabel("Epoch #")
-plt.ylabel("Loss/Accuracy")
-plt.legend(loc="upper left")
-plt.savefig(args["plot"])
-```
-
-학습과 검증 과정의 정확도와 손실 값은 `plt.plot`으로 그릴 수 있으며, 이를 `plt.savefig`로 이미지 파일로 저장할 수 있습니다.
-
-저는 학습 과정을 그래프로 나타내는 것은 모델 자체 만큼이나 중요하다고 생각합니다. 저는 보통 블로그에 결과물을 올려 여러분과 공유하기 전에 몇 차례에 걸쳐 학습과 그 그래프를 그려 확인하는 과정을 거칩니다.
-
-### 다중 라벨 분류를 위한 케라스 모델 학습
-
-만약 직접 모델을 학습하고 싶지 않으면, [본 포스트](https://www.pyimagesearch.com/2018/05/07/multi-label-classification-with-keras/)의 "다운로드" 섹션에서 코드와 데이터 세트, 그리고 학습된 모델을 다운로드 받을 수 있습니다.
-
-모델을 직접 학습하고 싶다면 터미널 창을 열어, 프로젝트 디렉토리로 이동한 후 다음과 같은 명령어를 실행해주세요.
-
-```shell
-$ python train.py --dataset dataset --model fashion.model \
- --labelbin mlb.pickle
-Using TensorFlow backend.
-[INFO] loading images...
-[INFO] data matrix: 2165 images (467.64MB)
-[INFO] class labels:
-1. black
-2. blue
-3. dress
-4. jeans
-5. red
-6. shirt
-[INFO] compiling model...
-[INFO] training network...
-Epoch 1/75
-name: GeForce GTX TITAN X
-54/54 [==============================] - 4s - loss: 0.3503 - acc: 0.8682 - val_loss: 0.9417 - val_acc: 0.6520
-Epoch 2/75
-54/54 [==============================] - 2s - loss: 0.1833 - acc: 0.9324 - val_loss: 0.7770 - val_acc: 0.5377
-Epoch 3/75
-54/54 [==============================] - 2s - loss: 0.1736 - acc: 0.9378 - val_loss: 1.1532 - val_acc: 0.6436
-...
-Epoch 73/75
-54/54 [==============================] - 2s - loss: 0.0534 - acc: 0.9813 - val_loss: 0.0324 - val_acc: 0.9888
-Epoch 74/75
-54/54 [==============================] - 2s - loss: 0.0518 - acc: 0.9833 - val_loss: 0.0645 - val_acc: 0.9784
-Epoch 75/75
-54/54 [==============================] - 2s - loss: 0.0405 - acc: 0.9857 - val_loss: 0.0429 - val_acc: 0.9842
-[INFO] serializing network...
-[INFO] serializing label binarizer...
-```
-
-보시는 바와 같이, 모델을 75 `EPOCHS`동안 학습한 결과는 다음과 같습니다.
-
-* 학습 데이터 세트에 대한 다중 라벨 분류 정확도 **98.57%**
-* 테스트 데이터 세트에 대한 다중 라벨 분류 정확도 **98.42%**
-
-학습 과정에서의 손실 값 및 정확도에 대한 그래프는 아래와 같습니다.
-
-
-
-### 새로운 이미지에 적용해보는 케라스 다중 라벨 분류
-
-케라스를 이용한 다중 라벨 분류 모델의 학습이 완료되었으니, 이제는 이 모델을 테스트 데이터 세트 이외의 이미지들에 적용해볼 차례입니다.
-
-이번 스크립트는 [이전 블로그 포스트](https://www.pyimagesearch.com/2018/04/16/keras-and-convolutional-neural-networks-cnns/)의 `classify.py`와 유사합니다. 다중 라벨 분류를 위해 바뀐 부분들을 주의해 주세요.
-
-준비가 되셨다면 프로젝트 디렉토리에 `classify.py`라는 새 파일을 생성한 후, 아래와 같이 코드를 작성해주세요(혹은 위의 "다운로드" 섹션에서 받은 코드를 사용해주세요).
-
-```python
-# 필요한 패키지들을 가져옵니다
-from keras.preprocessing.image import img_to_array
-from keras.models import load_model
-import numpy as np
-import argparse
-import imutils
-import pickle
-import cv2
-import os
-
-# 명령줄 인수를 파싱해옵니다
-ap = argparse.ArgumentParser()
-ap.add_argument("-m", "--model", required=True,
- help="path to trained model model")
-ap.add_argument("-l", "--labelbin", required=True,
- help="path to label binarizer")
-ap.add_argument("-i", "--image", required=True,
- help="path to input image")
-args = vars(ap.parse_args())
-```
-
-라인 2-9에서 이 스크립트에 필요한 패키지를 가져옵니다. 이 스크립트에서는 Keras와 OpenCV를 사용할 예정입니다.
-
-라인 12-19는 스크립트에 필요한 명령줄 인수들을 파싱하는 부분입니다.
-
-그 후, 입력 이미지를 불러오고, 아래와 같이 전처리 과정을 거칩니다.
-
-```python
-# 이미지를 로드합니다
-image = cv2.imread(args["image"])
-output = imutils.resize(image, width=400)
-
-# 분류를 위한 이미지 전처리를 수행합니다
-image = cv2.resize(image, (96, 96))
-image = image.astype("float") / 255.0
-image = img_to_array(image)
-image = np.expand_dims(image, axis=0)
-```
-
-입력 이미지에 대한 전처리는 앞서 학습 데이터를 전처리 했던 방식과 같습니다.
-
-이제 모델과 `MultiLabelBinarizer`를 로드하고, 이미지를 분류합니다.
-
-```python
-# 학습된 네트워크와 `MultiLabelBinarizer`를 로드합니다
-print("[INFO] loading network...")
-model = load_model(args["model"])
-mlb = pickle.loads(open(args["labelbin"], "rb").read())
-
-# 이미지에 대한 분류를 수행한 후,
-# 확률이 가장 높은 두 개의 클래스 라벨을 찾습니다
-print("[INFO] classifying image...")
-proba = model.predict(image)[0]
-idxs = np.argsort(proba)[::-1][:2]
-```
-
-위 코드 블록의 첫 두 줄에서 `model`과 `MultiLabelBinarizer`를 디스크에서 메모리로 로드합니다.
-
-그 후 (전처리된)입력 이미지를 분류하고, 상위 2개 클래스 라벨 인덱스를 다음과 같이 추출합니다.
-
-* 연관된 확률을 기준으로 배열 인덱스를 내림차순 정렬
-* 상위 두개 라벨 인덱스를 추출(모델의 상위 두 개 예측)
-
-원한다면 더 많은 클래스 라벨들을 반환하도록 이 코드를 수정할 수 있습니다. 또한 확률에 대한 문턱값과 신뢰도가 N%를 초과하는 라벨만 반환하는 것을 추천합니다.
-
-이제 결과 이미지에 덧씌워줄 클래스 라벨과 관련 신뢰 값들을 준비할 차례입니다.
-
-```python
-# 확률이 높은 라벨들에 대해 아래의 반복문을 수행합니다
-for (i, j) in enumerate(idxs):
- # 이미지 위에 라벨을 덧씌웁니다
- label = "{}: {:.2f}%".format(mlb.classes_[j], proba[j] * 100)
- cv2.putText(output, label, (10, (i * 30) + 25),
- cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
-
-# 각 라벨에 대한 확률을 출력합니다
-for (label, p) in zip(mlb.classes_, proba):
- print("{}: {:.2f}%".format(label, p * 100))
-
-# 결과 이미지를 출력합니다
-cv2.imshow("Output", output)
-cv2.waitKey(0)
-```
-
-첫 반복문은 출력 이미지에 상위 두 개의 다중 라벨 예측과 해당 신뢰도 값을 그려줍니다.
-
-마찬가지로, 다음 반복문 에서는 터미널에 모든 예측값들을 출력해줍니다. 이는 디버깅을 편리하게 해줍니다.
-
-그 후, 마지막으로 출력 이미지를 화면에 띄워줍니다.
-
-### 케라스 다중 라벨 분류 결과
-
-이제 명령줄 인수를 사용하여 `classify.py`를 실제로 사용해봅시다. CNN모델로 새로운 이미지를 분류하기 위해 위에서 설명한 코드를 수정할 필요는 없습니다.
-아래와 같이 터미널에서 명령줄 인수를 사용하면 됩니다.
-
-먼저 빨간색 드레스의 이미지를 분류해보겠습니다. 아래의 이미지를 처리하기 위해 런타임에 처리되는 명령줄 인수는 세 가지 입니다.
-
-```shell
-$ python classify.py --model fashion.model --labelbin mlb.pickle \
- --image examples/example_01.jpg
-Using TensorFlow backend.
-[INFO] loading network...
-[INFO] classifying image...
-black: 0.00%
-blue: 3.58%
-dress: 95.14%
-jeans: 0.00%
-red: 100.00%
-shirt: 64.02%
-```
-
-
-
-성공! 두 클래스 ("빨간색"과 "드레스")가 얼마나 높은 신뢰도로 예측되었는지 확인할 수 있습니다.
-
-이번에는 파란색 드레스를 분류해봅시다.
-
-```shell
-$ python classify.py --model fashion.model --labelbin mlb.pickle \
- --image examples/example_02.jpg
-Using TensorFlow backend.
-[INFO] loading network...
-[INFO] classifying image...
-black: 0.03%
-blue: 99.98%
-dress: 98.50%
-jeans: 0.23%
-red: 0.00%
-shirt: 0.74%
-```
-
-
-
-파란색 드레스도 문제없이 분류할 수 있습니다. 꽤 괜찮은 출발입니다! 이번에는 빨간색 셔츠를 분류해봅시다.
-
-```shell
-$ python classify.py --model fashion.model --labelbin mlb.pickle \
- --image examples/example_03.jpg
-Using TensorFlow backend.
-[INFO] loading network...
-[INFO] classifying image...
-black: 0.00%
-blue: 0.69%
-dress: 0.00%
-jeans: 0.00%
-red: 100.00%
-shirt: 100.00%
-```
-
-
-
-이 정도면 훌륭한 결과입니다. 파란색 셔츠는 어떨까요?
-
-```shell
-$ python classify.py --model fashion.model --labelbin mlb.pickle \
- --image examples/example_04.jpg
-Using TensorFlow backend.
-[INFO] loading network...
-[INFO] classifying image...
-black: 0.00%
-blue: 99.99%
-dress: 22.59%
-jeans: 0.08%
-red: 0.00%
-shirt: 82.82%
-```
-
-
-
-우리 모델은 매우 높은 정확도로 옷이 파란색인 것을 예측하고 있지만, 셔츠라는 확신은 그만큼 높지 않습니다.
-하지만, 이것은 여전히 정확한 다중 라벨 분류입니다!
-
-이번에는 파란색 청바지로 다중 라벨 분류기를 속일 수 있는지 알아보겠습니다.
-
-```shell
-$ python classify.py --model fashion.model --labelbin mlb.pickle \
- --image examples/example_05.jpg
-Using TensorFlow backend.
-[INFO] loading network...
-[INFO] classifying image...
-black: 0.00%
-blue: 100.00%
-dress: 0.01%
-jeans: 99.99%
-red: 0.00%
-shirt: 0.00%
-```
-
-
-
-이번에는 검정색 청바지를 분류해보겠습니다.
-
-
-
-저는 이것이 데님 청바지라고 100% 확신할 수는 없지만, 다중 라벨 분류기는 그렇다고 합니다!
-
-이제 마지막 예제인 검정색 드레스(`example_07.jpg`)를 살펴보겠습니다. 우리의 네트워크는 *"검정색 청바지"* 와 *"파란색 청바지"*, 그리고 *"파란색 드레스"* 와 *"빨간색 드레스"* 를 분류할 수 있게 학습되었습니다. 그러면, 이 모델을 사용하여 *"검정색 드레스"* 를 분류할 수 있을까요?
-
-```shell
-$ python classify.py --model fashion.model --labelbin mlb.pickle \
- --image examples/example_07.jpg
-Using TensorFlow backend.
-[INFO] loading network...
-[INFO] classifying image...
-black: 91.28%
-blue: 7.70%
-dress: 5.48%
-jeans: 71.87%
-red: 0.00%
-shirt: 5.92%
-```
-
-
-
-이번에는 제대로 분류하지 못했군요! 분류기는 사진 속의 모델이 검정색 청바지를 입고 있을거라 했지만, 실제로는 검정색 드레스를 입고있었죠.
-
-어떤 일이 일어난 것일까요?
-
-왜 다중 라벨 분류가 제대로 되지 않았을까요? 이유는 아래의 요약을 읽어보시면 알 수 있습니다.
-
-### 요약
-
-이번 블로그 포스트에서는 케라스를 사용하여 다중 라벨 분류를 수행하는 방법에 대해 배웠습니다.
-
-**케라스를 사용하여 다중 라벨 분류를 수행하는 것은 매우 간단하며, 다음의 두 가지 기본 단계를 포함합니다.**
-
-1. 네트워크 마지막의 *소프트맥스* 활성화 함수를 *시그모이드* 함수로 대체합니다.
-2. *범주형 교차 엔트로피* 대신 *이진 교차 엔트로피* 를 사용합니다.
-
-위의 두 가지 과정을 거쳤다면, 이제 평소처럼 네트워크를 학습하면 됩니다.
-
-위의 과정을 적용한 결과는 다중 라벨 분류기입니다.
-
-케라스 다중 라벨 분류기를 사용하면, 단 한 번의 포워드 패스 만으로 여러 개의 라벨을 예측할 수 있습니다.
-
-**하지만, 이 때 고려해야 할 문제가 있습니다.**
-
-바로 예측하려는 모든 범주의 조합에 대한 학습 데이터가 필요하다는 것입니다.
-
-신경망이 학습되지 않은 클래스를 예측할 수 없는 것처럼,
-다중 라벨 분류기 역시 한번도 학습 데이터에 등장하지 않은 조합에 대해서는 예측할 수 없습니다.
-이러한 현상의 원인은 네트워크 내부의 활성화 함수들 때문입니다.
-
-만약 네트워크가 (1) 검정색 바지 및 (2) 빨간색 셔츠만로 이루어진 데이터 세트에 대해 학습되었고,
-새로운 이미지인 *"빨간색 바지"* 를 예측하고자 한다면, *"빨간색"* 과 *"바지"* 를 감지하는 뉴런들은 작동하지만,
-완전히 연결된 계층에서 이러한 조합의 데이터/활성화 값을 본 적이 없기 때문에,
-모델의 예측 결과는 틀릴 가능성이 높습니다(즉, *"빨간색"* 과 *"바지"* 에 해당하는 데이터는 있지만, 두 가지가 동시에 주어지는 경우는 없습니다).
-
-다시 한 번 말하지만, 네트워크는 한 번도 학습되지 않은 데이터에 대해서는 정확하게 예측할 수 없습니다.
-다중 라벨 분류를 위해 케라스 네트워크를 학습시킬 때에는 위 사항을 항상 명심해야 합니다.
-
-이번 블로그 포스트를 재밌게 보셨길 바랍니다!
-
-> 이 글은 2018 컨트리뷰톤에서 Contribute to Keras 프로젝트로 진행했습니다.
-> Translator: [정연준](https://github.com/fuzzythecat)
-> Translator email : fuzzy0427@gmail.com
diff --git "a/37_\354\274\200\353\235\274\354\212\244\353\245\274 \354\235\264\354\232\251\355\225\234 \353\251\200\355\213\260 GPU \355\225\231\354\212\265.md" "b/37_\354\274\200\353\235\274\354\212\244\353\245\274 \354\235\264\354\232\251\355\225\234 \353\251\200\355\213\260 GPU \355\225\231\354\212\265.md"
deleted file mode 100644
index 26a8581..0000000
--- "a/37_\354\274\200\353\235\274\354\212\244\353\245\274 \354\235\264\354\232\251\355\225\234 \353\251\200\355\213\260 GPU \355\225\231\354\212\265.md"
+++ /dev/null
@@ -1,439 +0,0 @@
-## 케라스를 이용한 멀티 GPU 학습(How-To: Multi-GPU training with Keras, Python, and deep learning)
-[원문 링크](https://www.pyimagesearch.com/2017/10/30/how-to-multi-gpu-training-with-keras-python-and-deep-learning/)
-
-> 본 튜토리얼에서는 케라스로 멀티 GPU를 이용한 모델 학습을 하는 방법을 알아봅니다.
-
-* Keras
-* CNN
-* Multi-GPU
-* Classification
-
-----
-
-저는 처음 케라스(Keras)를 사용하기 시작했을 때 케라스의 API와 사랑에 빠지게 되었습니다.
-케라스의 API는 scikit-learn처럼 간단하고 우아하지만, 동시에 최첨단의 심층 신경망(Deep Neural Network, DNN)들을 구현하고 학습시킬 수 있을 만큼 강력하기 때문입니다.
-
-하지만, 케라스를 사용하며 한 가지 아쉬운 점이 있다면 바로 멀티 GPU 환경에서 케라스를 사용하는 것이 까다로울 수 있다는 것입니다.
-
-만약 테아노(Theano)를 사용하는 유저들이라면, 이 주제는 테아노에서는 불가능한 것에 대해 다루기 때문에 신경쓰지 않으셔도 됩니다.
-텐서플로우(TensorFlow)를 사용한다면 가능성은 있지만, 멀티 GPU를 사용하여 네트워크를 학습시키려면 수 많은 보일러플레이트 코드와
-수정이 필요할 수 있다는 단점이 있죠.
-
-그래서 저는 지금까지 케라스로 멀티 GPU 학습을 할 때는 MXNet 백엔드를 사용하는 것(심지어 MXNet 라이브러리를 직접 사용하는 것)을 선호했었지만,
-이 역시 여전히 많은 환경설정 작업이 필요했습니다.
-
-그러나 이 모든 것은 **케라스 v2.0.9**에서 멀티 GPU를 텐서플로우 백엔드에서 지원한다는
-[François Chollet의 발표](https://twitter.com/fchollet/status/918205049225936896)와 함께 바뀌었습니다
-([@kuza55](https://twitter.com/kuza55)와 그의 [keras-extras](https://github.com/kuza55/keras-extras) 리포지토리 덕분입니다).
-
-저는 [@kuza55](https://twitter.com/kuza55)의 멀티 GPU 기능을 근 1년간 사용해오고 있었고,
-이제 이 기능이 케라스에 공식적으로 포함되었다는 소식을 듣게 되어 매우 기쁩니다!
-
-이번 블로그 포스트의 나머지 부분에서는 케라스, 파이썬(Python) 그리고 딥러닝을 사용하여
-이미지를 분류하기 위해 합성곱 신경망(Convolutional Neural Network, CNN)을 학습하는 법에 대해 알아보도록 하겠습니다.
-
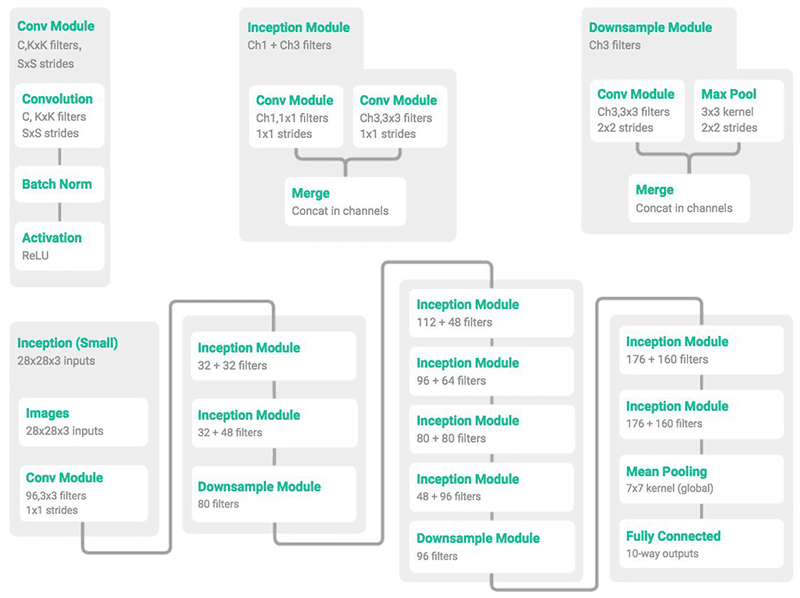
-### MiniGoogLeNet 딥러닝 아키텍처
-
-
-
-**Figure 1**: MiniGoogLeNet 아키텍처는 GoogLeNet/Inception의 축소된 버전입니다.
-이미지 크레딧 [@ericjang11](https://twitter.com/ericjang11), [@pluskid](https://twitter.com/pluskid).
-
-**Figure 1**에서는 합성곱(Convolution, 좌측), 인셉션(Inception, 중앙) 그리고 다운 샘플(Downsample, 우측)에 해당하는 각 모듈들을 확인할 수 있고,
-하단에서그 모듈들의 조합으로 만들어진 MiniGoogLeNet 아키텍처를 볼 수 있습니다.
-해당 모델은 포스트 후반부의 다중 GPU 실험에 사용될 예정입니다.
-
-MiniGoogLeNet에서 사용된 인셉션 모듈은 [Szegedy et al.](https://arxiv.org/abs/1409.4842)이 설계한 인셉션 모듈의 변형입니다.
-
-저는 [@ericjang11](https://twitter.com/ericjang11)과 [@pluskid](https://twitter.com/pluskid)가 MiniGoogLeNet과 관련 모듈들을
-아름답게 시각화한 트윗을 통해 이 "Miniception"모듈을 처음 알게 되었습니다.
-
-그리고 약간의 조사 후에, 저는 이 그림이 Zhang et al.이 2017년에 출판한 논문 [*Understanding Deep Learning Requires Re-Thinking Generalization*](https://arxiv.org/abs/1611.03530)에 나온다는 것을 발견했습니다.
-
-그런 다음 저는 MiniGoogLeNet 아키텍처를 케라스와 파이썬을 이용해 구현하였고, 이 내용을 제 책인
-[*Deep Learning for Computer Vision with Python*](https://www.pyimagesearch.com/deep-learning-computer-vision-python-book/)에 싣기도 하였습니다!
-
-케라스로 MiniGoogLeNet을 구현하는 것에 대한 자세한 내용은 이번 포스트에서 다루는 내용의 범위를 벗어나기 때문에,
-해당 모델의 원리(그리고 구현하는 법)에 관심이 있으시다면 제 책을 참고하시길 바랍니다.
-
-그렇지 않다면 원문의 하단에 있는 ***"다운로드"*** 섹션에서 소스 코드를 다운로드할 수 있습니다.
-
-### 케라스와 멀티 GPU로 심층 신경망 학습하기
-
-이제 케라스와 멀티 GPU를 사용하여 심층 신경망을 학습해 보겠습니다.
-
-해당 튜토리얼을 진행하려면, 먼저 가상 환경에 설치된 **케라스의 버전이 2.0.9 이상인지 확인**해야 합니다
-(제 책에서는 `dl4cv`라는 이름의 가상 환경을 사용합니다).
-
-```
-$ workon dl4cv
-$ pip install --upgrade keras
-```
-
-이제 `train.py`라는 새 파일을 만들고, 아래와 같이 코드를 작성합니다.
-
-```python
-# matplotlib의 백엔드를 설정하여 그림이 백그라운드에서 저장될 수 있게합니다
-# 헤드리스 서버에서 작업하는 경우 아래의 함수를 호출하세요
-# import matplotlib
-# matplotlib.use("Agg")
-
-# 필요한 패키지들을 가져옵니다
-from pyimagesearch.minigooglenet import MiniGoogLeNet
-from sklearn.preprocessing import LabelBinarizer
-from keras.preprocessing.image import ImageDataGenerator
-from keras.callbacks import LearningRateScheduler
-from keras.utils.training_utils import multi_gpu_model
-from keras.optimizers import SGD
-from keras.datasets import cifar10
-import matplotlib.pyplot as plt
-import tensorflow as tf
-import numpy as np
-import argparse
-```
-
-헤드리스 서버를 사용하는 경우, 3, 4번째 행의 코드로 `matplotlib`의 백엔드를 설정해야 합니다.
-이렇게 하면 `matplotlib`의 그림을 디스크에 저장할 수 있게됩니다.
-헤드리스 서버를 사용하지 않는다면(즉, 키보드와 마우스 그리고 모니터가 시스템에 연결되어 있는 경우) 위의 코드를 그대로 사용하셔도 됩니다.
-
-백엔드 설정이 끝나면, 이 스크립트에 필요한 패키지들을 가져옵니다.
-
-7행에서는 MiniGoogLeNet을 제 `pyimagesearch`모듈에서 가져옵니다 (원문의 ***"다운로드"*** 섹션에서 받으실 수 있습니다).
-
-또 한가지 주목할 만한 점은, 13행에서 [CIFAR-10 데이터 세트](https://www.cs.toronto.edu/~kriz/cifar.html)를 가져오는 부분입니다.
-케라스를 사용하면 단 한줄의 코드만으로 CIFAR-10 데이터 세트를 디스크에서 로드할 수 있습니다.
-
-이제, 스크립트에 필요한 인자들을 파싱하기 위한 명령줄 인터페이스를 작성해 보겠습니다.
-
-```python
-# 명령줄 인수를 파싱해옵니다
-ap = argparse.ArgumentParser()
-ap.add_argument("-o", "--output", required=True,
- help="path to output plot")
-ap.add_argument("-g", "--gpus", type=int, default=1,
- help="# of GPUs to use for training")
-args = vars(ap.parse_args())
-
-# 편의를 위해 GPU의 개수를 파싱해와 변수에 저장합니다
-G = args["gpus"]
-```
-
-파싱에는 `argparse` 모듈을 사용하며, 하나의 *필수* 인자와 하나의 *선택적* 인자를 파싱해올 것입니다.
-
-* `--output` : 학습이 완료된 후 관련 플롯들을 저장할 경로입니다.
-* `--gpus` : 학습에 사용될 GPU의 개수입니다.
-
-명령줄 인자들을 로드한 후에는, 편의를 위해 GPU의 개수를 변수 `G`에 저장합니다.
-
-이제 학습 프로세스를 구성하는데 사용되는 두 가지 중요한 변수를 초기화하고,
-이어서 [학습률을 다항적으로 감소시키는](https://stackoverflow.com/questions/30033096/what-is-lr-policy-in-caffe) `poly_decay` 학습률 스케줄러를 정의합니다.
-
-```python
-# 학습을 위해 에폭, 초기 학습률 그리고 배치 크기를 설정합니다
-NUM_EPOCHS = 70
-INIT_LR = 5e-3
-
-def poly_decay(epoch):
- # 에폭의 최대치와 초기 학습률, 그리고
- # 다항식의 거듭제곱의 지수를 초기화합니다
- maxEpochs = NUM_EPOCHS
- baseLR = INIT_LR
- power = 1.0
-
- # 새 학습률을 계산합니다
- alpha = baseLR * (1 - (epoch / float(maxEpochs))) ** power
-
- # 새 학습률을 반환합니다
- return alpha
-```
-
-에폭(Epoch)은 `NUM_EPOCHS = 70`로 설정되며, 이는 네트워크가 학습 데이터 전체를 총 몇 번 학습하는지 결정합니다.
-
-또한 초기 학습률은 실험을 통해 찾은 `INIT_LR = 5e-3`로 설정합니다.
-
-그 후에 정의되는 `poly_decay`는, 학습 도중 매 에폭 이후에 효과적으로 학습률을 감소시키는 역할을 합니다.
-만약 `power = 1.0`로 설정하면, 학습률은 다항적이 아닌 선형적으로 감소하게 됩니다.
-
-다음은 학습 및 테스트 데이터 세트를 로드한 후, 이미지 데이터를 정수형에서 실수형으로 변환하는 작업입니다.
-
-```python
-# 학습과 테스트 데이터 세트를 로드한 후, 이미지 데이터를
-# 정수형에서 실수형으로 변환합니다
-print("[INFO] loading CIFAR-10 data...")
-((trainX, trainY), (testX, testY)) = cifar10.load_data()
-trainX = trainX.astype("float")
-testX = testX.astype("float")
-```
-
-그 후, 데이터의 각 원소에서 데이터 전체의
-[평균값을 빼줍니다](http://ufldl.stanford.edu/wiki/index.php/Data_Preprocessing#Per-example_mean_subtraction).
-
-```python
-# 데이터의 각 원소에서 데이터 전체의 평균값을 빼줍니다
-mean = np.mean(trainX, axis=0)
-trainX -= mean
-testX -= mean
-```
-
-위 코드 블록의 두 번째 행에서 학습 데이터 세트 전체의 평균값을 구해주며,
-세 번째, 네 번째 행에서 각각 학습과 테스트 세트 이미지에서 위에서 구한 평균값을 빼줍니다.
-
-그 다음은 원핫 인코딩(One-hot encoding)을 할 차례입니다.
-원핫 인코딩에 대한 자세한 설명은 제 책에 나와있습니다.
-
-```python
-# 단일 정수인 범주형 라벨을 벡터로 변환합니다
-lb = LabelBinarizer()
-trainY = lb.fit_transform(trainY)
-testY = lb.transform(testY)
-```
-
-원핫 인코딩은 단일 정수인 범주형 라벨을 벡터로 변환해주어
-범주형 교차 엔트로피(Categorical cross-entropy) 손실 함수(Loss function)를 사용할 수 있게 해줍니다.
-
-다음은 데이터 오그멘테이션(Augmentation)을 위한 함수와, 기타 콜백 함수들을 정의하는 부분입니다.
-
-```python
-# 데이터 오그멘테이션을 위한 이미지 제너레이터와
-# 기타 콜백 함수들을 정의합니다
-aug = ImageDataGenerator(width_shift_range=0.1,
- height_shift_range=0.1, horizontal_flip=True,
- fill_mode="nearest")
-callbacks = [LearningRateScheduler(poly_decay)]
-```
-
-블록의 세 번째 행에서는 데이터 오그멘테이션을 위한 이미지 제너레이터(Generator)를 구성합니다.
-
-데이터 오그멘테이션에 대한 자세한 내용은
-[*Deep Learning for Computer Vision with Python*](https://www.pyimagesearch.com/deep-learning-computer-vision-python-book/)
-실무자 버전에서 다루고 있지만, 간단히 설명하자면 오그멘테이션은 학습에 사용되는 이미지들을
-임의로 변형하여 새로운 이미지를 생성하는 방법론 입니다.
-
-이러한 변형은 네트워크가 지속적으로 새로운 이미지를 학습할 수 있게 하고,
-검증 데이터 세트에 대해 일반화가 더 잘 이루어지게 합니다. 간혹 학습 데이터 세트에 대한
-성능이 저하될 수도 있지만, 대부분의 경우 이 정도는 타협할 수 있는 수준입니다.
-
-블록의 마지막 행에서는 매 에폭마다 학습률을 감소시켜주기 위한 콜백 함수를 정의합니다.
-
-다음으로 GPU 변수를 살펴보겠습니다.
-
-```python
-# 단일 GPU로 학습을 하는지 여부를 확인합니다
-if G <= 1:
- print("[INFO] training with 1 GPU...")
- model = MiniGoogLeNet.build(width=32, height=32, depth=3,
- classes=10)
-```
-
-만약 GPU의 수가 하나이거나 없으면, `.build` 함수를 통해 `model` 변수를 초기화합니다.
-GPU가 두 개 이상인 경우, 학습 중에 모델을 병렬화 할 것입니다.
-
-```python
-# 여러개의 GPU를 사용하는 경우입니다
-else:
- print("[INFO] training with {} GPUs...".format(G))
-
- # 모델은 복제되어 모든 GPU에 저장되며, CPU에서는 각 GPU에서
- # 계산한 기울기들을 바탕으로 모델의 가중치를 업데이트 합니다
- with tf.device("/cpu:0"):
- # initialize the model
- model = MiniGoogLeNet.build(width=32, height=32, depth=3,
- classes=10)
-
- # make the model parallel
- model = multi_gpu_model(model, gpus=G)
-```
-
-케라스에서 멀티 GPU 모델을 만들려면 약간의 코드를 추가해야 하지만, *그 양이 그리 많지는 않습니다!*
-
-먼저, `with tf.device("/cpu:0"):`를 통해 네트워크 컨텍스트로 CPU(GPU가 아닌)를 사용하도록 한 것이 보이실 겁니다.
-
-왜 멀티 GPU 모델에서 CPU가 필요할까요?
-
-그 이유는, GPU가 무거운 연산들을 처리하는 동안,
-CPU가 그에 필요한 오버헤드를(예를 들면, 학습 이미지를 GPU 메모리에 올리는 작업) 처리해주기 때문입니다.
-
-여기서는 CPU가 기본 모델을 초기화하는 작업을 처리하며,
-초기화가 완료된 후에 `multi_gpu_model`을 호출하게 됩니다.
-`multi_gpu_model` 함수는 CPU에서 모든 GPU로 모델을 복제하여 단일 시스템, 다중 GPU 데이터 병렬 처리를 가능하게 해줍니다.
-
-학습이 시작되면 학습 이미지들은 배치 단위로 각 GPU에 할당됩니다.
-그 후 CPU는 각 GPU에서 계산한 기울기(Gradients)들을 바탕으로 모델의 가중치를 업데이트 합니다.
-
-이제 우리는 모델을 컴파일하고, 학습을 시작할 수 있습니다.
-
-```python
-# 옵티마이저와 모델을 초기화합니다
-print("[INFO] compiling model...")
-opt = SGD(lr=INIT_LR, momentum=0.9)
-model.compile(loss="categorical_crossentropy", optimizer=opt,
- metrics=["accuracy"])
-
-# 네트워크를 학습합니다
-print("[INFO] training network...")
-H = model.fit_generator(
- aug.flow(trainX, trainY, batch_size=64 * G),
- validation_data=(testX, testY),
- steps_per_epoch=len(trainX) // (64 * G),
- epochs=NUM_EPOCHS,
- callbacks=callbacks, verbose=2)
-```
-
-위 코드 블록의 세 번째 행에서는
-확률적 경사 하강법(Stochastic Gradient Descent, SGD) 알고리즘을 정의합니다.
-
-그 후 모델의 옵티마이저(Optimizer)와 손실 함수의 인자로 SGD와 범주형 교차 엔트로피를 주어 컴파일 합니다.
-
-이제 우리는 모델을 학습시킬 준비가 되었습니다!
-
-학습을 시작하기 위해서는 `model.fit_generator` 함수를 필요한 인자들과 함께 호출해야 합니다.
-
-각 GPU에 대한 배치 크기를 64로 설정하기 위해 `batch_size=64 * G`로 지정합니다.
-
-학습은 전에 설정한 바와 같이 70 에폭동안 수행됩니다.
-
-학습이 진행되는 동안 CPU는 각 GPU에서 계산된 기울기들을 바탕으로 모델의 가중치를 업데이트 합니다.
-그 후 업데이트된 모델은 각 GPU에 다시 반영됩니다.
-
-이제 학습과 테스트 과정은 완료되었으니, 다음은 손실 및 정확도를 그래프로 나타내어
-학습 과정을 시각화할 차례입니다.
-
-```python
-# 학습의 중간과정에서의 결과들을 저장하있는 딕셔너리를 가져옵니다
-H = H.history
-
-# 학습 로스와 정확도를 그래프로 그려줍니다
-N = np.arange(0, len(H["loss"]))
-plt.style.use("ggplot")
-plt.figure()
-plt.plot(N, H["loss"], label="train_loss")
-plt.plot(N, H["val_loss"], label="test_loss")
-plt.plot(N, H["acc"], label="train_acc")
-plt.plot(N, H["val_acc"], label="test_acc")
-plt.title("MiniGoogLeNet on CIFAR-10")
-plt.xlabel("Epoch #")
-plt.ylabel("Loss/Accuracy")
-plt.legend()
-
-# 그래프를 디스크에 저장합니다
-plt.savefig(args["output"])
-plt.close()
-```
-
-위의 마지막 코드 블록은 `matplotlib`을 사용하여 학습과 테스트 데이터 세트에 대한
-손실 및 정확도를 그래프로 나타낸 후, 해당 플롯을 디스크에 저장하는 과정입니다.
-
-만약 학습 과정이 내부적으로 어떻게 작동하는지 자세히 알고 싶으시다면, 제 책
-[*Deep Learning for Computer Vision with Python*](https://www.pyimagesearch.com/deep-learning-computer-vision-python-book/)을
-참고해 보시는 것을 추천합니다.
-
-
-### 멀티 GPU 학습 결과
-
-이제 우리의 노력의 결과를 확인해볼 차례입니다.
-
-먼저 단일 GPU를 사용하여 기준을 구하는 과정입니다.
-
-```shell
-$ python train.py --output single_gpu.png
-[INFO] loading CIFAR-10 data...
-[INFO] training with 1 GPU...
-[INFO] compiling model...
-[INFO] training network...
-Epoch 1/70
- - 64s - loss: 1.4323 - acc: 0.4787 - val_loss: 1.1319 - val_acc: 0.5983
-Epoch 2/70
- - 63s - loss: 1.0279 - acc: 0.6361 - val_loss: 0.9844 - val_acc: 0.6472
-Epoch 3/70
- - 63s - loss: 0.8554 - acc: 0.6997 - val_loss: 1.5473 - val_acc: 0.5592
-...
-Epoch 68/70
- - 63s - loss: 0.0343 - acc: 0.9898 - val_loss: 0.3637 - val_acc: 0.9069
-Epoch 69/70
- - 63s - loss: 0.0348 - acc: 0.9898 - val_loss: 0.3593 - val_acc: 0.9080
-Epoch 70/70
- - 63s - loss: 0.0340 - acc: 0.9900 - val_loss: 0.3583 - val_acc: 0.9065
-Using TensorFlow backend.
-
-real 74m10.603s
-user 131m24.035s
-sys 11m52.143s
-```
-
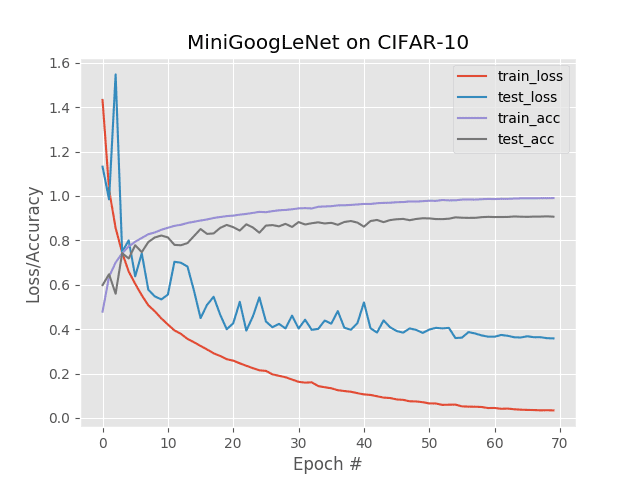
-
-
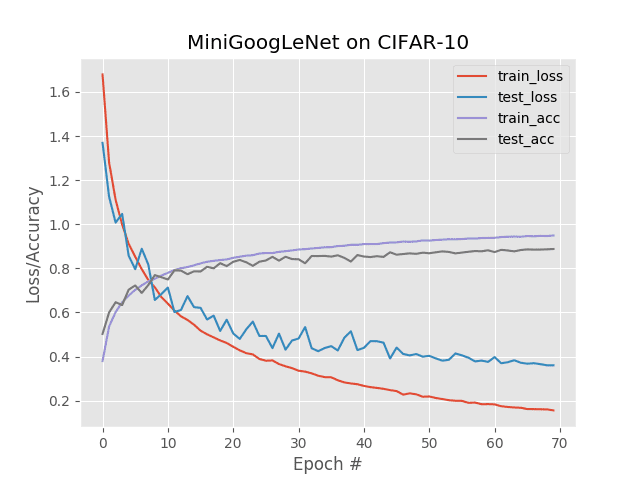
-**Figure 2**: 케라스로 단일 GPU로 MiniGoogLeNet 네트워크를 CIFAR-10 데이터 세트에 학습시킨 결과입니다.
-
-이 실험을 위해, 저는 먼저 제 NVIDIA DevBox에서 하나의 Titan X GPU를 사용해 학습을 진행하였습니다.
-매 에폭에는 63초 가량이 소요되었으며, 총 학습에는 74분 10초의 시간이 걸렸습니다.
-
-그 후 Titan X GPU 4개를 모두 사용하여 훈련을 진행해 보았습니다.
-
-```shell
-$ python train.py --output multi_gpu.png --gpus 4
-[INFO] loading CIFAR-10 data...
-[INFO] training with 4 GPUs...
-[INFO] compiling model...
-[INFO] training network...
-Epoch 1/70
- - 21s - loss: 1.6793 - acc: 0.3793 - val_loss: 1.3692 - val_acc: 0.5026
-Epoch 2/70
- - 16s - loss: 1.2814 - acc: 0.5356 - val_loss: 1.1252 - val_acc: 0.5998
-Epoch 3/70
- - 16s - loss: 1.1109 - acc: 0.6019 - val_loss: 1.0074 - val_acc: 0.6465
-...
-Epoch 68/70
- - 16s - loss: 0.1615 - acc: 0.9469 - val_loss: 0.3654 - val_acc: 0.8852
-Epoch 69/70
- - 16s - loss: 0.1605 - acc: 0.9466 - val_loss: 0.3604 - val_acc: 0.8863
-Epoch 70/70
- - 16s - loss: 0.1569 - acc: 0.9487 - val_loss: 0.3603 - val_acc: 0.8877
-Using TensorFlow backend.
-
-real 19m3.318s
-user 104m3.270s
-sys 7m48.890s
-```
-
-
-
-**Figure 3**: 케라스로 멀티 GPU로(4 Titan X GPUs) MiniGoogLeNet 네트워크를 CIFAR-10 데이터 세트에 학습시킨 결과입니다.
-모델의 성능은 유지하면서, 학습 시간은 75% 가량 단축되었습니다.
-
-4개의 GPU를 사용하여 매 에폭에 걸리는 학습 시간을 16초 가량으로 줄일 수 있었고,
-총 학습에는 19분 3초 밖에 소요되지 않았습니다.
-
-보시다시피, 케라스로 멀티 GPU 학습을 하는 것은 쉬울 뿐만 아니라, 효율적이기도 합니다!
-
-참고: 이 경우 단일 GPU를 사용해 학습한 모델의 정확도가 멀티 GPU를 사용한 경우보다 좋았습니다.
-이는 기계 학습의 확률적인 부분에 기인한 것으로, 만약 이러한 과정을 수백 번 반복하여 평균을 산출하면,
-거의 동일한 성능을 보일 것입니다.
-
-### 요약
-
-오늘 블로그 포스트에서는 케라스 기반의 심층 신경망을 훈련시키기 위해 여러 개의 GPU를 사용하는 방법을 배워봤습니다.
-
-여러 개의 GPU를 사용하면 선형에 가까운 시간 단축을 얻을 수 있습니다.
-
-이를 증명하기 위해, 우리는 MiniGoogLeNet을 CIFAR-10 데이터 세트에 대해 학습시켜 보았습니다.
-
-단일 GPU를 사용하여 학습을 진행한 경우, 매 에폭마다 63초, 총 74분 10초의 시간이 걸렸지만,
-멀티 GPU를 사용한 경우 전체 학습 시간을 19분 3초까지 줄일 수 있었습니다.
-
-함수를 한번 호출하는 것만으로 케라스에서 멀티 GPU 학습을 할 수 있기 때문에,
-저는 가능하다면 언제든지 여러 개의 GPU를 사용해 학습을 하시는 것을 추천합니다.
-저는 앞으로 `multi_gpu_model`이 학습에 사용될 GPU를 특정할 수 있는 수준까지 발전하여,
-결국 멀티 시스템 트레이닝까지 가능하게 할 것이라 생각합니다.
-
-### 딥러닝을 더 깊게 배워볼 준비가 되셨나요? 저만 따라오세요.
-
-만약 딥러닝을 더 배워보는 것(그리고 여러 GPU에서 최첨단 심층 신경망을 학습시키는 것)에 관심이 있으시다면, 제 새 책인
-[*Deep Learning for Computer Vision with Python*](https://www.pyimagesearch.com/deep-learning-computer-vision-python-book/)을
-살펴보시는 것을 추천합니다.
-
-여러분이 이제 막 딥러닝 공부를 시작하는 사람이든, 아니면 이미 노련한 딥러닝 종사자여도,
-제 새 책은 여러분이 전문가 수준에 도달할 수 있게 도와줄 것이라 확신합니다.
-
-> 이 글은 2018 컨트리뷰톤에서 Contribute to Keras 프로젝트로 진행했습니다.
-> Translator: [정연준](https://github.com/fuzzythecat)
-> Translator email : fuzzy0427@gmail.com
diff --git "a/48_OpenCV\353\245\274 \354\202\254\354\232\251\355\225\234 Neural Style Transfer.md" "b/48_OpenCV\353\245\274 \354\202\254\354\232\251\355\225\234 Neural Style Transfer.md"
deleted file mode 100644
index 25c7d65..0000000
--- "a/48_OpenCV\353\245\274 \354\202\254\354\232\251\355\225\234 Neural Style Transfer.md"
+++ /dev/null
@@ -1,685 +0,0 @@
-## OpenCV를 사용한 Neural Style Transfer(Neural Style Transfer with OpenCV)
-[원문 링크](https://www.pyimagesearch.com/2018/08/27/neural-style-transfer-with-opencv/)
-> 이 문서는 Keras와 OpenCV를 이용해 Neural Style Transfer 하는 방법을 보여줍니다. 많은 예제들이 content 이미지에 style 이미지의 style을 합치지만, 이 튜토리얼에서는 OpenCV를 사용해 이미지 뿐만 아니라 실시간으로 촬영되는 비디오에도 style 이미지의 style을 합칩니다.
-> 번역자의 부가설명은 `인용구`를 이용해 구분했습니다.
-
-* 케라스
-* Neural Style Transfer
-* Gram matrix
-
-
-
-
-
-
-### Introduction
-이 튜토리얼을 통해 OpenCV, 파이썬, 딥러닝을 이용해 Neural Style Transfer를 이미지 뿐만 아니라 실시간으로 촬영되는 비디오에 적용하는 방법을 익힐 수 있습니다. 튜토리얼이 끝날 때 쯤, 당신은 Neural Style Transfer를 이용해 아주 아름다운 작품을 만들 수 있을 겁니다.
-
-오리지널 Neural Style Transfer 알고리즘은 2015년에 Gatys와 몇몇에 의해 그들의 논문인 [`A Neural Algorithm of Artistic Style`](https://arxiv.org/abs/1508.06576) 소개되었습니다.
-
-2016 년에 Johnson과 몇몇이 실시간 [Perceptual Losses for Real-Time Style Transfer and Super-Resolution](https://cs.stanford.edu/people/jcjohns/eccv16/)(Style Trasfer 및 Super-Resolution를 위한 perceptual 손실)을 발표했는데, perceptual 손실을 사용해 Super-Resolution 문제를 Neural Style Transfer에 적용했습니다.
-그 결과, Gatys 등이 발표했던 Neural Style Transfer 알고리즘 방법보다 최대 3배 정도 빨랐습니다(그러나 몇 가지 단점이 있으며, 이 튜토리얼 후반부에 논의할 예정입니다).
-
-이 튜토리얼을 따라가다보면 마지막에 Neural Style Transfer 알고리즘을 당신의 이미지와 비디오 스트림에 어떻게 적용하는지 알 수 있을 것입니다.
-
-[Neural Style Transfer with OpenCV 데모 영상](https://youtu.be/DRpydtvjGdE)
-
-> 위 데모 영상은 이 튜토리얼에서 우리가 어떤 것을 배우게 되었는지에 대해 잘 보여주는 영상입니다. 한 번 보시는 것을 추천합니다!
-
-
-이 튜토리얼에서 OpenCV와 Python으로 Neural Style Transfer 알고리즘을 적용해 자신만의 예술 작품을 생성하는 방법을 시연합니다.
-
-여기서 논의하는 방법은 CPU를 활용하면 거의 실시간으로 실행할 수 있으며, GPU를 활용하면 완전히 실시간 성능을 얻을 수 있습니다.
-
-먼저, Neural Style Transfer이 무엇이고, 어떻게 작동하는지를 포함하는 간단한 설명을 시작하겠습니다.
-
-
Figure1: OpenCV를 사용한 Neural Style Transfer의 예. content 이미지 (왼쪽). Style 이미지 (중앙). 스타일화 된 결과(Stylized output) (오른쪽).
-
-
-
-Neural Style Transfer 프로세스:
-
-1. 어떤 이미지의 스타일을 가져온다.
-2. 그리고 그 스타일을 다른 이미지에 적용한다.
-
-Neural Style Transfer의 프로세스는 **Figure1**에서 확인할 수 있습니다. Figure1의 **왼쪽** 사진은 content 이미지입니다. 독일의 Black Forest 의 산 정상에서 맥주를 즐기고 있는 제 모습입니다.
-
-**중앙**에 위치한 사진은 스타일 이미지입니다. [빈센트 반 고흐](https://en.wikipedia.org/wiki/Vincent_van_Gogh)의 유명한 그림인 *별이 빛나는 밤*이죠.
-
-그리고 **오른쪽** 사진은 반 고흐의 별이 빛나는 밤의 스타일을 content 이미지에 적용한 결과입니다. 언덕, 숲, 사람, 그리고 심지어 맥주까지 어떻게 보존되었는지 살펴보세요. 모든 것을 유지하면서 별의 빛나는 밤의 스타일을 적용되었습니다. 마치 반 고흐가 그의 뛰어난 페인트 스트로크를 산 위의 경치에 바친 것 같습니다!
-
-그래서 질문은 흠.. 어떻게 뉴럴 네트워크(Neural Network)가 Neural Style Transfer를 수행하도록 정의할 수 있을까요?
-
-가능한 일이긴 한걸까요?
-
-물론 가능합니다! 바로 다음 섹션에서 어떻게 Neural Style Transfer가 가능한지 토론할 것입니다.
-
-
-
-### Neural Style Transfer는 어떻게 동작할까?
-
-
-
-Figure 2: Neural Style Transfer with OpenCV possible (Figure 1 of Gatys et al. 2015).
-
-
-
-이 시점에서 여러분은 아마 머리를 긁적이며 "우리가 어떻게 신경망을 정의해서 스타일 전달을 할 수 있을까?"라는 생각을 하고 있을 것입니다.
-
-> Gatys et al., Johnson et al. 은 해석하지 않고 바로 쓰겠습니다. Gatys 와 그 외 연구진들, Johnson 과 그 외 연구진들 이라는 뜻입니다.
-
-흥미롭게도, 2015년에 [Gatys et al. 이 작성한 논문](https://arxiv.org/abs/1508.06576)은 새로운 구조를 전혀 필요로 하지 않는 Neural Style Transfer 알고리즘을 제안했습니다! 대신 미리 학습된 네트워크( pre-trained network, 일반적으로 ImageNet)를 사용하고 스타일 전송의 최종 목표를 달성하기 위해 필요한 손실 함수를 정의합니다.
-
-
-**그러면 질문은 "어떤 뉴럴 네트워크를 우리가 써야할까" 가 아니라 "어떤 손실 함수를 우리가 써야할까?" 겠네요.**
-
-
-그에 대한 대답은 세가지 구성요소로 이야기할 수 있습니다.
-
-1. Content loss
-2. Style loss
-3. Total-variation loss
-
-
-
-각각의 구성요소는 개별적으로 계산이 된 후 한 개의 meta 손실 함수로 합쳐집니다. meta 손실 함수값을 최소화 시키기 위해서 우리는 content, style, total-variation 들의 손실을 최소화 시켜야 합니다.
-
-Gatys et al. 은 아름다운 결과를 만들어냈지만 문제는 그것이 꽤 느리다는 것이었습니다.
-
-Johnson et al. (2016)은 Gatys et al.의 연구를 기반으로 했고, 최대 3배 까지 빠른 Neural Style Transfer 알고리즘을 제안하였습니다. Johnson et al. 들의 방법은 perceptual loss 함수를 기반으로하는 super-resolution 문제로 Neural Style Transfer 를 프레임화합니다.
-
-Johnson et al. 들의 방법이 확실히 빠르지만 가장 큰 단점은 Gatys et al. 들의 방법에서와 같이 스타일 이미지를 임의로 선택할 수 없다는 것입니다.
-
-
-
-대신 먼저 원하는 이미지의 스타일을 재현하기 위해 네트워크를 명시적으로 학습해야 합니다. 네트워크가 학습이 되면 당신이 원하는 어떠한 content 이미지도 네트워크에 적용할 수 있습니다. 당신은 Johnson et al. 의 방법을 확인해봐야 합니다.
-
-Johnson et al. 들은 그들이 어떻게 Neural Style Transfer 모델을 학습시켰는지에 대한 문서를 그들의 [GitHub 페이지](https://github.com/jcjohnson/fast-neural-style)에서 제공합니다.
-
-마지막으로, 2017 년에 발표한 Ulyanov 외 연구진들의 논문인 [ Instance Normalization: The Missing Ingredient for Fast Stylization](https://arxiv.org/abs/1607.08022) 역시 주목할 가치가 있습니다. 배치 정규화를 instance normalization 으로 대체 함으로서(instance normalization 학습과 테스트 모두에 적용하였습니다.) 실시간으로 더욱 빠른 퍼포먼스와 이론적으로 더 만족스러운 결과를 이끌어 냈습니다.
-
-나는 Johnson et al. 이 사용한 두 가지 모델을 ECCV 논문에 Ulyanov 외 연구진들의 모델들과 함께 이 게시물의 "다운로드" 섹션에 포함시켰습니다.
-
-
-
-> 이 튜토리얼에서는 loss function 에 대한 이야기를 더 이상 하지 않습니다.
->
-> 그래서 코드와 함께 짧게 설명할까 합니다. [이곳](https://medium.com/tensorflow/neural-style-transfer-creating-art-with-deep-learning-using-tf-keras-and-eager-execution-7d541ac31398) 을 참고하였고, 이를 번역한 `Keras` Tutorial 의 문서 Neural Style Transfer : tf.keras와 eager execution를 이용한 딥러닝 미술 작품 만들기(Neural Style Transfer: Creating Art with Deep Learning using tf.keras and eager execution) 를 참고하시면 좋을 것 같습니다. 또한 code 는 Team-Keras 의 코드를 가져왔습니다. 그것은 [여기](https://github.com/keras-team/keras/blob/master/examples/neural_style_transfer.py)를 고해주세요.
->
-> `content loss` 는 아주 간단합니다. 미리 학습된 신경망(예를 들어, VGG19) 으로 부터 얻은, 우리가 바꾸고 싶은 입력 이미지 x 의 feature map 과 content 이미지 p 사이의 feature map 의 loss 를 구하는 것과 같습니다! 수식으로 표현하면 아래의 수식과 같습니다.
->
-> 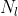 : 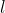 번 째 레이어의 filter 개수
-> 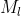 : filter 의 output 개수
-> 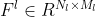 : 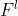 는 Feature map
-> 입력 이미지 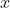, content 이미지 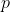 의 Feature map 을 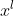, 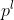 이라고 할 때 `content loss` 는 다음과 같습니다.
-> 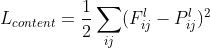
-> ```python
-> from keras import backend as K
->
-> def content_loss(base, combination):
-> return K.sum(K.square(combination - base))
-> ```
->
-> `style loss` 는 조금 더 어렵지만, content loss 와 같은 원리입니다. 이번에는 feature map에 대해 Gram matrix를 구하고, Gram matrix 간 차의 제곱을 loss 로 정의합니다. 그렇다면 아래와 같은 수식이 되겠죠? Gram matrix 는 같은 레이어의 서로 다른 filter 들의 correlation 입니다. filter 가  개 있으므로 Gram matrix 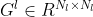 입니다.
->
-> 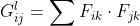
->
-> 따라서 Gram matrix 는 위와 같이 표현이 됩니다. `style loss` 는 레이어마다 계산한 후 weighted sum 을 합니다. 한 레이어의 style loss 는 아래와 같이 표현됩니다.
->
-> 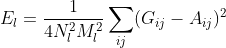
->
-> 전체 style loss 는 아래와 같이 표현됩니다.
-> 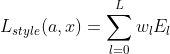
->
-> ```Python
-> def gram_matrix(x):
-> assert K.ndim(x) == 3
-> # image_data_format() 함수의 return 값은 'channels_first' 또는 'channels_last'
-> if K.image_data_format() == 'channels_first':
-> features = K.batch_flatten(x)
-> else:
-> features = K.batch_flatten(K.permute_dimensions(x, (2, 0, 1)))
-> # 필터들의 correlation 을 계산
-> gram = K.dot(features, K.transpose(features))
-> return gram
->
->
-> def style_loss(style, combination):
-> assert K.ndim(style) == 3
-> assert K.ndim(combination) == 3
-> # style 이미지의 Gram matrix
-> S = gram_matrix(style)
-> # 바꾸고 싶은 이미지의 Gram matrix
-> C = gram_matrix(combination)
-> channels = 3
-> size = img_nrows * img_ncols
-> # python 에서 ** 은 거듭제곱 연산으로 사용됩니다.
-> # 위에서 말한 E 표현
-> return K.sum(K.square(S - C)) / (4. * (channels ** 2) * (size ** 2))
-> ```
-> channels_first, channels_last 에 대한 이야기는 `keras` 문서 혹은 한글로는 [김태영님의 블로그](https://tykimos.github.io/2017/01/27/CNN_Layer_Talk/) 에 잘 설명되어 있습니다.
-
-
-
-
-### 프로젝트 구조
-
-프로젝트는 몇 개의 파일을 가지고 있는데, 이 프로젝트는 *"Downloads"* 섹션에서 다운로드 받을 수 있습니다.
-
-scripts + models + images 들을 다운로드 받은 후에 `tree` 커맨드를 입력하면 아래와 같은 디렉토리 및 파일 구조를 확인할 수 있습니다.
-
-```
-$ tree --dirsfirst
-.
-├── images
-│ ├── baden_baden.jpg
-│ ├── giraffe.jpg
-│ ├── jurassic_park.jpg
-│ └── messi.jpg
-├── models
-│ ├── eccv16
-│ │ ├── composition_vii.t7
-│ │ ├── la_muse.t7
-│ │ ├── starry_night.t7
-│ │ └── the_wave.t7
-│ └── instance_norm
-│ ├── candy.t7
-│ ├── feathers.t7
-│ ├── la_muse.t7
-│ ├── mosaic.t7
-│ ├── starry_night.t7
-│ ├── the_scream.t7
-│ └── udnie.t7
-├── neural_style_transfer.py
-├── neural_style_transfer_examine.py
-└── neural_style_transfer_video.py
-
-4 directories, 18 files
-```
-
-*"Downloads"* 섹션에서 .zip 파일을 다운받으면, 당신은 이 프로젝트를 위해서 온라인의 그 어떤곳에서 다른 것을 다운로드 받을 필요가 없습니다. 제가 test 에 도움이 될 이미지들을 `images/` 에, 모델들은 `models/` 에 준비를 해놓았습니다. 이 모델들은 Johnson 외 연구진들이 미리 학습시켜놓은 것입니다.
-당신은 또한 세개의 파이썬 스크립트를 찾을 수 있을 것입니다.
-
-
-
-
-### Neural Style Transfer 구현하기
-
-이제 `OpenCV`와 Python으로 Neural Style Transfer 를 구현해 보겠습니다.
-
-`neural_style_transfer.py` 파일을 열고, 아래의 코드를 넣어보세요.
-
-
-```python
-# 필요한 패키지들 import
-import argparse
-import imutils
-import time
-import cv2
-
-# argument parser 를 정의하고, argument 를 파싱합니다.
-ap = argparse.ArgumentParser()
-ap.add_argument("-m", "--model", required=True,
- help="neural style transfer model")
-ap.add_argument("-i", "--image", required=True,
- help="input image to apply neural style transfer to")
-args = vars(ap.parse_args())
-```
-
-첫 번째, 우리는 우리가 필요로하는 패키지들을 import 하고 커맨드 라인 arguement 를 파싱합니다.
-
-우리가 import 할 것은 아래와 같습니다.
-* [imutils](https://github.com/jrosebr1/imutils): 이 패키지는 `pip install --upgrade imutils` 로 설치가 가능합니다. 최근에 imutils==0.5.1 버전이 배포되었으니 업그레이드 하는 것을 잊지마세요!
-* [OpenCV](https://opencv.org): 이 튜토리얼을 위해서 OpenCV 3.4 또는 그 이상의 버전이 필요합니다. 제가 업로드한 또 다른 튜토리얼을 이용해서 [Ubuntu](https://www.pyimagesearch.com/2018/08/15/how-to-install-opencv-4-on-ubuntu/)와 [macOS](https://www.pyimagesearch.com/2018/08/17/install-opencv-4-on-macos/) 를 위한 `OpenCV4` 를 설치할 수도 있을 거에요.
-
-
-
-우리는 또한 두 줄의 커맨드 라인 arguments 가 필요합니다.
-* `--model` : Neural Style Transfer 모델의 path(위치) 입니다. 11 개의 미리 학습된 모델들이 *"Downloads"* 에 있습니다.
-* `--image` : 우리가 스타일을 적용할 입력 이미지입니다. 이미 4 개의 샘플 이미지를 준비해뒀습니다. 튜토리얼을 진행하는데 부담갖지 마세요!
-
-
-당신은 커맨드 라인 arguments 코드를 바꿀 필요가 없습니다. - arguments 는 실행시간동안 처리될 것 입니다. 만약 이런 방식이 익숙하지 않다면, [커맨드 라인 arguments + argparse](https://www.pyimagesearch.com/2018/03/12/python-argparse-command-line-arguments/) 에 대한 블로그 포스트를 한 번 읽어보세요.
-
-이제는 재미있는 파트입니다. - 우리는 우리의 이미지와 모델을 가져올 것이고, 그 다음엔 Neural Style Transfer 를 해볼 것입니다.
-
-
-
-```python
-# Neural Style Transfer model 로드 합니다.
-print("[INFO] loading style transfer model...")
-net = cv2.dnn.readNetFromTorch(args["model"])
-
-# 입력 image 를 로드하고, width of 600 pixels 로 사이즈를 버꿉니다.
-# then grab the image dimensions
-image = cv2.imread(args["image"])
-image = imutils.resize(image, width=600)
-(h, w) = image.shape[:2]
-
-# 이미지로부터 blob 처리를 하고, 뉴럴넷의 forward pass 를 진행합니다.
-blob = cv2.dnn.blobFromImage(image, 1.0, (w, h),
- (103.939, 116.779, 123.680), swapRB=False, crop=False)
-net.setInput(blob)
-start = time.time()
-output = net.forward()
-end = time.time()
-```
-
-이 코드 블록에서 우리는 아래 사항을 진행합니다 :
-
-* pre-trained(학습된) Neural Style Transfer 모델을 로드합니다.
-* `입력 이미지` 를 로드하고 사이즈를 바꿉니다.
-* mean subtraction 을 통해서 `blob` 구성을 수행합니다. [`cv2.dnn.blobFromImage`](https://www.pyimagesearch.com/2017/11/06/deep-learning-opencvs-blobfromimage-works/)를 읽어보세요. blob 이 무엇인지 이해하는데 도움이 될 것입니다.
-* forward pass 를 수행해서 결과 이미지를 얻습니다. (i.e. Neural Style Transfer 프로세스의 결과는 time.time() 사이에 있습니다. 결과를 얻는데까지의 시간 측정을 해보기 위해 time.time() 을 이용했습니다.)
-
-
-
-> 위의 설명에서 `blob` 이라는 것이 나옵니다. 원작자가 추천한 글을 읽으셔도 되고 제가 지금 간단히 설명할 이 글을 읽으셔도 됩니다. 원작자 설명은 영어입니다 :)
->
-> `OpenCV` 는 이미지처리를 위한 전처리 함수를 제공하는데, 전처리 함수는 다음과 같습니다.
-> * cv2.dnn.blobFromImage
-> * cv2.dnn.blobFromImages
->
-> 이 함수들이 하는 일은 총 세가지 입니다.
-> 1. Mean subtraction (평균 빼기)
-> 2. Scaling (이미지 사이즈 바꾸기)
-> 3. And optionally channel swapping (옵션, 이미지 채널 바꾸기)
->
-> 위의 과정들을 거치면 아래의 왼쪽 이미지는 오른쪽 이미지처럼 바뀔 것입니다.
->
->
->
-> Figure3 : Mean subtraction
->
->
->
-> Mean subtraction 을 산하기 위해서 입력 이미지로 사용할 이미지의 R(Red), G(Green), B(Blue) 채널의 평균값을 각각 구합니다.
-> 각 채널의 평균값을 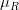 , 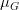 , 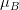 로 표현한다고 했을 때, 각각의 진짜 채널 값에서 평균 값을 뺍니다. 아래와 같이 표현할 수 있을 것입니다.
->
->
->
->
-> 그 다음에는 2 단계인 scaling 을 위해서 표준편차인 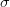 를 사용합니다.
->
->
->
-> 평균을 빼주고, 표준편차로 나눠줌으로써 데이터를 정규화시켜줍니다.
->
-> 모든 딥러닝 아키텍처들이 mean subtraction 및 scaling 을 수행하는 것은 아닙니다!
->
-
-
-
-
-다시 튜토리얼로 돌아와서, 지금까지 전처리를 하고 forward pass 를 실행하고 결과를 이미지를 얻었으니 다음으로 `출력 이미지` 를 후처리하는 것이 중요합니다.
-
-
-
-```Python
-# 결과 tensor 를 reshape 하고, mean subtraction 했던 만큼 더해줍니다.
-# 그리고 채널 순서를 바꿉니다.
-output = output.reshape((3, output.shape[2], output.shape[3]))
-output[0] += 103.939
-output[1] += 116.779
-output[2] += 123.680
-output /= 255.0
-output = output.transpose(1, 2, 0)
-```
-
-이 예제에서 쓰고 있는 특정한 이미지는, 결과로 나온 Numpy 배열의 shape `(1, 3, 452, 600)` 와 같습니다.
-
-* `1` 은 네트워크를 통해 하나의 배치 크기(즉, 단일 이미지)를 전달했음을 나타냅니다.
-* OpenCV 는 channels-first ordering 를 여기서 사용하고 있는데, 이는 `3 개`의 채널이 결과 이미지에 사용된다는 것과 같습니다.
-* output shape 의 마지막 두 개의 값들은 행 수(높이)와 열 수(너비)입니다.
-
-우리는 결과 매트릭스의 모양을 간단한 (3, H, W) 모양으로 바꿔주고, "de-process" 시킬 것입니다.:
-
-1. Mean subtraction 으로 뺀 평균값을 다시 더해주고
-2. Scaling 해주고
-3. channels-last ordering 할 수 있도록 매트릭스의 전치행렬로 바꿉니다.
-
-마지막 단계는 Neural Style Transfer 프로세스의 결과를 화면에 보여주는 것입니다.
-
-```Python
-# Neural Style Transfer 가 얼마나 걸렸는지 보여줍니다.
-print("[INFO] Neural Style Transfer took {:.4f} seconds".format(
- end - start))
-
-# 이미지를 보여줍니다.
-cv2.imshow("Input", image)
-cv2.imshow("Output", output)
-cv2.waitKey(0)
-```
-
-
-
-
-### Neural Style Transfer 결과들
-
-내 결과를 복사하려면 이 블로그 게시물에 대한 "다운로드"를 받아야 합니다.
-
-파일을 다운 받은 후 터미널을 열고 다음 명령을 실행합니다.
-아래와 같은 명령어로 content 이미지와 style 이미지에 대해서 결과를 얻을 수 있습니다.
-
-```
-$ python neural_style_transfer.py --image images/giraffe.jpg \
- --model models/eccv16/the_wave.t7
-[INFO] loading style transfer model...
-[INFO] neural style transfer took 0.3152 seconds
-```
-
-
-
-
-Figure4 : Result 1
-
-
-다른 이미지로 style transfer 된 결과 이미지를 얻고 싶다면 커맨드의 이미지 path와 와 모델 path 를 변경해 보세요.
-
-
-
-
-
-Figure5 : Result 2
-
-
-
-
-Figure6 : Result 3
-
-
-위의 세 개의 예제처럼, 우리는 딥러닝 예술작품을 만들었습니다! 터미널 출력에서 출력 이미지를 계산하는 데 경과된 시간이 표시됩니다. 각 CNN 모델은 약간 다르므로 각 모델에 대해 서로 다른 타이밍을 예상해야 합니다.
-
-도전! 신경 스타일의 전이가 있는 화려한 딥러닝 작품을 만들 수 있나요? 저는 당신이 작품을 트윗하는 것을 보고 싶습니다. 해시태그, #noralstyletransfer를 사용하여 트윗(@PyImageSearch)에서 저를 언급하세요. 또한, 아티스트와 사진작가가 트위터에 있다면 태그를 달아주세요.
-
-
-
-
-### 실시간 Neural Style Transfer
-
-이제 단일 영상에 신경 스타일 전송을 적용하는 방법을 배웠으니 실시간 비디오에도 이 프로세스를 적용하는 방법을 알아보겠습니다.
-
-이 과정은 정적 이미지에서 신경 스타일 전송을 수행하는 것과 매우 유사합니다.
-
-
-> 웹캠에서 한 프레임을 가져오는 것은 이미지 하나를 처리하는 것과 같기 때문입니다.
-
-
-
-이 스크립트에서는 다음을 수행합니다:
-
-* `model` 경로에서 사용 가능한 모든 신경 스타일 전송 모델을 순환시킬 수 있는 특별한 Python iterator 를 사용합니다.
-
-* 웹캠 비디오 스트림을 시작합니다. - 우리의 웹캠 프레임은 거의 실시간으로 처리될 것 입니다. 속도가 느린 시스템은 특정 대형 모델에서는 상당히 지연될 수 있습니다.
-* 프레임 위로 반복합니다.
-* 프레임에서 신경 스타일 전송을 수행하고 출력을 후 처리한 후 화면에 결과를 표시합니다(위에서와 거의 동일하므로 이를 인식할 수 있음).
-* 사용자가 키보드의 "n" 키를 누르면 스크립트를 중지/재시작하지 않고도 iterator 를 사용하여 다음 신경 스타일 전달 모델로 순환합니다.
-
-일단 시작해봅시다!
-
-`neural_style_transfer_video.py` 를 열고 다음 코드를 삽입하세요.
-
-
-```python
-# 필요한 패키지들 import
-from imutils.video import VideoStream
-from imutils import paths
-import itertools
-import argparse
-import imutils
-import time
-import cv2
-
-# argument parser 를 정의하고, argument 를 파싱합니다.
-ap = argparse.ArgumentParser()
-ap.add_argument("-m", "--models", required=True,
- help="path to directory containing neural style transfer models")
-args = vars(ap.parse_args())
-```
-
-
-먼저 필요한 패키지/모듈을 가져옵니다.
-
-We begin by importing required packages/modules.
-
-여기서는 `model` 디렉토리의 경로만 필요합니다(이미 "다운로드" 에는 일부 모델이 포함되어 있습니다). 명령어의 인수인 `--models` 를 argparse 와 결합하면 런타임에 path를 통과할 수 있습니다.
-
-다음은, 모델 path iterator 를 만들어 봅시다:
-
-
-```Python
-# 모든 neurl style transfer 모델이 들어있는 model 디렉토리의 path 를 설정하세요.
-# 디렉토리에 있는 모든 모델은 '.t7' file 확장자입니다.
-modelPaths = paths.list_files(args["models"], validExts=(".t7",))
-modelPaths = sorted(list(modelPaths))
-
-# 각 모델 path 에 대한 고유한 ID 들을 만드세요. 그리고 두 개의 리스트를 합치세요.
-models = list(zip(range(0, len(modelPaths)), (modelPaths)))
-
-# 모든 모델에 대해서 순환을 할 수 있도록 itertools 순환(반복)을 하는 함수를 사용할 거에요. 그리고 마지막까지 다 돌았을 때 다시 시작하게 해줍니다.
-modelIter = itertools.cycle(models)
-(modelID, modelPath) = next(modelIter)
-```
-
-
-위의 코드 블록을 보면 중간 반복문에서 프레임을 처리하기 시작하면, "n" 키를 눌렀을 때 iterator 에 "다음" 모델이 로드됩니다. 이렇게 하면 스크립트를 중지하고 모델 경로를 변경한 다음 다시 시작하지 않고도 비디오 스트림에서 각 neural style 의 효과를 볼 수 있습니다.
-
-모델 iterator 를 구성하기 위해 다음과 같은 작업을 수행합니다 :
-
-* 모든 Neural Style Transfer 모델의 경로를 정렬합니다.
-* 고유 ID를 할당합니다.
-* `Itertools` 의 `cycle` 을 사용하여 iterator를 만듭니다. 기본적으로 `cycle` 은 순환 리스트 만들 수 있게 해줍니다. 이 리스트는 끝 부분에 도달하면 처음부터 다시 시작됩니다.
-* `next` 함수로 `modelIter` 의 다음 `modelID` 와 `modelPath` 를 가져옵니다.
-
-만약 당신이 Python iterators 또는 반복문(대부분의 프로그래밍 언어가 이를 구현함)을 처음 접하는 경우 [RealPython](https://realpython.com/python-itertools/)의 기사를 반드시 읽어 보십시오.
-
-이제 Neural Style Transfer 모델을 로드하고 비디오 스트림을 초기화 합시다!:
-
-
-
-```Python
-# Neural Style Transfer 모델을 로드합니다.
-print("[INFO] loading style transfer model...")
-net = cv2.dnn.readNetFromTorch(modelPath)
-
-# 비디오 스트림을 초기화하고, 카메라 센서를가시작하도록 설정합니다.
-print("[INFO] starting video stream...")
-vs = VideoStream(src=0).start()
-time.sleep(2.0)
-print("[INFO] {}. {}".format(modelID + 1, modelPath))
-```
-
-
-위의 코드 블록에서는 우리는 우리의 첫 번째 Neural Style Transfer 모델의 경로를 이용해서 모델을 사용합니다.
-
-그 다음, 웹캠으로 영상을 촬영할 수 있도록 비디오 스트림을 초기화합니다.
-
-
-
-프레임 반복을 하는 과정을 구현해 봅시다:
-
-```Python
-while True:
- # 비디오 스트림에 있는 한 개의 프레임을 가져옵니다.
- frame = vs.read()
-
- # 프레임의 사이즈를 가로 600 픽셀로 바꿉니다.
- # then grab the image dimensions
- frame = imutils.resize(frame, width=600)
- orig = frame.copy()
- (h, w) = frame.shape[:2]
-
- # 이미지로부터 blob 처리를 하고, 뉴럴넷의 forward pass 를 진행합니다.
- blob = cv2.dnn.blobFromImage(frame, 1.0, (w, h),
- (103.939, 116.779, 123.680), swapRB=False, crop=False)
- net.setInput(blob)
- output = net.forward()
-```
-
-
-
-우리는 `while` 을 이용해서 반복문을 사용할 것입니다.
-
-코드 블록은 우리가 검토한 이전 스크립트와 거의 비슷합니다. 유일한 차이는 이미지 파일이 아니라 비디오 스트림에서 프레임을 로드한다는 것입니다.
-
-본질적으로 우리는 `프레임` 을 로드해서 `blob` 처리를 하고, CNN 의 입력으로 사용합니다. 위에서 설명한 이 과정에 대해서 읽지 않았다면, 꼭 읽고 오세요.
-
-입력 이미지에 대해 CNN에서는 많은 연산이 이루어집니다. 케라스로 Neural Style Transfer 모델을 어떻게 훈련시키는지 궁금하다면, 제 책 ["Deep Learning for Computer Vision with Python"](https://www.pyimagesearch.com/deep-learning-computer-vision-python-book/)을 참고하세요.
-
-그런 다음 `결과 이미지` 를 후처리하고 표시합니다.
-
-
-```Python
- # 결과 tensor 를 reshape 하고, mean subtraction 했던 만큼 더해줍니다.
- # 그리고 채널 순서를 바꿉니다.
- output = output.reshape((3, output.shape[2], output.shape[3]))
- output[0] += 103.939
- output[1] += 116.779
- output[2] += 123.680
- output /= 255.0
- output = output.transpose(1, 2, 0)
-
- # Neural Style Transfer 의 결과를 보여줍니다.
- cv2.imshow("Input", frame)
- cv2.imshow("Output", output)
- key = cv2.waitKey(1) & 0xFF
-```
-
-
-정적 이미지 신경 스타일 스크립트와 동일합니다. 우리의 출력 이미지는 reshape, 평균 추가(평균을 이전에 뺀 이후)를 통해 "de-processed"됩니다.
-
-원래의 프레임과 가공된 프레임이 모두 화면에 표시됩니다.
-
-
-```Python
- # "다음" 이라는 의미의 `n` 키가 눌리면, 다음 Neural Style Transfer 모델을 가져옵니다.
- if key == ord("n"):
- (modelID, modelPath) = next(modelIter)
- print("[INFO] {}. {}".format(modelID + 1, modelPath))
- net = cv2.dnn.readNetFromTorch(modelPath)
-
- # `q` 키를 누르면 반복문이 종료됩니다.
- elif key == ord("q"):
- break
-
-# 정리 코드
-cv2.destroyAllWindows()
-vs.stop()
-```
-
-
-스크립트가 실행되는 동안 다른 동작을 유발하는 두 가지 키가 있습니다.
-
-"n": "다음" 신경 스타일 전달 모델 경로 + ID를 가져와서 로드합니다. 마지막 모델에 도달한 경우, iterator는 처음부터 다시 순환합니다.
-"q": "q" 키를 누르면 `while` 루프(라인 83 및 84)가 "종료"됩니다.
-
-
-
-
-### 실시간 Neural style transfer 의 결과
-
-이 튜토리얼의 *"다운로드"* 섹션을 사용하여 소스 코드와 신경 스타일 전송 모델을 다운로드했으면 다음 명령을 실행하여 당신의 비디오 스트림에 Neural Style Transfer 를 적용할 수 있습니다.
-
-
-
-
-
-보시는 바와 같이, 한 번의 키 누름 버튼을 사용하여 Neural Style Transfer 모델을 순환(반복)하기 쉽습니다.
-
-
-
-
-### Neural Style Transfer 에 대해 조금 더 알아보기
-["Deep Learning for Computer Vision with Python"](https://www.pyimagesearch.com/deep-learning-computer-vision-python-book/) 을 참조하세요.
-
-
-
-
-### Summary
-오늘 블로그 게시물에서 `OpenCV`, Python 을 사용하여 이미지와 비디오 모두에 Neural Style Transfer 를 적용하는 방법을 배웠습니다.
-
-특히, 우리는 2016년 Johnson et al. 이 발표한 논문의 모델을 활용하였습니다. 당신의 편의를 위해, 저는 이 블로그 포스트의 *"다운로드"* 섹션에 모델을 포함시켰습니다.
-
-오늘 소개한 Neural Style Transfer 에 관한 튜토리얼 즐거우셨기를 바랍니다!
-
-트위터와 코멘트 섹션을 사용하여 여러분만의 아름다운 예술작품에 대한 링크를 게시해주세요.
-
-
-
-> Neural Style Transfer 를 실행해보았습니다.
-> style 이미지의 스타일 뿐만 아니라 content 이미지의 윤곽을 굉장히 잘 살려주는 모델이라고 느껴집니다.
->
->
-> 아래 3 장의 스타일 이미지를 사용하였습니다.
->
스타일 이미지
->
-> >
-> >
-> >
-> >
-> >
->
->
->
콘텐트 이미지
->
-> >
->
->
->
->
결과 이미지 : spiderman with wave
->
-> >
->
->
->
->
결과 이미지 : spiderman with starry night
->
-> >
->
->
->
->
결과 이미지 : spiderman with composition_vii
->
-> >
->
-> 스파이더맨의 수트의 선 뿐만 아니라 배경의 모양 윤곽도 잘 살렸습니다.
->
-> 그래서 제 Github 프로필 사진으로도 시도해 보았습니다.
->
->
콘텐트 이미지 : my pic of inside the lift
->
-> >
->
->
결과 이미지 : my pic with starry night
->
-> >
->
->
->
결과 이미지 : my pic with composition_vii
->
-> >
->
-> 입력 이미지를 보면 사진이 셀피이기 때문에 거울에 비친 뒷모습이 있고, 체크무늬 셔츠를 입은것을 볼 수 있는데 결과 이미지를 봤을 때도 거울에 비친 모습과 체크무늬 셔츠가 아주 선명하게 style transfer 되서 나타난 것을 볼 수 있습니다!
-
-### 참고 사이트
-* [케라스 공식 홈페이지](https://keras.io/)
-* [김태영의 케라스 블로그](https://tykimos.github.io/)
-* [Neural Style Transfer: Creating Art with Deep Learning using tf.keras and eager execution](https://medium.com/tensorflow/neural-style-transfer-creating-art-with-deep-learning-using-tf-keras-and-eager-execution-7d541ac31398)
-* [Image Style Transfer Using Convolutional Neural Networks](https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Gatys_Image_Style_Transfer_CVPR_2016_paper.pdf)
-
-> 이 글은 2018 컨트리뷰톤에서 [`Contribute to Keras`](https://github.com/KerasKorea/KEKOxTutorial) 프로젝트로 진행했습니다.
-> Translator: [박정현](https://github.com/parkjh688)
-> Translator email :

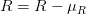 ->
-> 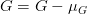
->
->
->
-> 
->
->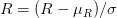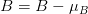 ->
-> 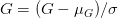
->
-> 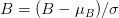
->
-> 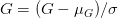
->
->